Git basics
Get to know Git
version control
Version control is a system that records changes in file content to facilitate future review of specific version revisions
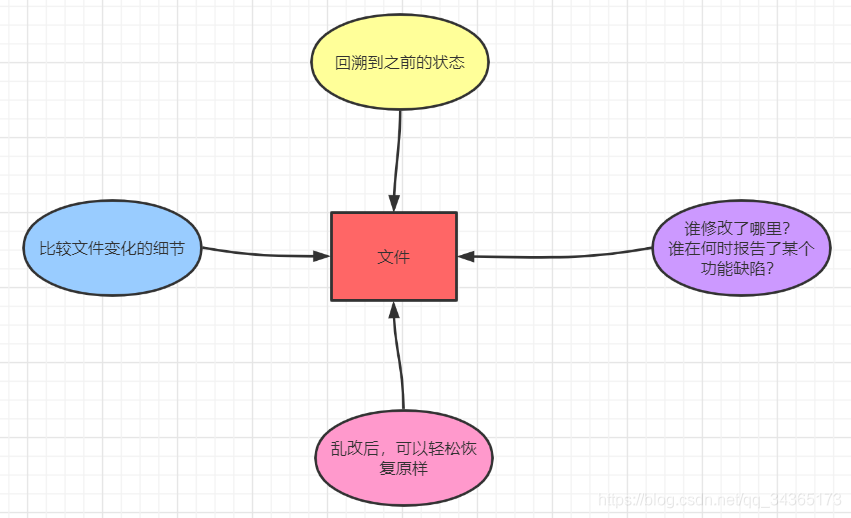
The history of version control
1: Local version control system
The main purpose is to use a simple database to record the differences between the previous file updates
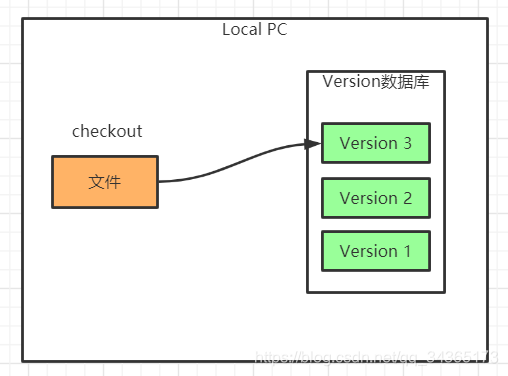
and save the changes before and after the file revision on the hard disk.
So, the above control system can only be used locally. How can different developers work together?
2: Centralized version control system
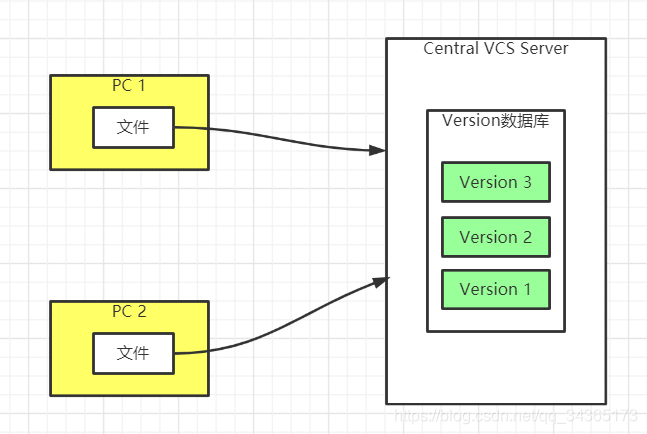
As shown above, there is a single centralized management server that saves all revisions of files; and those who need to work together connect to the server through the client, and can take out the latest files or submit updates, etc.
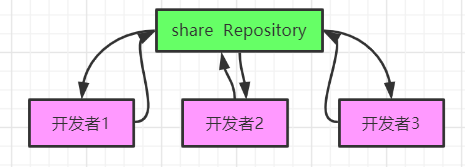
What are the advantages of the above control system? And disadvantages?
advantage
1: You can clearly see what other people are doing in the project.
2: You can control the permissions of each developer.
3: It is easier to manage a CVCS than to maintain a local database on the client.
Disadvantage
1: The single point of failure of the central server. Once the server has a problem, the client can no longer perform update submission operations.
2: The data is stored on the disk. If the disk is damaged, all data may be lost.
3: Distributed version control system
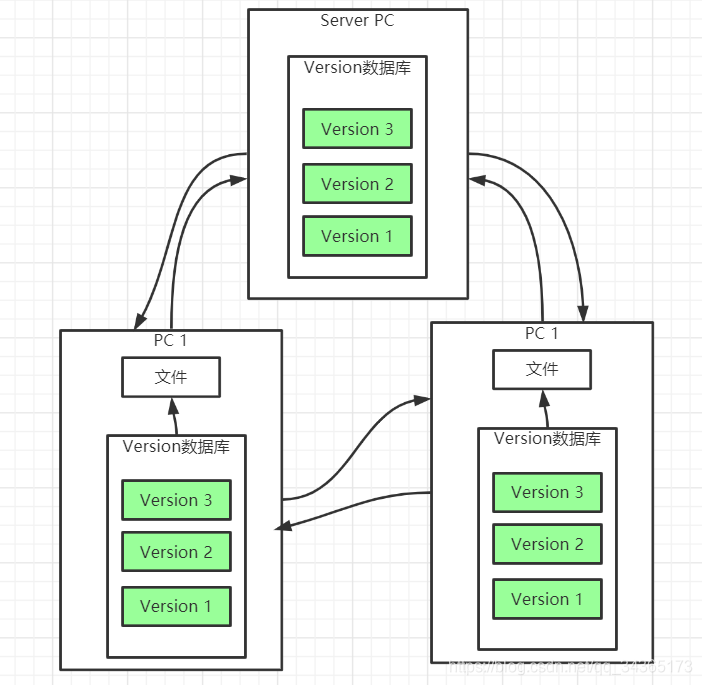
Each cloning operation of the client is a complete backup of the code repository, not just extracting the latest version of the file snapshot, any server used for collaborative work fails, you can use any mirrored local repository to restore afterwards
advantage:
1: You can specify to interact with several different remote code repositories.
2: You can collaborate with different groups of people in the same project.
3: You can set up different collaboration processes according to your needs.
Git’s design goals:
1: Speed
2: Simple design
3: Support for non-linear development mode: tens of thousands of parallel development branches are required
4: Fully distributed
5: Ability to efficiently manage super-large-scale projects
Install Git
The installation of Git is relatively simple. You can download the installation package from the official website. Official website address: Git download , or download from my address here: Link: https://share.weiyun.com/MUODHd1a Password: kqr43s How
to use Git There are the following two, the specific usage can be consulted on Baidu
The core concepts of Git
How Git is used
1: Record the snapshot directly, not the difference of files
Most systems such as CVS and SVN use file change lists to store information. The stored information is regarded as a set of basic files and the cumulative difference
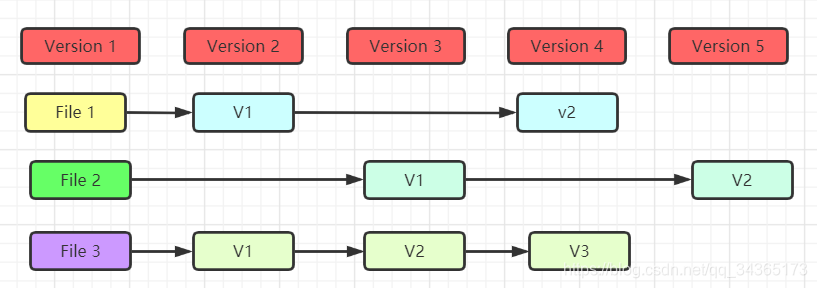
of each file over time. The above figure is a simple example: stored It is the difference between each file and the initial version; for example, File 1, there are two updated versions, and the difference from Version 1 is recorded in the database
Git regards data as a set of snapshots of a small file system:
1: When a file changes, a snapshot of all files will be made and the index of this snapshot will be saved
2: When the file has not changed, a link will be kept to point to Previously stored files
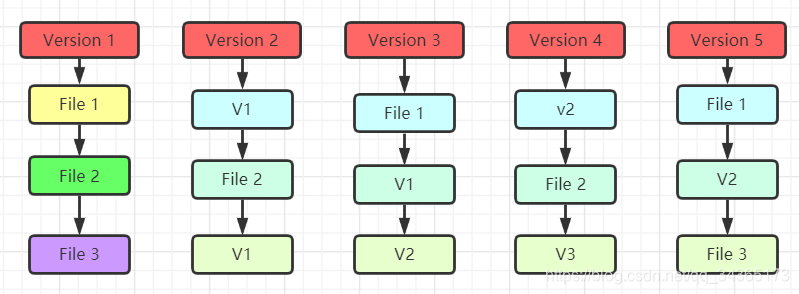
2: Almost all operations are performed locally
Because it is a snapshot, most operations only need to access local files and resources
. There is the completion history of the project on the local disk, the operation is relatively fast, and the history update record of the project is browsed, and there is no need to connect to the server to obtain the history.
You can also submit if there is no network, and upload if there is a network
3: Guarantee integrity
All data in Git will calculate the checksum ( checksum Baidu Encyclopedia ) before storage , and then use the checksum to refer to it. It is impossible to change any file content and directory content without Git knowing it. Git uses SHA- 1Hashing method to calculate the checksum
. The information stored in the Git database is indexed by the hash value of the file content
4: Generally only add data
Git operations almost only add data to the Git database, and it is difficult to perform irreversible operations.
Uncommitted data may be lost or mess up the modified content, such as common file conflicts,
but once a snapshot is submitted to Git, it is difficult to lose it again. If you also push the data to other warehouses, the data will be more secure
5: The three states of Git
One: Committed: The data has been safely saved in the local database.
Two: Modified: The file is modified, but it has not been saved to the database.
Three: Staged: For a modified one The current version of the file is marked so that it will be included in the next snapshot
Git workflow
1: Three working areas of the Git project
Git warehouse: where the metadata and object database of the project are stored. The remote clone warehouse refers to the data here
Working directory: the content extracted independently from the warehouse for a certain version of the project, and put it on the disk for us to use and modify
Temporary storage area: The temporary storage area is a file that saves the file list information that will be submitted next time, usually in the Git warehouse
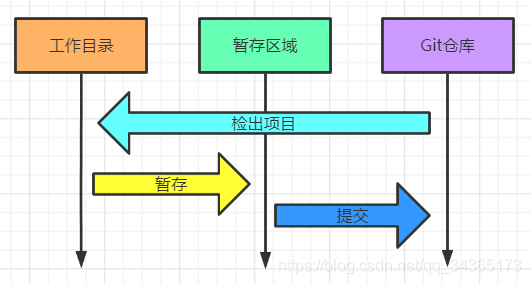
The basic process of Git
1: Modify the file in the working directory
2: Temporarily store the file, put the snapshot of the file into the temporary storage area
3: Submit the update, find the file in the temporary storage area, and store the snapshot permanently in the Git warehouse directory
The difference between Git and SVN
| Features | Git | SVN |
|---|---|---|
| distributed | √ | × |
| Data storage method | Store as metadata | Follow the document |
| Branch | A pointer mark | Another directory |
| Global version number | Code snapshot, uniquely identified by SHA-1 | Source code snapshot at any corresponding time |
| Content integrity | Use SHA-1 checksum to ensure the integrity of the code content | — |
| Network dependence | No need to connect to the Internet, it can be operated locally | You need to be connected to the Internet to submit and view the control information of the entire version |
Basic use of Git
The Git client has the following: command line client, GUI client, TortoiseGit, IDE plug-in
Let’s take the command line client as an example to briefly understand the basic use of Git
Initialize Git
Through the git config tool, you can customize your own Git environment. Each computer only needs to be configured once. The configuration has three dimensions: user, global, and system
1: User information
git config --global user.name “mike”
git config --global user.email [email protected]
git config --global --unset user.name
2: Text editor
git config --global core.editor emacs
3: Check the configuration information
git config --list
Create a Git repository
1: Create a brand new Git repository by command git init
2: Clone an existing warehouse
Git clones almost all the data on the Git warehouse server, not just copy the files needed to complete our work
Git features
1: Submit update
Each file in the working directory has two states: tracked and untracked.
Now create a txt file under the warehouse just created: it
can be imagined that the newly created file is in an untracked state:

You can view the status of the working directory through git status
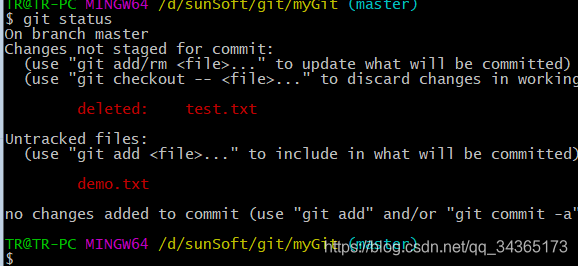
Use git add command operation has been tracked, put the file into the temporary storage area:

you can see that the file has changed, there is an icon
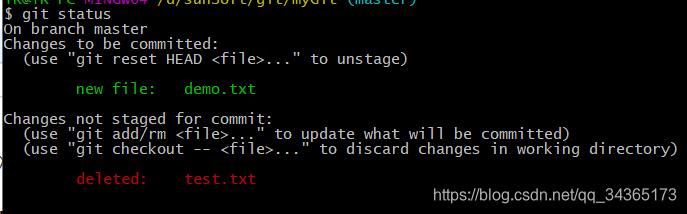
git commit to create a snapshot and put the file into the storage area:
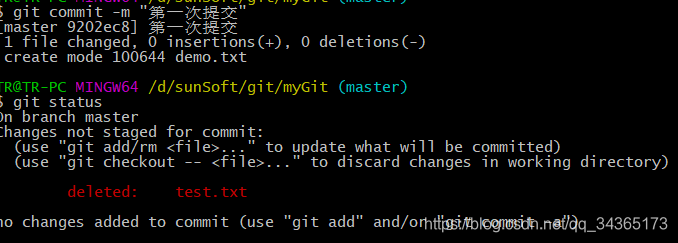

now the file has been submitted, and then modified File, turn the file into a modified state: the

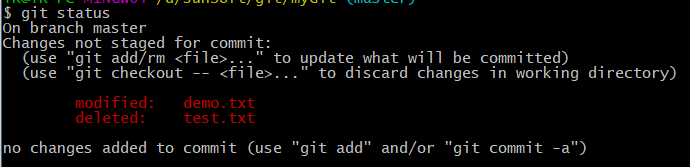
whole process is shown below:
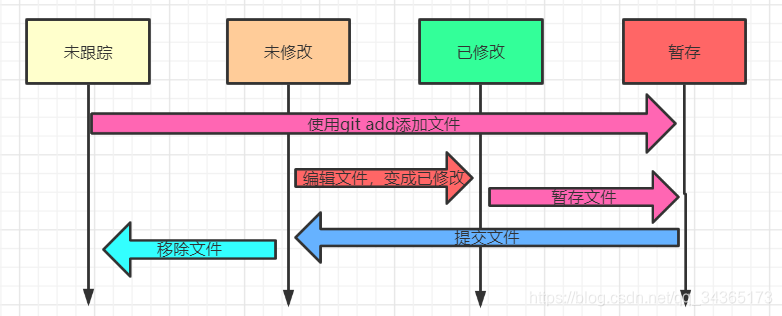
2: Query submission history
git log to view all commit records
git show to view the details of the submission
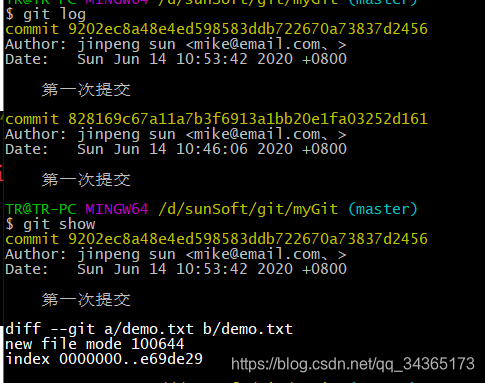
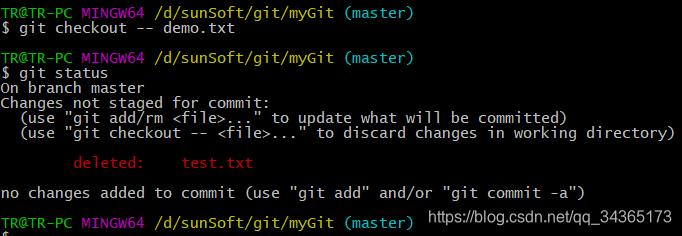
3: Undo the update
git checkout-filename to undo the modification
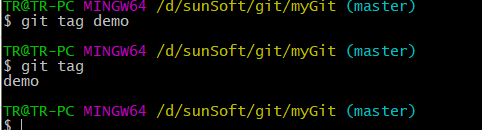
4: Tagging
git tag tagName can create new tags. The
git tag command can list all tags.
Here are only some simple operations and uses, and there are other uses. You can go to Git official website or Baidu to find out. Official website address: Git official website