table of Contents
2.2 Install TEZ calculation engine
3.1 Counting Top 10 Video Views
3.2 Top 10 Popularity of Statistical Video Categories
3.4 Counting Video Views and Sorting by Category of Top50 Related Videos
3.5 Count the top 10 video popularity in each category, take Music as an example
3.6 Count the top 10 video views of each category
0 Requirements description
Statistics on the regular indicators of iQiyi video website, various TopN indicators: ( multi-dimensional analysis )
- Count the top 10 video views
- Statistics video category popularity Top 10
Statistics of the top 20 videos of the number of video viewing - Categories and the number of category contains Top20 video
- Count the category and sort of the associated videos of the Top50 by the number of video views
- Count the top 10 video popularity in each category , take Music as an example
- Count the top 10 video views in each category
- Count the top 10 users who uploaded the most videos and the top 20 videos they uploaded with the number of video views
1 data structure
(1 ) Video table
Video table
| Field |
Remarks |
Detailed Description |
| videoId |
Video unique id ( String ) |
11 -digit string |
| uploader |
Video uploader ( String ) |
The user name of the uploaded video String |
| age |
Video age ( int ) |
Integer days of the video on the platform |
| category |
Video category ( Array<String> ) |
Upload the specified video category of the video |
| length |
Video length ( Int ) |
Reshape the video length of the digital sign |
| views |
Views ( Int ) |
The number of times the video has been viewed |
| rate |
Video rating ( Double ) |
Out of 5 points |
| Ratings |
Flow ( Int ) |
Video traffic, integer number |
| conments |
Number of comments ( Int ) |
Integer number of comments for a video |
| relatedId |
Related video id ( Array<String> ) |
Video in the above mentioned id , up to 20 Ge |
(2) User table
user table
| Field |
Remarks |
Field Type |
| uploader |
Uploader username |
string |
| videos |
Number of uploaded videos |
int |
| friends |
Number of friends |
int |
2 Preparation
2.1 Preparation table
(1) Tables that need to be prepared
Create the original data table: gulivideo_ori, gulivideo_user_ori,
Create the final table: gulivideo_orc, gulivideo_user_orc
(2 ) Create the original data table
1) gulivideo_ori
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile;2) Create the original data table: gulivideo_user_ori
create table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;(3) Create a table with snappy compression in orc storage format :
(1)gulivideo_orc
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");(2)gulivideo_user_orc
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");(3) Insert data into the ori table
load data local inpath "/opt/module/data/video" into table gulivideo_ori;
load data local inpath "/opt/module/user" into table gulivideo_user_ori;(4) Insert data into the orc table
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;2.2 Install TEZ calculation engine
Tez is a running engine of Hive with better performance than MR. Why is it better than MR? Take a look.
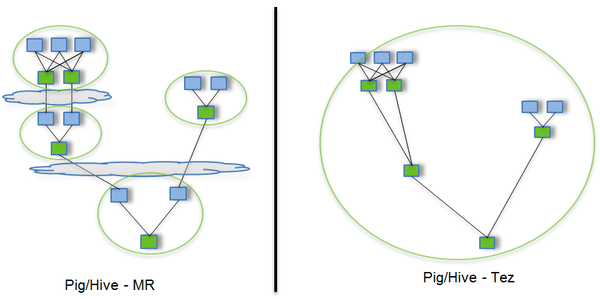
Use Hive to write MR programs directly. Assume that there are four dependent MR jobs. In the above figure, the green is Reduce Task, and the cloud indicates write shielding. The intermediate results need to be persistently written to HDFS.
Tez can convert multiple dependent jobs into one job, so that you only need to write HDFS once, and there are fewer intermediate nodes, which greatly improves the computing performance of the job.
1 ) Copy the tez installation package to the cluster and unzip the tar package
[root@hadoop102 software]$ mkdir /opt/module/tez
[root@hadoop102 software]$ tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez2 ) Upload tez dependency to HDFS
[root@hadoop102 software]$ hadoop fs -mkdir /tez
[root@hadoop102 software]$ hadoop fs -put /opt/software/tez-0.10.1-SNAPSHOT.tar.gz /tez3 ) Create a new tez-site.xml
[root@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/tez-site.xmlAdd the following content:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>4 ) Modify Hadoop environment variables
[root@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/shellprofile.d/tez.shAdd Tez's Jar package related information
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}5 ) Modify the calculation engine of Hive
[root@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xmlAdd to
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>6 ) Solve the log Jar package conflict
[root@hadoop102 software]$ rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar
3 Business analysis
3.1 Counting Top 10 Video Views
Idea: Use order by to do a global sort according to the views field, and we set to display only the first 10 items.
Final code:
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY
views DESC
LIMIT 10;3.2 Top 10 Popularity of Statistical Video Categories
Ideas:
- (1) That is, count the number of videos in each category, and show the top 10 categories that contain the most videos.
- (2) We need to aggregate according to the category group by, and then count the number of videoIds in the group.
- (3) Because the current table structure is: one video corresponds to one or more categories. So if you want to group by categories, you need to first convert the categories to rows (expand), and then count.
- (4) Finally, it is sorted by popularity, and the top 10 items are displayed.
Final code:
SELECT
t1.category_name ,
COUNT(t1.videoId) hot
FROM
(
SELECT
videoId,
category_name
FROM
gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
GROUP BY
t1.category_name
ORDER BY
hot
DESC
LIMIT 103.3 Count the categories of the 20 videos with the highest number of video views and the number of categories containing Top20 videos
Ideas:
- (1) First find all the information of the entries belonging to the 20 videos with the highest number of views, and sort them in descending order
- (2) Split the category in these 20 pieces of information (column to row)
- (3) Finally, query the name of the video category and how many Top20 videos there are under that category
Final code:
SELECT
t2.category_name,
COUNT(t2.videoId) video_sum
FROM
(
SELECT
t1.videoId,
category_name
FROM
(
SELECT
videoId,
views ,
category
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 20
) t1
lateral VIEW explode(t1.category) t1_tmp AS category_name
) t2
GROUP BY t2.category_name3.4 Counting Video Views and Sorting by Category of Top50 Related Videos
Code:
SELECT
t6.category_name,
t6.video_sum,
rank() over(ORDER BY t6.video_sum DESC ) rk
FROM
(
SELECT
t5.category_name,
COUNT(t5.relatedid_id) video_sum
FROM
(
SELECT
t4.relatedid_id,
category_name
FROM
(
SELECT
t2.relatedid_id ,
t3.category
FROM
(
SELECT
relatedid_id
FROM
(
SELECT
videoId,
views,
relatedid
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 50
)t1
lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id
)t2
JOIN
gulivideo_orc t3
ON
t2.relatedid_id = t3.videoId
) t4
lateral VIEW explode(t4.category) t4_tmp AS category_name
) t5
GROUP BY
t5.category_name
ORDER BY
video_sum
DESC
) t63.5 Count the top 10 video popularity in each category, take Music as an example
Ideas:
- (1) If you want to count the Top10 video popularity in the Music category, you need to find the Music category first, then you need to expand the category, so you can create a table to store the expanded data of the categoryId.
- (2) Insert data into the table expanded by category.
- (3) Count the popularity of videos in the corresponding category (Music).
Count the Top10 of the Music category (others can also be counted)
SELECT
t1.videoId,
t1.views,
t1.category_name
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
WHERE
t1.category_name = "Music"
ORDER BY
t1.views
DESC
LIMIT 103.6 Count the top 10 video views of each category
Final code:
SELECT
t2.videoId,
t2.views,
t2.category_name,
t2.rk
FROM
(
SELECT
t1.videoId,
t1.views,
t1.category_name,
rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
)t2
WHERE t2.rk <=103.7 Count the top 10 users who uploaded the most videos and the top 20 videos they uploaded with the number of video views
Ideas:
- (1) Find the 10 users who uploaded the most videos
- (2) Associate the gulivideo_orc table, find all the videos uploaded by these 10 users, and take the top 20 according to the number of views
Final code:
SELECT
t2.videoId,
t2.views,
t2.uploader
FROM
(
SELECT
uploader,
videos
FROM gulivideo_user_orc
ORDER BY
videos
DESC
LIMIT 10
) t1
JOIN gulivideo_orc t2
ON t1.uploader = t2.uploader
ORDER BY
t2.views
DESC