This article only briefly introduces the technology used. If you want to know more, please go to the corresponding official website to learn.
This article is suitable for novices who have little contact with crawler related knowledge, mainly to popularize how Selenium does crawlers, please skip it.
Many people learn python and after mastering the basic grammar, they don't know where to find cases to get started.
Many people who have done case studies do not know how to learn more advanced knowledge.
So for these three types of people, I will provide you with a good learning platform, free to receive video tutorials, e-books, and the source code of the course!
QQ group: 701698587
1. A brief introduction to Selenium
1 Introduction
Selenium is an automated testing tool for testing websites and supports various mainstream interface browsers.
In short, Selenium is a library for automated website testing, and its positioning is for automated testing. We can also use it as a crawler to obtain some web page information, and this crawler simulates the operation of a real browser, which is more practical.
Selenium is the only automated testing tool on the market that can compete with paid products.
If you want to learn more, you can go to Selenium Chinese website to learn: Poke me to Selenium Chinese website
2. Installation
To use Selenium, you must first install the relevant libraries in python:
pip install Selenium
Install the webdricer driver file of the corresponding browser, here is a link to chrome, and you can search it on the Internet for other browsers. Poke me to download the chrome webdriver driver file. Choose the right version, I chose 2.23.
After downloading and decompressing, get the exe file, copy this file to the chrom installation folder:
Generally it is C:\Program Files (x86)\Google\Chrome\Application, or C:\Program Files\Google\Chrome\Application.
Then configure the path to the environment variable:
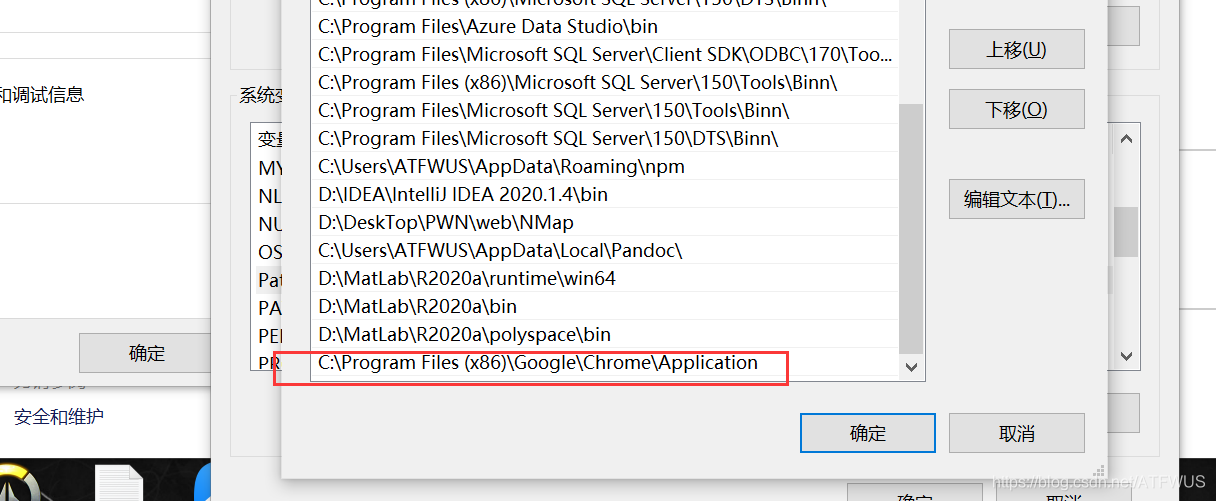
Finally, write a piece of code to test:
from selenium import webdriverdriver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
If you see that a browser window is opened, it is successful, otherwise there will be a corresponding error message below, you need to check the previous steps.
3. Simple introduction
1. Element positioning method:
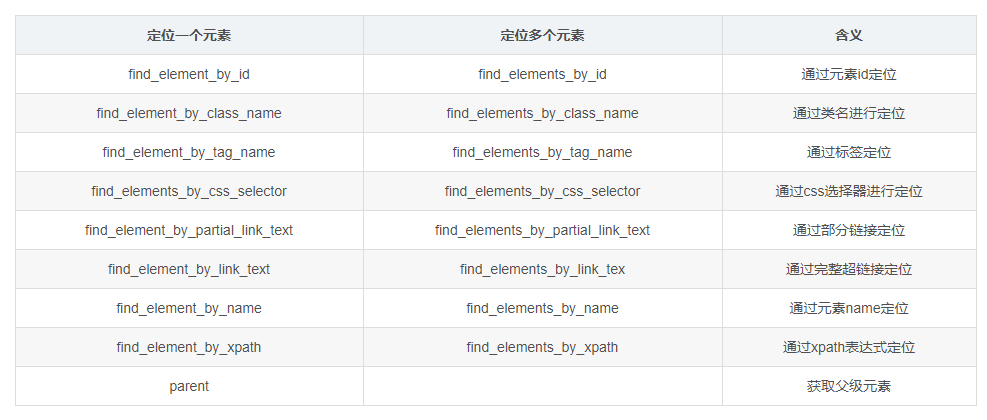
Basically, the first few ways can get the required elements, and you need to identify whether the result is unique to select the corresponding selector.
Calling this method through the drive object returns a label object or a list of label objects. The text under the label can be obtained through .text, and other attribute values of the label can be obtained through get_attribute().
Share a small coup for quickly locating elements: see if the id, class, and name of the tag where the required information is located are related to the semantics of the information under the tag. Generally, the relevant ones are unique. (Think from the developer's point of view) If the current label cannot be uniquely positioned, consider the parent label. By analogy, you can always find a positioning method.
2. Mouse events (simulate mouse operation)
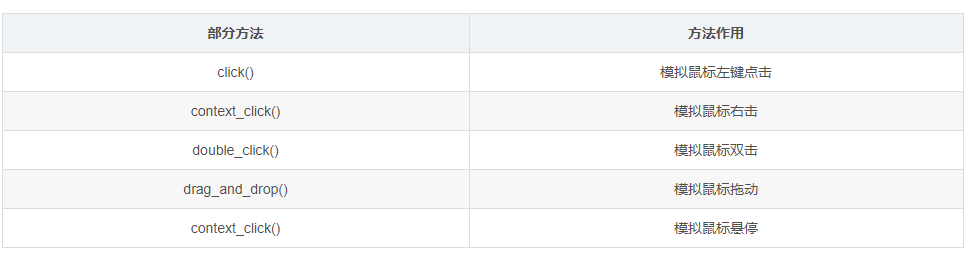
It can be called through the label object.
3. Keyboard events (simulating keyboard operation)
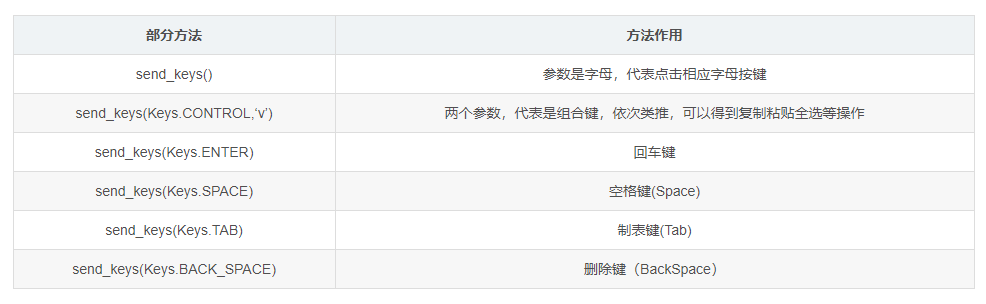
4. Other operations
Other operations include controlling the operation of the browser, obtaining assertion information, form switching, multi-window switching, warning box processing, drop-down box processing, file upload operation, cookie operation, calling js code, screenshots, closing the browser and other operations, because here I don’t use much, so I don’t list them one by one, go to the official website to learn by myself.
2. Crawl the target
This actual combat crawler mainly accomplishes the following goals:
Crawl the basic information of the top 5 songs and the top 500 popular comments of the designated singer on the QQ Music official website.
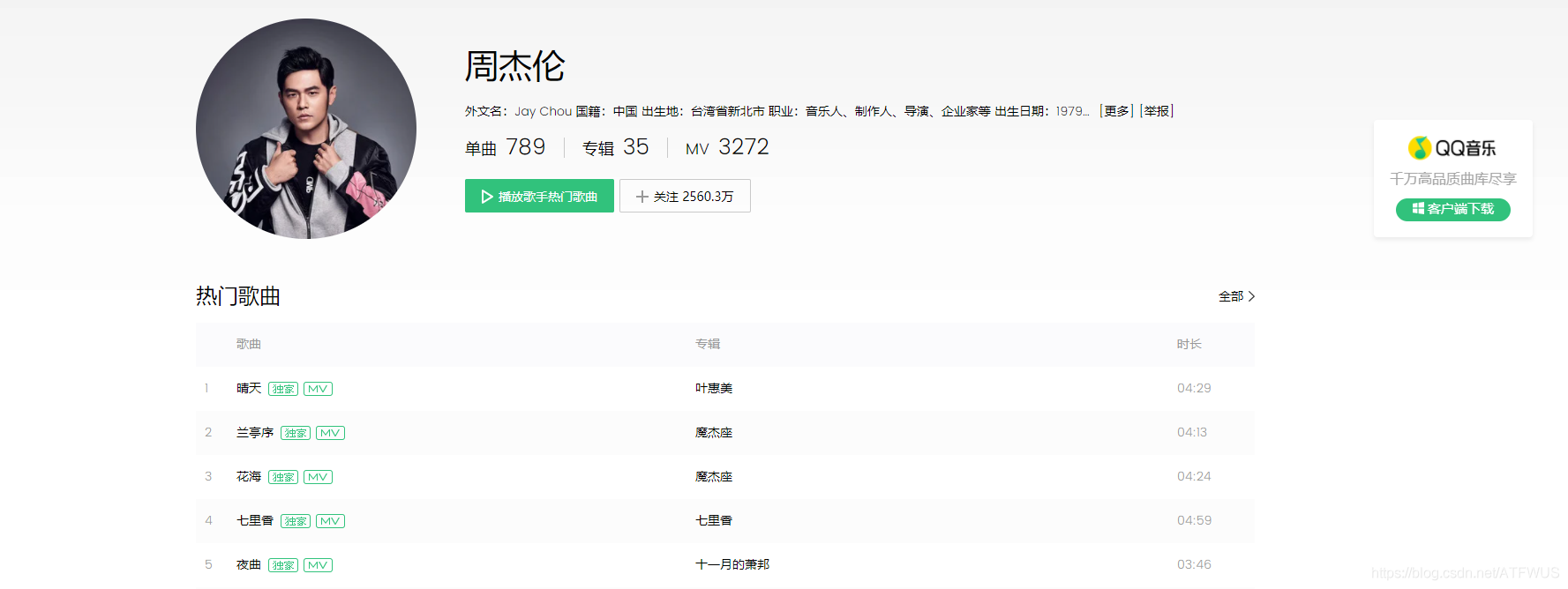
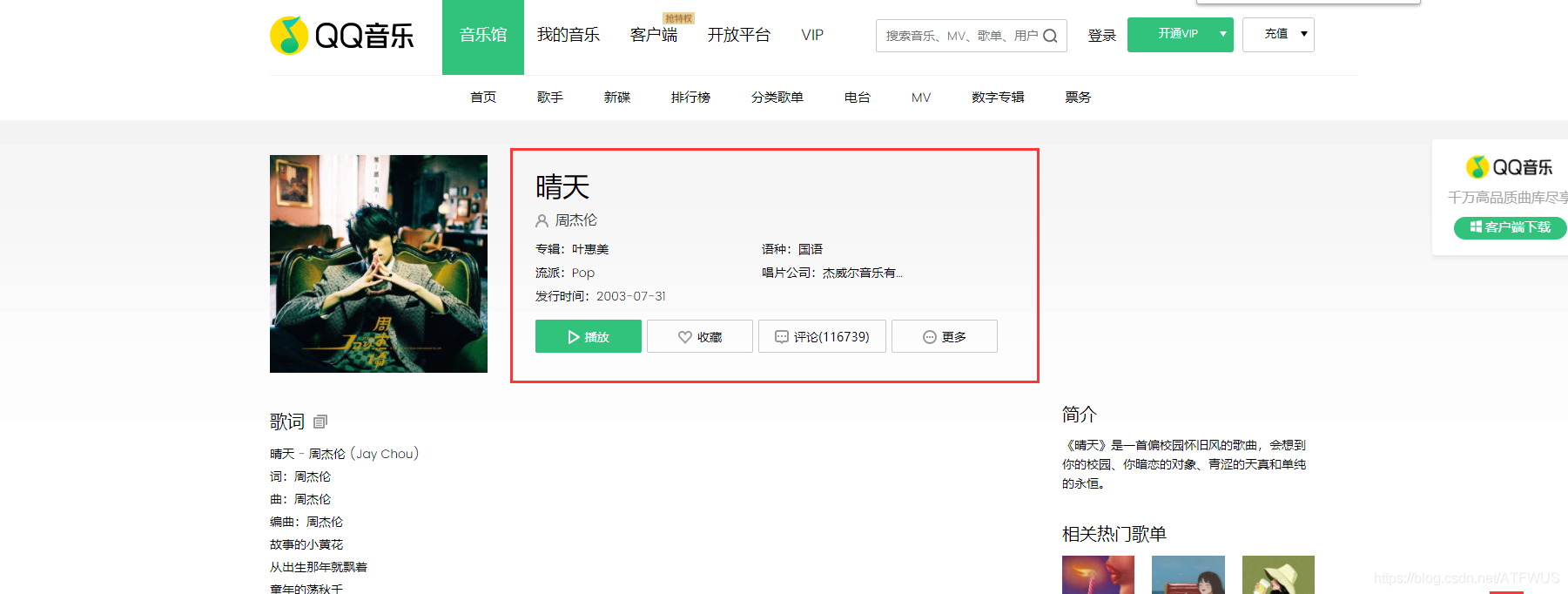
1. Get the url of the top five songs
Analyzing the code of this page, we know that the class of the tag that wraps all the song information is unique, we can get it, and then traverse all the subtags, or get all the divs that wrap the song information at once, and then get the a tag inside.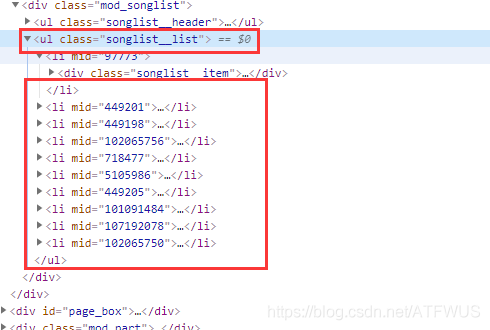
2. Get the basic information of the song
It can be seen that the class name in the basic information tag has a part of semantics, so it can be determined uniquely through the css selector.
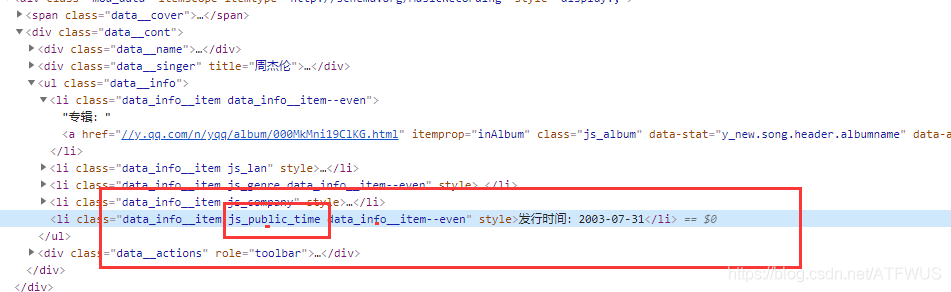
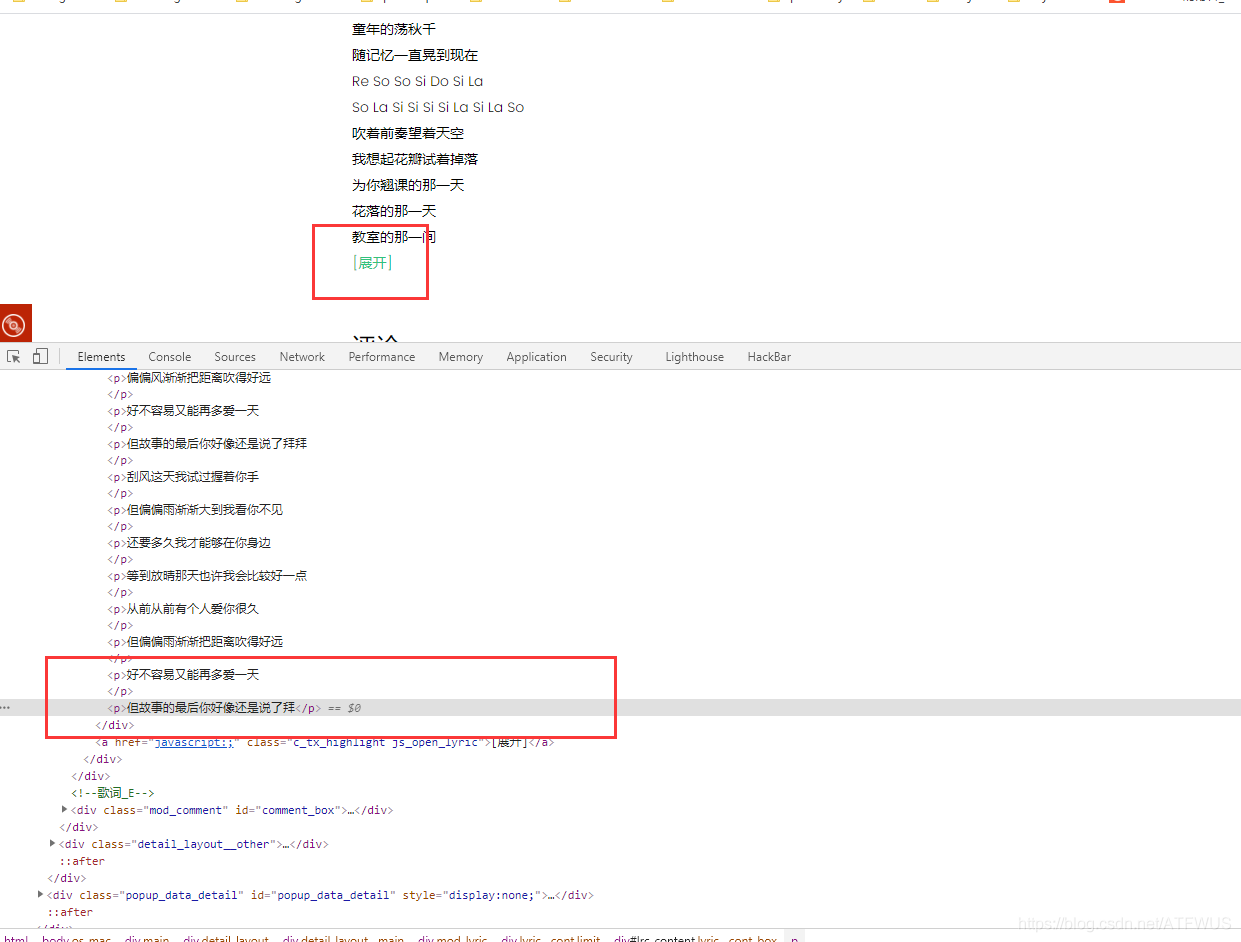
3. Get lyrics
The lyrics on the page are incomplete, it seems that you need to click to expand it, but in fact, all the lyrics are already in the label, it's just a display problem.
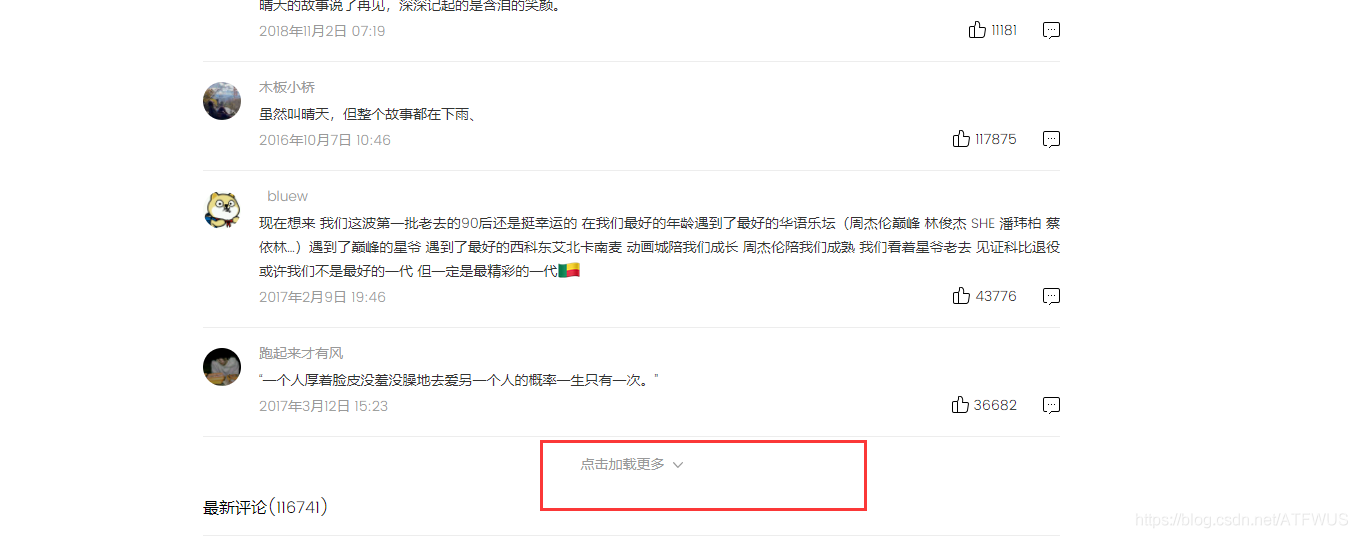
4. Get the first 500 comment messages
We can see that there are fifteen popular comments at a time, and there is one click to load more links below. After clicking, there will be 15 more comments.
We need to simulate 33 clicks and get 510 comments
5. Write to CSV file
Use the csv library to write the crawled data into the csv file for persistence.
6. Implementation code
from selenium import webdriverimport csvfrom time import sleepimport time## Author : ATFWUS# Date : 2021-03-21 20:00# Version : 1.0# 爬取周杰伦最热门五首歌曲的基本信息,歌词,前五百条热门评论# 此代码仅供交流学习使用##1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口driver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")#2.打开QQ音乐 -周杰伦页面driver.get("https://y.qq.com/n/yqq/singer/0025NhlN2yWrP4.html")#3.配置csv_file = open('songs.csv','w',newline='',encoding='utf-8')writer = csv.writer(csv_file)start = time.time()# 取前5首歌曲song_numer=5song_url_list=[]song_resourses=[]songlist__item=driver.find_elements_by_class_name("songlist__item")# 获取所有歌曲urlfor song in songlist__item:song__url=song.find_element_by_class_name("js_song").get_attribute("href")song_url_list.append(song__url)song_numer-=1if(song_numer==0):break# print(song_url_list)print("已获取周杰伦热门歌曲列表前五首的url")print()# 获取一首歌曲所需要的信息def getSongResourse(url):song_resourse={}driver.get(url)# 这个0.5秒用于等待异步请求的完成sleep(0.8)# 获取歌曲名song_name=driver.find_element_by_class_name("data__name_txt").textprint("开始获取歌曲《"+song_name+"》的基本信息")# 获取流派,发行时间,评论数song_liupai = driver.find_element_by_css_selector(".js_genre").text[3:]song_time = driver.find_element_by_css_selector(".js_public_time").text[5:]song_comment_num = driver.find_element_by_css_selector(".js_into_comment").text[3:-1]print("歌曲《" + song_name + "》基本信息获取完毕")print("开始获取歌曲《" + song_name + "》的歌词")# 点击展开歌词driver.find_element_by_partial_link_text("[展开]").click()sleep(0.3)lyic=""# 获取拼接歌词lyic_box=driver.find_element_by_id("lrc_content").find_elements_by_tag_name("p")for l in lyic_box:if l.text!="":lyic+=l.text+"\n"print("歌曲《" + song_name + "》的歌词获取完毕")print("开始获取歌曲《" + song_name + "》的第1-15条热门评论")# 获取500条评论comments=[]# 点击加载更多29次,每次多出15条评论for i in range(33):driver.find_element_by_partial_link_text("点击加载更多").click()print("开始获取歌曲《" + song_name + "》的第"+str((i+1)*15+1)+"-"+str((i+2)*15)+"条热门评论")sleep(0.5)comments_list=driver.find_element_by_css_selector(".js_hot_list").find_elements_by_tag_name("li")for com in comments_list:content=com.find_element_by_css_selector(".js_hot_text").textcontent_time=com.find_element_by_css_selector(".comment__date").textzan_num=com.find_element_by_class_name("js_praise_num").textcomment = {}comment.update({"评论内容":content})comment.update({"评论时间":content_time})comment.update({"评论点赞次数":zan_num})comments.append(comment)print("歌曲《" + song_name + "》的前五百条热门评论获取完毕")print("歌曲《"+song_name+"》所有信息获取完毕")print()song_resourse.update({"歌曲名":song_name})song_resourse.update({"流派":song_liupai})song_resourse.update({"发行时间":song_time})song_resourse.update({"评论数":song_comment_num})song_resourse.update({"歌词":lyic})song_resourse.update({"500条精彩评论":comments})return song_resoursefor song_page in song_url_list:song_resourses.append(getSongResourse(song_page))# breakprint("正在写入CSV文件...")for i in song_resourses:writer.writerow([i["歌曲名"],i["流派"],i["发行时间"],i["评论数"],i["歌词"]])for j in i["500条精彩评论"]:writer.writerow([j["评论内容"],j["评论时间"],j["评论点赞次数"]])writer.writerow([])csv_file.close()end = time.time()print("爬取完成,总耗时"+str(end-start)+"秒")
7. Code considerations
Note that after the drive object get requests a web page, it will sleep for a period of time. This period of time is used by the website to make ajax requests to obtain the required data. If you do not sleep, then the data you get is likely to be empty or the default value. .
The whole crawling down for about 10 minutes, I have output the progress, do not close it in advance, because I only wrote the csv file at the end, there is nothing in the csv file when I close it in advance.
QQ Music recently had a bug. After clicking to get more, the newly added 15 comments are still the original ones. It may also be caused by the Internet. There should be no problem with the code.
This code is mainly used to crawl main data, and many simulation operations may be imperfect.
8. Simple calculation data using Padas library
Regarding the use of the Padas library and its two data structures, please check the official website, which will not be explained here. Poke me to go
First read the data in the csv file into the memory, and then perform the operation.
You need to install the padas library first:
pip install padas
import pandas as pdimport csv# 这五个列表用于创建Seriesse=[]names=[]# 先读取CSV文件的内容至内存中with open("songs.csv",'r',encoding="utf8") as f:# 创建阅读器对象reader = csv.reader(f)rows = [row for row in reader]index=0print("开始解析CSV数据...")for i in range(5):s1=[]# 读取第一行信息names.append(rows[index].__str__().split(',')[0][2:-1])index+=1# 读取五百条评论的点赞消息for j in range(510):s1.append(int(rows[index].__str__().split(',')[2][2:-2]))index+=1se.append(s1)# 读取掉空行index+=1print("CSV数据解析成功\n")# 创建的5个seriesfor i in range(5):series=pd.Series(se[i])print("歌曲《"+names[i]+"》的平均点赞次数是:" + str(series.mean()))print("歌曲《" + names[i] + "》的标准差是:" + str(series.std()))print()
9. Screenshot of approximate results
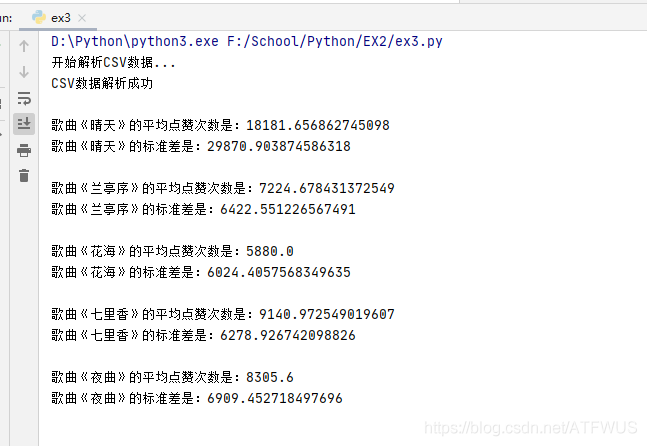
Exclamation: Crawling down thousands of comments, after reading it, I found that it feels sad, hahaha