Feature engineering
1. Why is feature engineering needed?
Because "data and features determine the upper limit of machine learning, and models and algorithms just approach this upper limit", the use of professional background knowledge and skills to process data makes the algorithm better.
2. What is feature engineering? The
sklearn library is used for feature engineering, and the
pandas library is used for data cleaning and data processing.
Feature extraction
Definition: Convert arbitrary data (such as text or images) into digital features that can be used for machine learning, also called feature
valueization . Use sklearn.feature_extraction() function
Dictionary data: Use dictionary features to extract
text data: Use text features to extract
image data: Use image feature extraction
1. Dictionary feature extraction (convert the category features in the dictionary into one-hot encoding )
Purpose : Convert the category features in the dictionary into one-hot encoding
Application scenarios : a. When there are many category features in the data set (first change The features in the data set are converted to dictionary type, and then use DictVectorizer() for dictionary feature extraction)
b. When the data you get is the dictionary type
from sklearn.feature_extraction import DictVectorizer
` 
Code implementation:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
# def datasets_demo():
# #获取数据集
# iris=load_iris()
# print('鸢尾花数据集:\n',iris)
# print('查看数据集描述:\n', iris['DESCR'])
# print('查看特征值的名字:\n', iris.feature_names)
# print('查看特征值:\n', iris.data, iris.data.shape)
# #数据集划分
# x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
# print('训练集的特征值:\n',x_train,x_train.shape)
def dict_demo():
data=[{
'city':'北京','temperature':100},{
'city':'上海','temperature':100},{
'city':'深圳','temperature':30}]
#实例化一个转换器类
transfer=DictVectorizer()
#调用fit_tranform()
data_new=transfer.fit_transform(data)
print('data_new:\n',data_new)
if __name__=='__main__':
#datasets_demo()
dict_demo()
Return a sparse matrix (sparse matrix): When
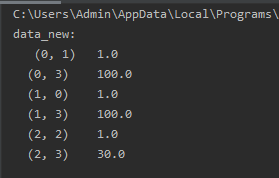
sparse=Flase is set, a two-dimensional array is returned:
transfer=DictVectorizer(sparse=False)
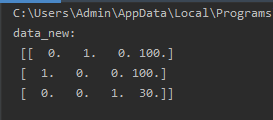
The benefit of returning a sparse matrix: when there are too many features, many, many 0s can be omitted
Return feature name:
def dict_demo():
data=[{
'city':'北京','temperature':100},{
'city':'上海','temperature':100},{
'city':'深圳','temperature':30}]
#实例化一个转换器类
transfer=DictVectorizer(sparse=False)
#调用fit_tranform()
data_new=transfer.fit_transform(data)
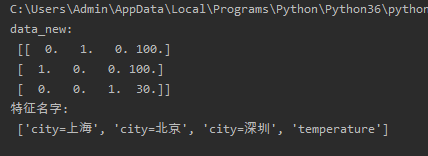
feature_names=transfer.get_feature_names()
print('data_new:\n',data_new)
print('特征名字:\n', feature_names)
2. Text feature extraction ( extract by feature words)
Method 1: CountVectorizer() (to count the number of feature words in each sample ) Ignore single letters and punctuation

①. When the feature words are in English:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
'''
英文文本特征提取
'''
data=['life is short,i like like python','life is too long,i dislike python ']
#实例化一个转换器类
transfer=CountVectorizer()
# 调用fit_tranform()
data_new=transfer.fit_transform(data)
feature_names = transfer.get_feature_names()
print('data_new:\n', feature_names)
print('data_new:\n',data_new)
#将稀疏矩阵转换为二维数组
print('data_new:\n', data_new.toarray())
if __name__=='__main__':
#datasets_demo()
# dict_demo()
count_demo()

②. When the characteristic word is Chinese: (Single Chinese characters are not supported) If
there is no space between each character, the sentence will be considered as a word:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def count_Chinese_demo():
"""
中文文本特征提取
"""
data = ['我爱北京天安门', '天安门最好看']
# 实例化一个转换器类
transfer = CountVectorizer()
# 调用fit_tranform()
data_new = transfer.fit_transform(data)
feature_names = transfer.get_feature_names()
print('data_new:\n', feature_names)
print('data_new:\n', data_new)
# 将稀疏矩阵转换为二维数组
print('data_new:\n', data_new.toarray())
if __name__=='__main__':
#datasets_demo()
# dict_demo()
# count_demo()
count_Chinese_demo()

There is a space between each word, he can recognize it (manual word segmentation), if you don’t want to do manual word segmentation, then use jieba library memory automatic word segmentation
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def count_Chinese_demo():
data = ['我 爱 北京 天安门', '天安门 最好看']
# 实例化一个转换器类
transfer = CountVectorizer()
# 调用fit_tranform()
data_new = transfer.fit_transform(data)
feature_names = transfer.get_feature_names()
print('data_new:\n', feature_names)
print('data_new:\n', data_new)
# 将稀疏矩阵转换为二维数组
print('data_new:\n', data_new.toarray())
if __name__=='__main__':
#datasets_demo()
# dict_demo()
# count_demo()
count_Chinese_demo()

Use jieba library (Chinese automatic word segmentation)
Example 1:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
#返回生成器对象
a=jieba.cut(text)
print('生成器对象:',a)
#转换为列表
a = list(jieba.cut(text))
print('列表:',a)
#转换成字符串
a=''.join(list(jieba.cut(text)))
print('字符串:',a)
if __name__=='__main__':
cut_word('我爱北京天安门')

Example 2:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
text=" ".join(list(jieba.cut(text)))
return text
def count_Chinese_demo2():
"""中文文本特征抽取,自动分词
:return:"""
#1.将中文文本分词
data=["北京时间,常规赛下半段赛程正式打响,今天一共有两场比赛,奇才输给了灰熊,马刺输给了独行侠。",
'继火箭之后,马刺也将进入市场,开始甩卖老将,首当其冲就是球队功勋阿尔德里奇。',
'此外杜兰特也有坏消息,他的伤势问题,包括他如今带领的篮网也引来非议。']
data_new=[]#建一个空列表
for sent in data:
data_new.append(cut_word(sent))
print('新的,分好词的列表:\n',data_new)
#2.对分好词的新列表,进行文本特征抽取
# 实例化一个转换器类
transfer = CountVectorizer()
# 调用fit_tranform()
data_final = transfer.fit_transform(data_new)
print('data_new:\n', data_final.toarray())
print('特征名字:\n', transfer.get_feature_names())
if __name__=='__main__':
count_Chinese_demo2()

Disadvantage of Method 1: Unable to find keywords (it appears many times in a certain type of articles, but rarely appears in other types of articles)
Method 2: Tf-idf() text feature extraction (important in the early data processing of machine learning)
Purpose: If a word or phrase appears in an article with a high probability, but rarely appears in other articles, then evaluate The latter end of the term is very important to this article.


from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import jieba
def tfidf_demo():
"""使用Tf-IDF进行中文文本特征抽取
:return:"""
#1.将中文文本分词
data=["北京时间,常规赛下半段赛程正式打响,今天一共有两场比赛,奇才输给了灰熊,马刺输给了独行侠。",
'继火箭之后,马刺也将进入市场,开始甩卖老将,首当其冲就是球队功勋阿尔德里奇。',
'此外杜兰特也有坏消息,他的伤势问题,包括他如今带领的篮网也引来非议。']
data_new=[]
for sent in data:
data_new.append(cut_word(sent))
print('新的,分好词的列表:\n',data_new)
#2.对分好词的新列表,进行文本特征抽取
# 实例化一个转换器类
transfer = TfidfVectorizer()
# 调用fit_tranform()
data_final = transfer.fit_transform(data_new)
print('data_new:\n', data_final.toarray())
print('特征名字:\n', transfer.get_feature_names())
if __name__=='__main__':
tfidf_demo()

The high probability value in the two-dimensional array of the result is the word with many occurrences, which is suitable as a keyword for classification
to sum up:
The purpose of feature extraction : feature value of the original data to facilitate our subsequent processing
1. Feature extraction on the dictionary: convert the categories in the dictionary data to one-hot encoding
2. Feature extraction on the text:
Method 1: Use CountVectorizer () Count the number of feature words in each sample . Method 2: Calculate the Tf-idf() index to evaluate the importance of each word in this article
