Summary of common big data operation and maintenance problems
Other installation issues:
1. IDEA installation and configuration
https://blog.csdn.net/qq_27093465/article/details/77449117
2.IntelliJ IDEA modifies maven to Alibaba Cloud warehouse
https://blog.csdn.net/u013541411/article/details/100166712
3. Mysql installation: https://blog.csdn.net/qq_36582604/article/details/80526287
4. Detailed steps for CentOS7 configuration NAT mode network (pro-test version) https://blog.csdn.net/Jackson_mvp/article/details/100856966
5. Solve the problem that Xshell is very slow to connect to the virtual machine:
vi /etc/ssh/sshd_config Remove the UseDNS yes comment and change it to UseDNS no
systemctl restart sshd.service
6. Unable to delete when entering hive---session elective--linux--cancel the check mark before ANS, otherwise the font will change color
https://blog.csdn.net/wanghaiyuan1993/article/details/46272553
Big data operation and maintenance issues:
hadoop:
1. The cluster is configured to open the environment jps, but one node is missing?
Solution:
- Shut down the cluster: sbin/stop-all.sh [operate only on the master]
- Delete the files under /usr/local/src/hadoop-2.6.1/dfs/name [Operation for each node]
- Delete the files under /usr/local/src/hadoop-2.6.1/dfs/data [Operation for each node]
- Delete the files under /usr/local/src/hadoop-2.6.1/tmp [Operation for each node]
- Delete the following files in /usr/local/src/hadoop-2.6.1/logs [Operation for each node]
- Reformatting hadoop namenode -format [Only operate on master]
- Start the cluster: sbin/start-all.sh [Only operate on the master]
2.I can't see the results when I run the spark test code on the yarn cluster, and the historical process installation practices of hadoop and spark.
When using Yarn as the cluster manager, when Spark is started, the corresponding information can no longer be viewed from the SparkUI-4040 port. It can only be viewed from the Yarn and history server of Hadoop, but it is not enabled by default.
Configure the history server:
(1). HDFS configuration
Make sure that your Hadoop has been configured and can be started normally.
Next, add configuration to the existing Hadoop configuration.
cd $HADOOP_HOME/etc/hadoop
- mapred-site.xml file
<!--Spark Yarn-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
- yarn-site.xml file
<!--Spark Yarn-->
<!-- Whether to enable aggregation log-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- Configure the address of the log server, the work node uses -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
</property>
<!-- Configure log expiration time, in seconds-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
3. Hadoop files cannot be downloaded and Tracking UI in YARN cannot access historical logs
Solution: The windows system cannot resolve the domain name. Copy the hosts file hostname to the windows hosts
4. Yarn resources are occupied
- Report insufficient memory
Container [pid=8468,containerID=container_1594198338753_0001_01_000002] is running 318740992B beyond the 'VIRTUAL' memory limit. Current usage: 111.5 MB of 1 GB physical memory used; 2.4 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1594198338753_0001_01_000002 :
Solution: Add the following configuration to the /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml file of hadoop102, and then distribute it to the hadoop103 and hadoop104 servers, and restart the cluster:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>- Note: If an abnormality occurs during the test, you can set the virtual memory detection to false in yarn-site.xml to distribute the configuration and restart the cluster
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>Hive:
1. When performing join on a large table in hive, oom's processing suggestions are generated

Performance analysis of the join between small and medium tables in Hive link→ http://blog.sina.com.cn/s/blog_6ff05a2c01016j7n.html
2. The hive query shows the header modification:
Add the following in the /conf/hive-site.xml configuration file under the hive installation directory:
Only add the front part, the query will display tablename.column.name
<property>
<name>hive.resultset.use.unique.column.names</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
3.hive data skew
(1) Data skew caused by null values
For example, in the log, there is often a problem of information loss, such as the user_id in the log. If the user_id is associated with the user_id in the user table, the problem of data skew will be encountered
- If the user_id is empty, it will not participate in the association operation
select * from log a join users b on a.user_idisnotnulland a.user_id = b.user_id
union all
select * from log a where a.user_id is null
(2) Data skew caused by association of different data types
The user_id field in the user table is int, and the user_id field in the log table has both int and string types. When the join operation of two tables is performed according to user_id, the default Hash operation is assigned, which will cause all the records of String type id to be assigned to a Reducer
- After agreeing to convert different types of fields to String type, make associations
select * from users a left outer join logs b on a.user_id = cast(b.user_idas String);
Spark
1.Spark shell启动报错(yarn-client&yarn-cluster):Yarn application has already ended! It might have been killed or unable to launch...
Start the log, the error message is as follows:
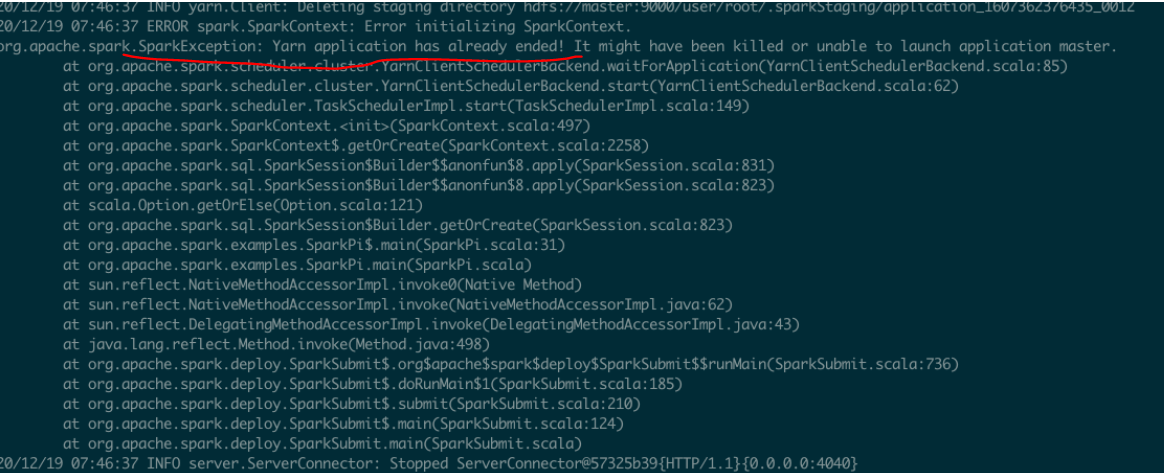
"Yarn application has already ended! It might have been killed or unable to launch application master", this is an exception, open the mr management page, http://master:8088/
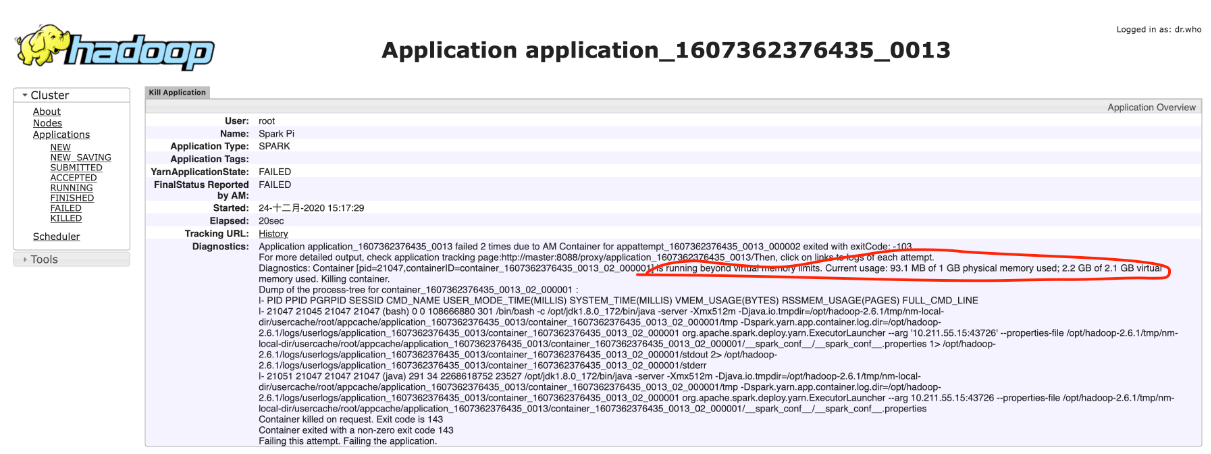
The focus is on the red box, the actual value of 2.2g of virtual memory exceeds the upper limit of 2.1g. That is to say, the virtual memory exceeds the limit and the contratrainer is not started.
solution
yarn-site.xml adds configuration:
<!--The following configuration is added to solve the problem of error reporting when spark-shell runs in yarn client mode. It is estimated that spark-summit will also have this problem. Two configurations can solve the problem with only one configuration, of course, there is no problem with both configurations -->
<!--Does the virtual memory setting take effect? If the actual virtual memory is greater than the set value, spark may report an error when running in client mode, "Yarn application has already ended! It might have been killed or unable to l"-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<!--Configure the value of virtual memory/physical memory, the default is 2.1, the default physical memory should be 1g, so the virtual memory is 2.1g-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
After modification, restart hadoop and spark-shell. The problem is solved
2. Spark-submit runs scala code, a ClassNotFoundException appears
First check whether the code jar package path is complete, and secondly check whether the jar package has a running main class in IDEA, and if it is, repackage it.
3. The spark code mode is not the same as the submit command mode, resulting in running errors
Note: What mode is used for the code and what mode is used for the startup command? Yarn cluster mode can be used to start the code without adding local.
Pit 1: If the scala code is setMaster(local), start in local mode. If you want to start in yarn cluster mode, an error will occur.
代码中:val userScore = new SparkConf().setMaster("local").setAppName("UserScore")
Start command: spark-submit --class UserScore sparktest-1.0-SNAPSHOT.jar
Pit 2: maven install package jar, start --class and add the class name directly. For example, if you want to start userwatchlist, start writing from the java directory, if there is a directory, write the directory, and start the command directly to write --class base.teacheruserwatchlist + jar package name. can