1. Convolutional layer, activation layer, pooling layer
In-depth study of the meaning of convolutional and pooling layers in convolutional neural networks
1. Activation layer
The so-called activation is actually a nonlinear mapping of the output result of the convolutional layer. The activation function can introduce non-linear factors to solve problems that cannot be solved by the linear model. [Deep learning] Detailed explanation of the role of excitation function in artificial neural networks

As can be seen from the above figure, the input information x is first weighted and summed in the neuron, and then the data is controlled within a certain range through the nonlinear conversion of the activation function. The result of the conversion is used as the input of the next layer of neurons, or output as the result.
Common activation functions: sigmoid function, tanh function, ReLu function, SoftMax function, dropout function, etc.
2. Pooling layer
The so-called pooling (under-sampling or down-sampling) is mainly used for feature dimensionality reduction, compressing the number of data and parameters, and reducing overfitting
2. Fully connected layer
What is the role of the fully connected layer? -Wei Xiushen's answer-Knowing
Introduction to CNN: What is a fully connected layer?-Jiang Zhubo's article-Knowing
1. After several times 卷积+激活+池化before, finally came to the fully connected layer (fully connected layers, FC)
In fact, before the fully connected layer, if the number of neurons is too large and the learning ability is strong, overfitting may occur.
Therefore, the dropout operation can be introduced to randomly delete some neurons in the neural network to solve this problem.
2. Fully connected layer, which acts as a "classifier" in the entire convolutional neural network.
3. If operations such as the convolutional layer, pooling layer, and activation function layer map the original data to the hidden layer feature space ,
The fully connected layer plays the role of mapping the learned "distributed feature representation" to the sample label space .
Third, the output layer
1. The last layer is fully connected + Softmax




2. Linear layer: understanding of torch.nn.Linear() function
class torch.nn.Linear(in_features,out_features,bias = True )
The corresponding linear transformation formula is as follows: where A is the weight matrix
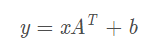
Parameter::
in_featuresthe size of each input sample
out_features: the size of each output sample
bias: if set to False, the layer will not learn additional deviations. Default value: True
Shape::
Input(N,in_features)
Output: (N,out_features)
weight: (out_features, in_features)
bias: (out_features,1)
Example:
m = nn.Linear(20, 30)
input = autograd.Variable(torch.randn(128, 20))
output = m(input)
print(output.size())
In this in_features=20case, , out_features=30, N=128,
Thus x(128,20); ; weight(30,20), bias(30,1)so that the weight after transposition into the linear transformation formula has:
(128,20)*(20,30)+(30,1) = (128,30)Therefore, output.size is (128,30)