Article Directory
Preface
Today, my friend asked in the group if there is any free software for converting recordings to text? I searched the Internet and found that most of the Internet charges are over a certain period of time, and my friend’s audio is more, which adds up to a few hours, so I wondered if I could call the interface and implement this function with python.

The picture above is the audio-to-text function of an online platform. You can see that the extra time charges are also more expensive.
Because I learned that Xunfei mainly does this, I chose Xunfei's development platform.
Specific process
1. Create an application on the open platform of Xunfei
Go to the official website of iFLYTEK Open Platform,
register and log in, click on Voice Transcribing
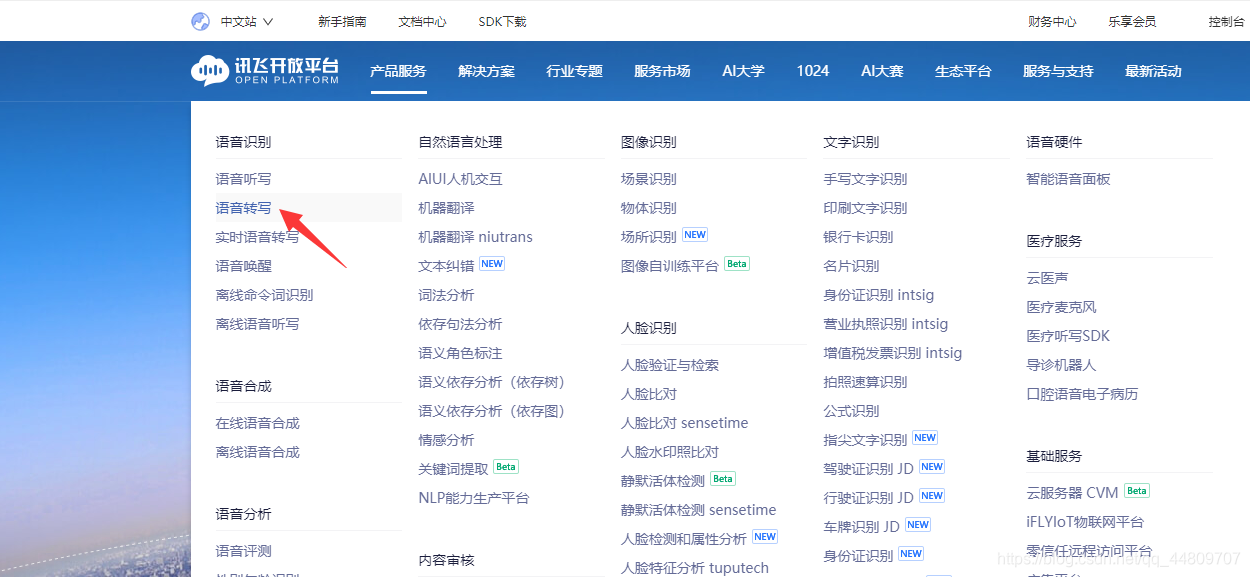
and then click on the console to create an application.
After creation, you will get the APPID and key (this code will be used).
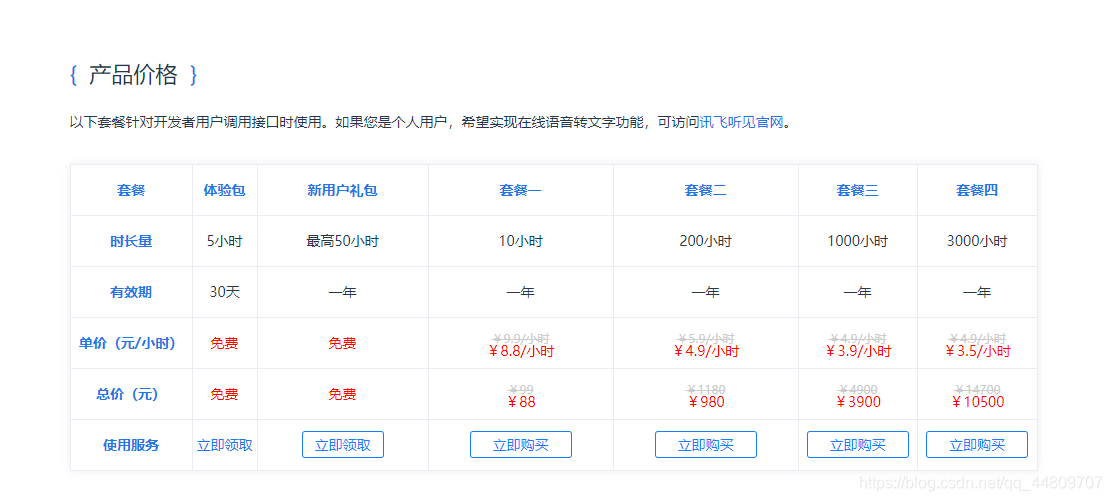
After creating the application, we can receive the 5-hour experience package first.
2. Code example
Find the development document, there are code examples.

I used the python example and changed the code as required.
# -*- coding: utf-8 -*-
#
# author: yanmeng2
#
# 非实时转写调用demo
import base64
import hashlib
import hmac
import json
import os
import time
import re
import requests
lfasr_host = 'http://raasr.xfyun.cn/api'
# 请求的接口名
api_prepare = '/prepare'
api_upload = '/upload'
api_merge = '/merge'
api_get_progress = '/getProgress'
api_get_result = '/getResult'
# 文件分片大小10M
file_piece_sice = 10485760
# ——————————————————转写可配置参数————————————————
# 参数可在官网界面(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看,根据需求可自行在gene_params方法里添加修改
# 转写类型
lfasr_type = 0
# 是否开启分词
has_participle = 'false'
has_seperate = 'true'
# 多候选词个数
max_alternatives = 0
# 子用户标识
suid = ''
class SliceIdGenerator:
"""slice id生成器"""
def __init__(self):
self.__ch = 'aaaaaaaaa`'
def getNextSliceId(self):
ch = self.__ch
j = len(ch) - 1
while j >= 0:
cj = ch[j]
if cj != 'z':
ch = ch[:j] + chr(ord(cj) + 1) + ch[j + 1:]
break
else:
ch = ch[:j] + 'a' + ch[j + 1:]
j = j - 1
self.__ch = ch
return self.__ch
class RequestApi(object):
def __init__(self, appid, secret_key, upload_file_path):
self.appid = appid
self.secret_key = secret_key
self.upload_file_path = upload_file_path
# 根据不同的apiname生成不同的参数,本示例中未使用全部参数您可在官网(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看后选择适合业务场景的进行更换
def gene_params(self, apiname, taskid=None, slice_id=None):
appid = self.appid
secret_key = self.secret_key
upload_file_path = self.upload_file_path
ts = str(int(time.time()))
m2 = hashlib.md5()
m2.update((appid + ts).encode('utf-8'))
md5 = m2.hexdigest()
md5 = bytes(md5, encoding='utf-8')
# 以secret_key为key, 上面的md5为msg, 使用hashlib.sha1加密结果为signa
signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
file_len = os.path.getsize(upload_file_path)
file_name = os.path.basename(upload_file_path)
param_dict = {
}
if apiname == api_prepare:
# slice_num是指分片数量,如果您使用的音频都是较短音频也可以不分片,直接将slice_num指定为1即可
slice_num = int(file_len / file_piece_sice) + (0 if (file_len % file_piece_sice == 0) else 1)
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['file_len'] = str(file_len)
param_dict['file_name'] = file_name
param_dict['slice_num'] = str(slice_num)
elif apiname == api_upload:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['slice_id'] = slice_id
elif apiname == api_merge:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['file_name'] = file_name
elif apiname == api_get_progress or apiname == api_get_result:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
return param_dict
# 请求和结果解析,结果中各个字段的含义可参考:https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html
def gene_request(self, apiname, data, files=None, headers=None):
response = requests.post(lfasr_host + apiname, data=data, files=files, headers=headers)
result = json.loads(response.text)
if result["ok"] == 0:
if apiname=='/getResult':
results=re.findall(r"\"onebest\":\"(.+?)\",",result['data'])
print(results)
upload_file_path = self.upload_file_path
with open(str(upload_file_path)+".txt", "a", encoding='utf-8') as f:
for i in results:
f.write(i)
print("{} success:".format(apiname) + str(result))
return result
else:
print("{} error:".format(apiname) + str(result))
exit(0)
return result
# 预处理
def prepare_request(self):
return self.gene_request(apiname=api_prepare,
data=self.gene_params(api_prepare))
# 上传
def upload_request(self, taskid, upload_file_path):
file_object = open(upload_file_path, 'rb')
try:
index = 1
sig = SliceIdGenerator()
while True:
content = file_object.read(file_piece_sice)
if not content or len(content) == 0:
break
files = {
"filename": self.gene_params(api_upload).get("slice_id"),
"content": content
}
response = self.gene_request(api_upload,
data=self.gene_params(api_upload, taskid=taskid,
slice_id=sig.getNextSliceId()),
files=files)
if response.get('ok') != 0:
# 上传分片失败
print('upload slice fail, response: ' + str(response))
return False
print('upload slice ' + str(index) + ' success')
index += 1
finally:
'file index:' + str(file_object.tell())
file_object.close()
return True
# 合并
def merge_request(self, taskid):
return self.gene_request(api_merge, data=self.gene_params(api_merge, taskid=taskid))
# 获取进度
def get_progress_request(self, taskid):
return self.gene_request(api_get_progress, data=self.gene_params(api_get_progress, taskid=taskid))
# 获取结果
def get_result_request(self, taskid):
return self.gene_request(api_get_result, data=self.gene_params(api_get_result, taskid=taskid))
def all_api_request(self):
# 1. 预处理
pre_result = self.prepare_request()
taskid = pre_result["data"]
# 2 . 分片上传
self.upload_request(taskid=taskid, upload_file_path=self.upload_file_path)
# 3 . 文件合并
self.merge_request(taskid=taskid)
# 4 . 获取任务进度
while True:
# 每隔20秒获取一次任务进度
progress = self.get_progress_request(taskid)
progress_dic = progress
if progress_dic['err_no'] != 0 and progress_dic['err_no'] != 26605:
print('task error: ' + progress_dic['failed'])
return
else:
data = progress_dic['data']
task_status = json.loads(data)
if task_status['status'] == 9:
print('task ' + taskid + ' finished')
break
print('The task ' + taskid + ' is in processing, task status: ' + str(data))
# 每次获取进度间隔20S
time.sleep(20)
# 5 . 获取结果
self.get_result_request(taskid=taskid)
# 注意:如果出现requests模块报错:"NoneType" object has no attribute 'read', 请尝试将requests模块更新到2.20.0或以上版本(本demo测试版本为2.20.0)
# 输入讯飞开放平台的appid,secret_key和待转写的文件路径
if __name__ == '__main__':
api = RequestApi(appid="", secret_key="", upload_file_path=r"")
api.all_api_request()
3. Code description
Three places need to be added to use the above code.
Use your own appid and key in the penultimate line of the code, and the file path is the audio file path.
4. Test results
Above is my file directory (audio duration is about fifty minutes).

The above is the generated TXT text.

The duration of the experience package has also been deducted, but 5 hours is enough (new users can claim up to 50 hours).