Pay attention to the official account : [ Xiao Zhang Python ], I have prepared 50+ Python fine e-books and 50G+ high-quality video learning materials for you, back-end reply keyword: 1024 can be obtained; if you have any questions about the content of the blog post, add the author in the back-end [Personal WeChat], you can communicate directly with the author
Hello everyone, I am zeroing~
Today, I will introduce how to use Python to crawl Jingdong products. The data contains information such as product titles and prices.

The core library used in this crawler is Selenium + pyquery, Selenium is used to drive the browser to simulate access to the web page, and pyquery is used to parse the page information for data extraction. Let’s take a look at the final result.
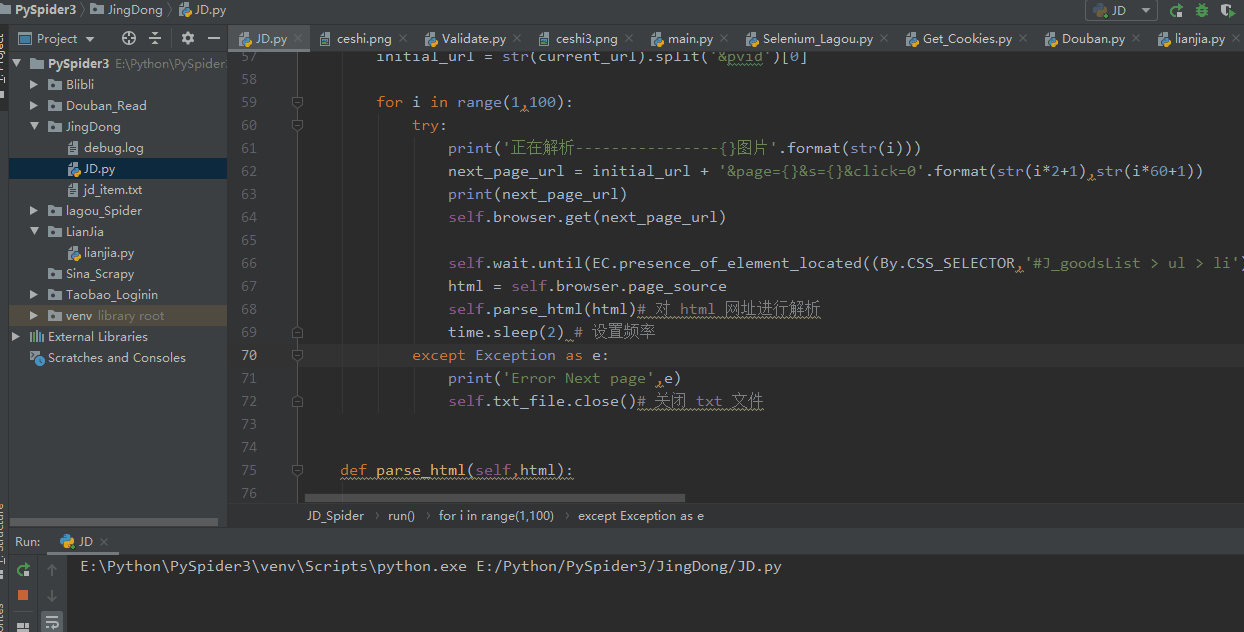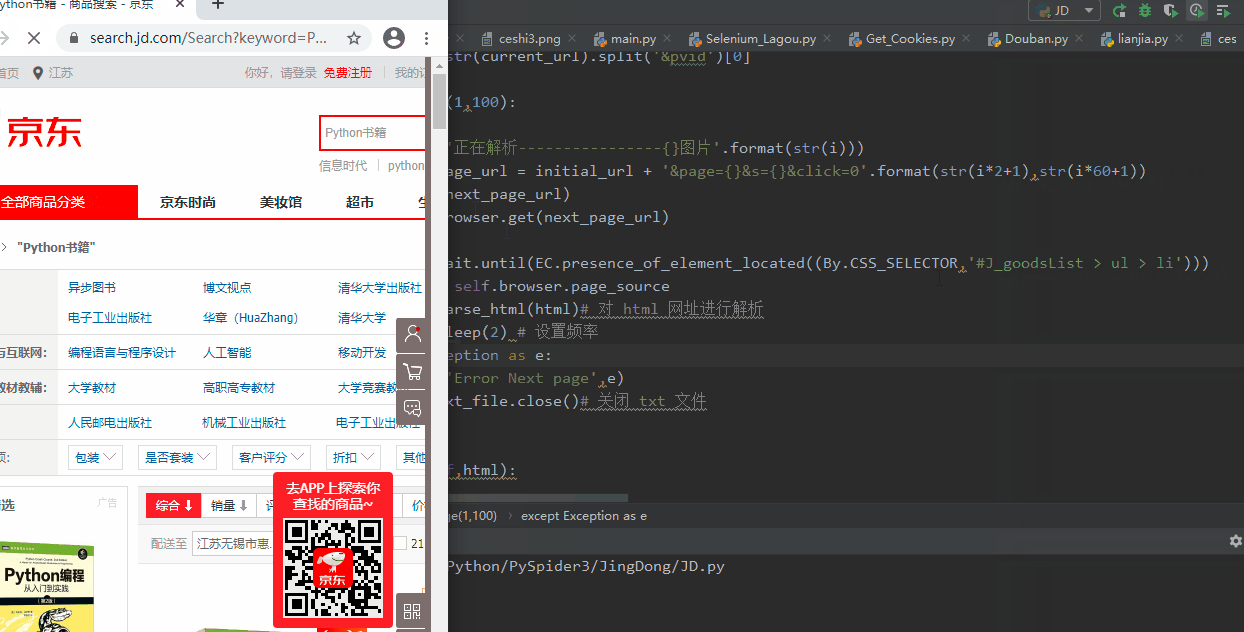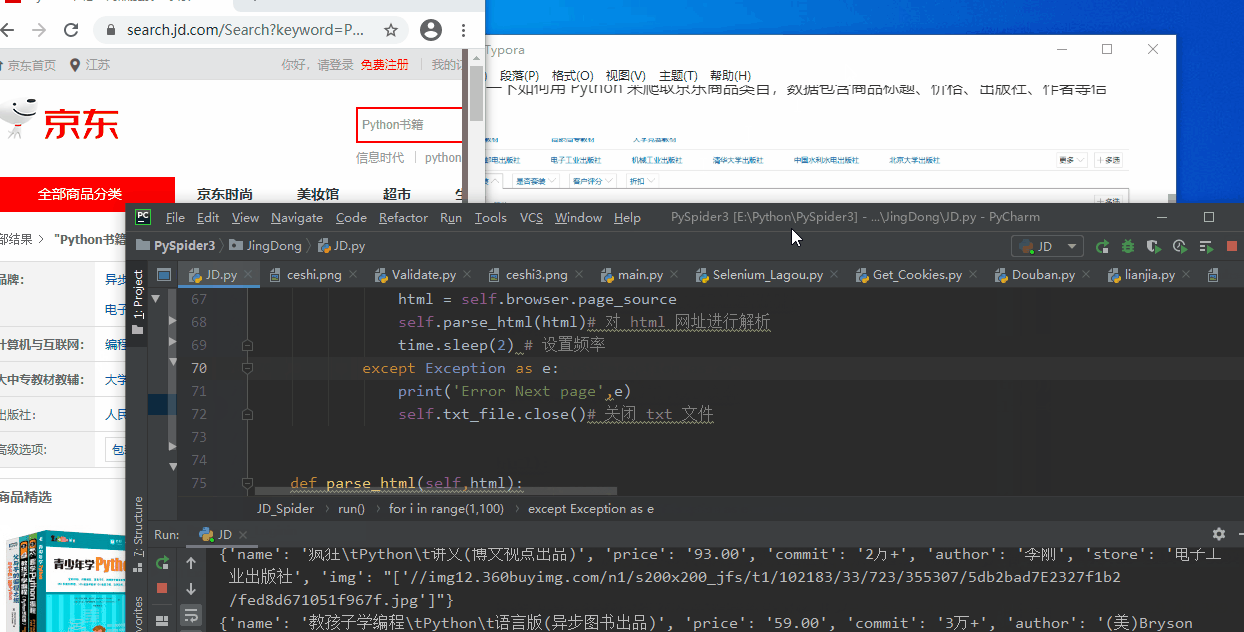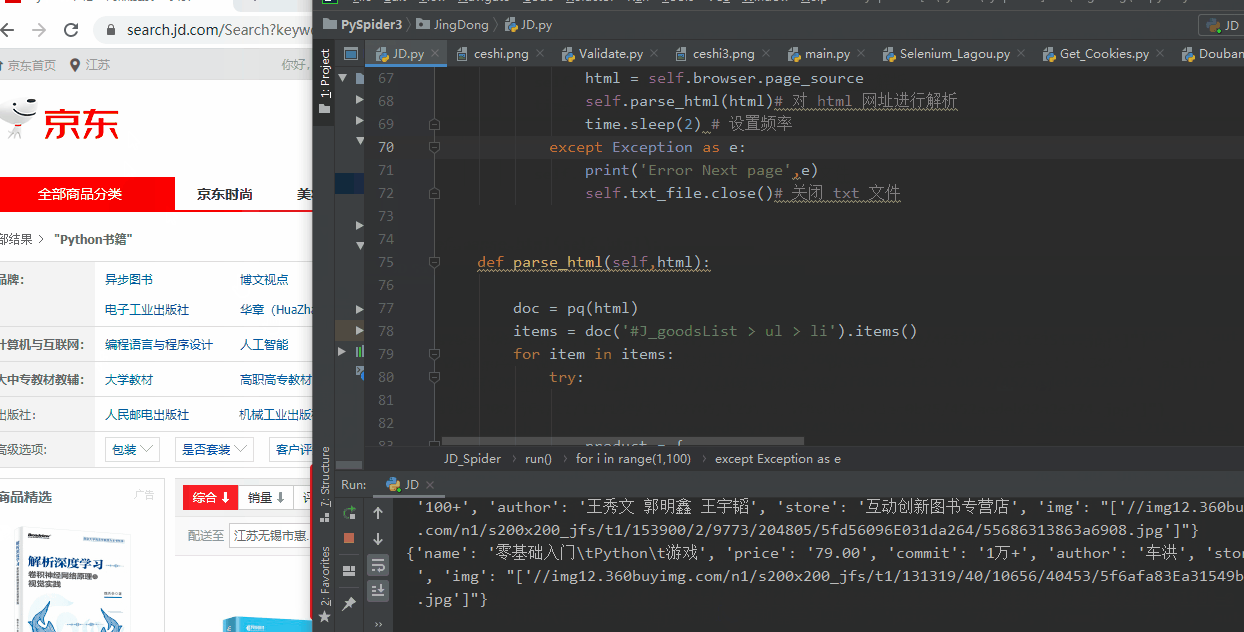 After the script is started, Selenium automatically opens the JD.com web page to turn the product page information. When the browser turns the page, it controls the background to return the extracted data.
After the script is started, Selenium automatically opens the JD.com web page to turn the product page information. When the browser turns the page, it controls the background to return the extracted data.
Before introducing the main program, here is an introduction to the Selenium package
Selenium installation
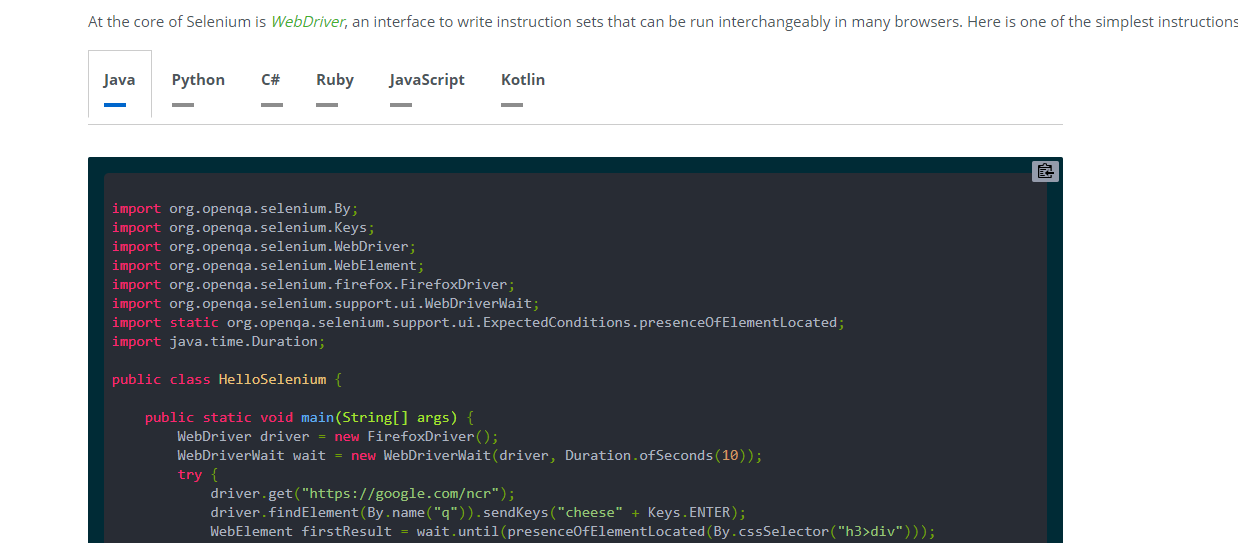
Selenium is mainly used as a testing tool for Web applications. It can control the browser to complete a series of steps and simulate human operations; for example 自动填写文本, it 网页端查询快递单号is all right. Currently, it supports multiple languages such as Java, Python, C#, Ruby, etc.;
When doing web page crawling, the data of some web pages is rendered in Ajax mode, such as Weibo. The headline has no next page entry. The page turning effect is achieved by refreshing the page; this type of web page data is not directly placed in html. It is to trigger the js command embedded in html through user operation to call the data stored in the json file and finally present it;
For this type of web page collection, there are generally two ways of thinking:
- 1. Use the developer tools to find the hidden link to store json data, and then use the conventional Request method to extract the data;
- 2. Use Selenium tools to simulate human operations to achieve data capture;
Therefore, the Selenium tool can achieve some effective suppression of some anti-climbing measures on the web side;
When Python uses Selenium, you can use the packaged Selenium library, and use the pip command to complete the installation.
pip install selenium
The browsers currently supported by Selenium include Chrome and Firefox. I suggest that you choose Chrome to be better, because there are relatively more documents about Chrome on the Internet.
But before use, in addition to ensuring that the Chrome browser is installed, you also need to ensure that the chromedriver.exe tool (the core of Selenium is webdriver, and chromedriver.exe is Chrome’s WebDriver tool) is also installed
The version of chromedriver needs to correspond to the version of the Chrome browser, and you can download it locally
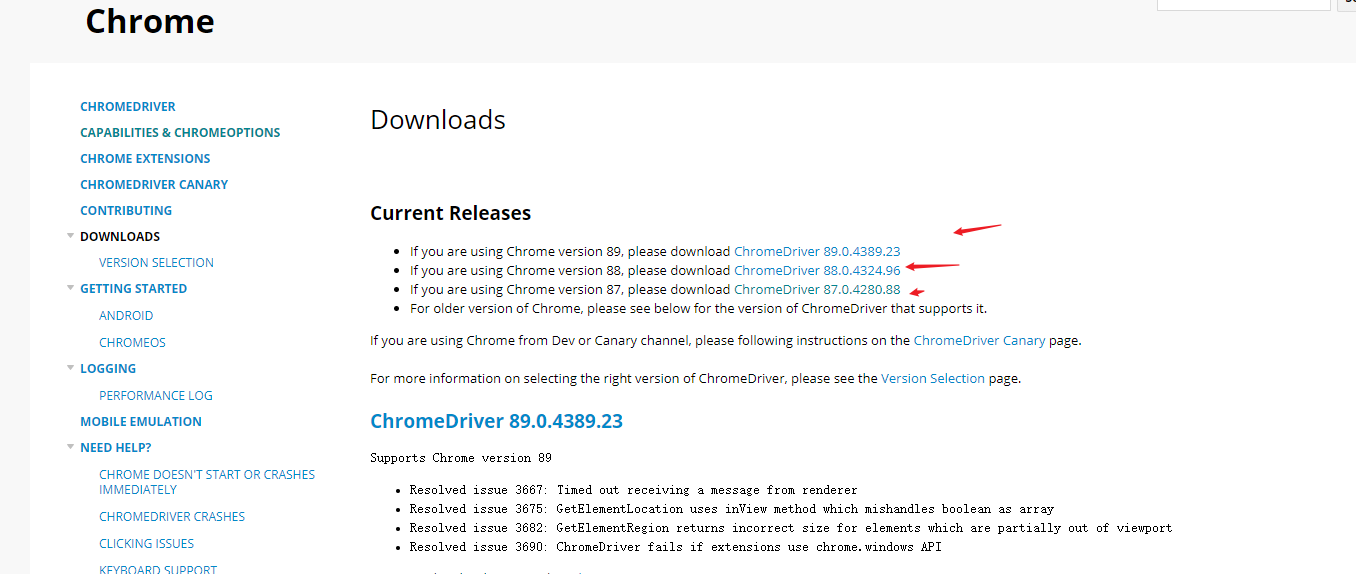
The download address is as follows: https://chromedriver.chromium.org/downloads
2. Crawler logic
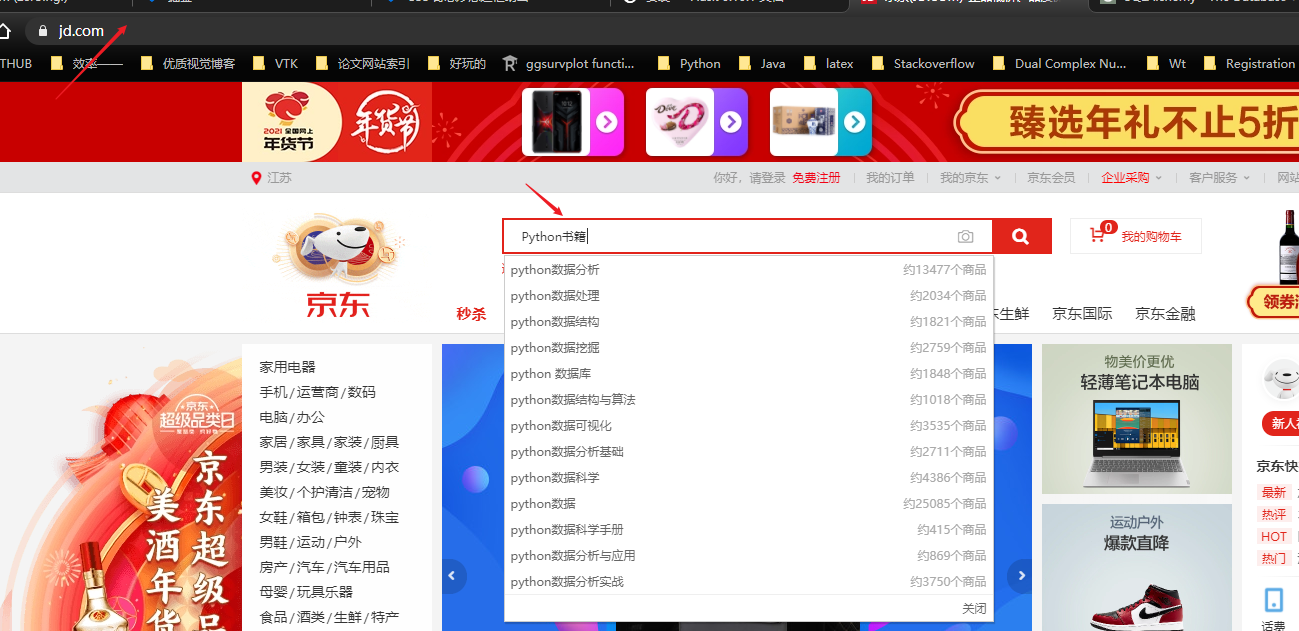
Use Selenium to simulate human operations to capture Jingdong data. It is important to perform the following steps in sequence (here, grab the Python book product as an example):
- 1. Drive the browser and open the JD website;
- 2. Find the search box, empty it and fill in the keyword Python books , and then click the search button next to it;
- 3. Go to the product page to capture the data, then drive the Selenium tool to complete the page turning operation, and capture all the data in turn;
First, it needs to be initialized to create the Chrome browser of the webdriver and the data storage file (here I use the txt file)
def __init__(self,item_name,txt_path):
url = 'https://www.jd.com/' # 登录网址
self.url = url
self.item_name = item_name
self.txt_file = open(txt_path,encoding='utf-8',mode='w+')
options = webdriver.ChromeOptions() # 谷歌选项
# 设置为开发者模式,避免被识别
options.add_experimental_option('excludeSwitches',
['enable-automation'])
self.browser = webdriver.Chrome(executable_path= "C:/Program Files/Google/Chrome/Application/chromedriver.exe",
options = options)
self.wait = WebDriverWait(self.browser,2)
The webdriver.Chrome() method is used to create a driven browser Chrome, and assign the path of the chromedriver.exe folder previously downloaded to the local to the executable_path parameter .
When the browser opens the webpage, it may be slow to load due to the network speed, so here we use the WebDriverWait method to create a wait method, each time the browser is called, it needs to wait for 2 seconds before proceeding to the next step;
After the initialization operation, the next step is the main program to perform analog access, input, click and other operations; I encapsulated all this part of the operation into a run() function,
def run(self):
"""登陆接口"""
self.browser.get(self.url)
input_edit = self.browser.find_element(By.CSS_SELECTOR,'#key')
input_edit.clear()
input_edit.send_keys(self.item_name)
search_button = self.browser.find_element(By.CSS_SELECTOR,'#search > div > div.form > button')
search_button.click()# 点击
time.sleep(2)
html = self.browser.page_source # 获取 html
self.parse_html(html)
current_url = self.browser.current_url # 获取当前页面 url
initial_url = str(current_url).split('&pvid')[0]
for i in range(1,100):
try:
print('正在解析----------------{}图片'.format(str(i)))
next_page_url = initial_url + '&page={}&s={}&click=0'.format(str(i*2+1),str(i*60+1))
print(next_page_url)
self.browser.get(next_page_url)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#J_goodsList > ul > li')))
html = self.browser.page_source
self.parse_html(html)# 对 html 网址进行解析
time.sleep(2) # 设置频率
except Exception as e:
print('Error Next page',e)
self.txt_file.close()# 关闭 txt 文件
First () method to access with Jingdong get the main page, then navigate to the search bar and search button labels page input_edit, ; search_buttonyou finish typing, click operation
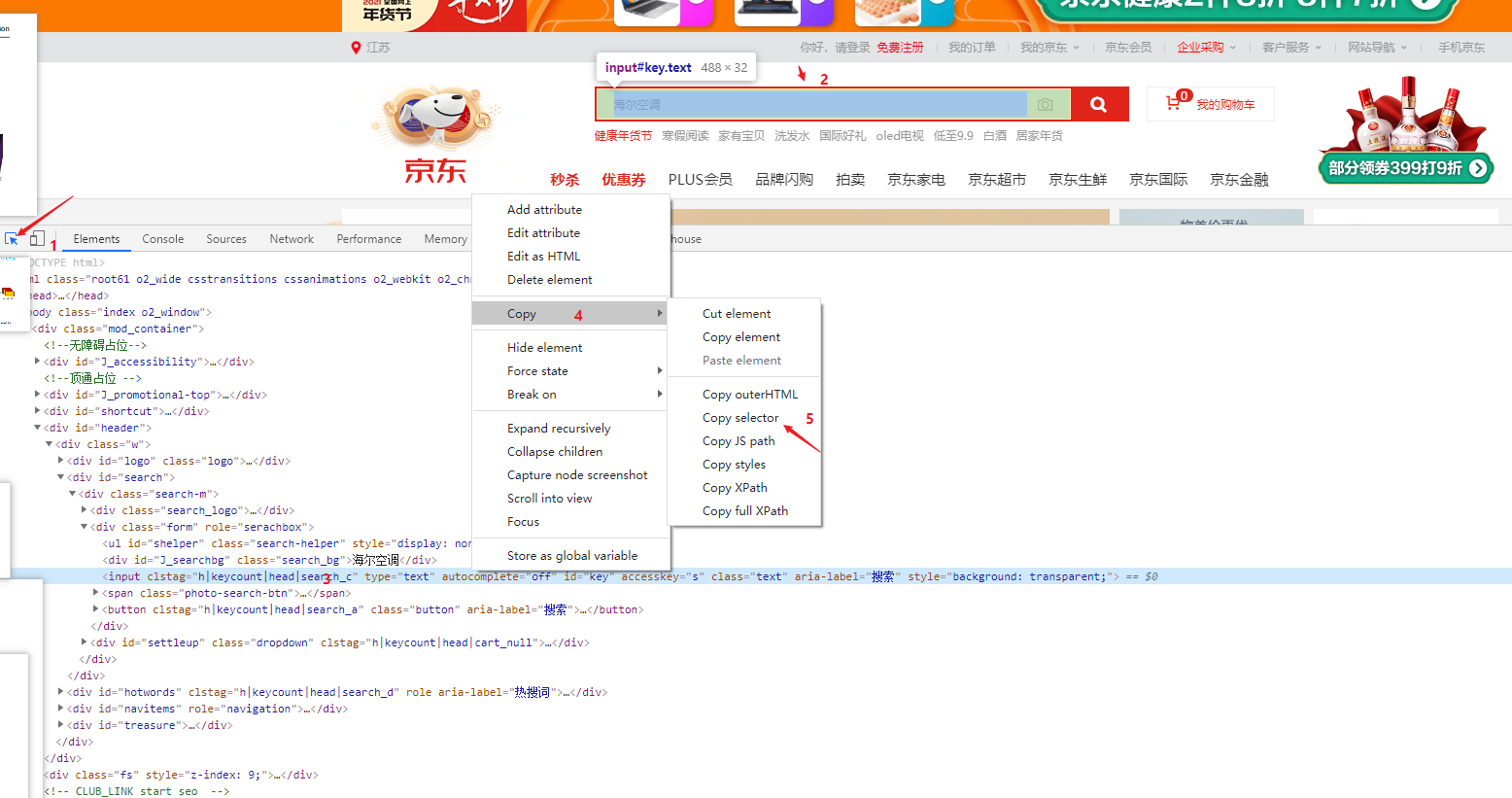
Regarding the positioning of web page element tags, if you can’t, you can use the browser developer mode to divide it into the following steps (here, CSS_Selector is taken as an example):
- 1. Click the pick element button in the upper left corner of the developer mode;
- 2. Use the mouse to click on the element you want to select;
- 3. In the html source code selection area, right-click and select Copy
- 4. Select the Copy Selector option;
- 5. Paste it on the pasteboard;
In the page turning operation, here is constructed according to the Jingdong url rule,
Page 5
https://search.jd.com/Search?keyword=%E4%BB%A3%E6%A3%AE%E9%93%B5&qrst=1&suggest=7.def.0.base&wq=%E4%BB%A3%E6%A3%AE%E9%93%B5&stock=1&page=9&s=241&click=0
Page 6
https://search.jd.com/Search?keyword=%E4%BB%A3%E6%A3%AE%E9%93%B5&qrst=1&suggest=7.def.0.base&wq=%E4%BB%A3%E6%A3%AE%E9%93%B5&stock=1&page=11&s=301&click=0
A closer look, then find here page 5 and page 6 url only difference is one of the two parameters pageand s;
-
pageDifference between 2; -
sThere is a difference of 60;
According to this rule, by changing the page and s parameters to construct the product information of the first 100 pages of Jingdong products to complete the data capture;
About data extraction part, I use parse_htmlthe function to complete
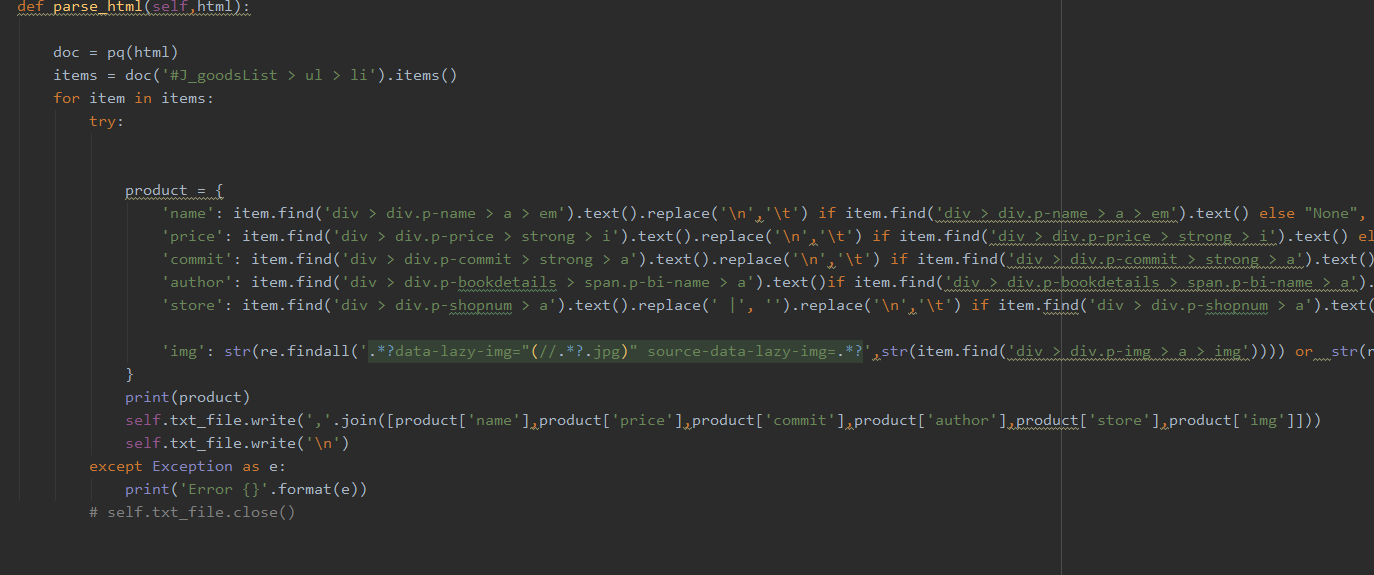
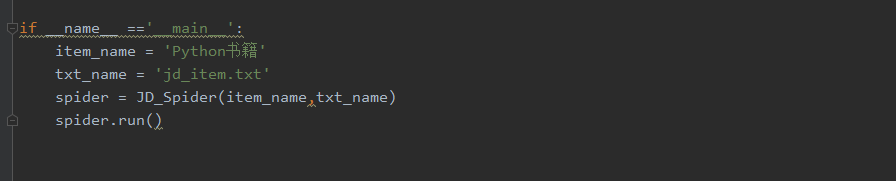
In order to improve the friendliness of the program, I encapsulated all the functions into a class, the user only needs to enter two parameters, one is the name of the product to be collected, and the other is the path of the storage file; data crawling can be completed ;
Finally save the crawled data into a txt file, the results are as follows

4. Summary
Although selenium can effectively crack some anti-crawling mechanisms on the web side, it is useless for some websites, such as Lagou. When you use Selenium to drive the browser to simulate page turning operations on Lagou's official website, the website can identify non- Manual operation, ban and warn the IP;
For the complete source code involved in this article, follow the WeChat public account: Xiao Zhang Python , and reply to the background keyword: Jingdong Commodities, you can get it!
Okay, the above is the entire content of this article. Finally, thank you all for reading!