Article Directory
Summary
This article will introduce some detection benchmark data sets (also known as detection benchmarks) of generic object detection.
Concept supplement:
benchmark : Its Chinese name is benchmark. I think benchmark is a standard for comparing different scientific research results in a certain industry, and it can give a more general understanding of the performance improvement brought by a certain scientific research result. In the field of target detection, benchmark includes data sets and evaluation indicators. Researchers test the results of scientific research on the benchmark data set, and then measure the work according to a common indicator, so as to know whether the work is progressing or what progress has been made. .
baseline : Sometimes we will see the term baseline in papers, which usually refers to methods proposed by other papers. So my understanding is to test the four ABCD models in an experiment with benchmark data, and then use the worst-case model, assuming C, as the baseline, to see how much other models have improved relative to C.
1. The benchmark for general target detection
1.1 Benchmark data set
-
Pascal VOC2007 is a medium-scale data set in object detection, with a total of 20 categories. The data is divided into three parts: training, verification and testing. Each part contains 2501, 2510 and 5011 pictures.
-
Pascal VOC2012 is a medium-sized data set for object detection, which has the same 20 categories as Pascal VOC2007. The data is divided into three parts: training, verification and testing. Each part contains 5717, 5823, and 10,991 images. The VOC2012 test set has no annotations. For a detailed introduction of the VOC data set, please see another article of mine. Object detection data set PASCAL VOC notes
-
MSCOCO is a large-scale data set with 80 categories. The data is divided into three parts: training, verification and testing. Each part contains 118287, 5000 and 40670 pictures respectively. The test data set has no label information.
-
Pascal Open Images contains 1.9M images, 15 million objects, and 600 categories. Among them, the 500 most frequent types are used as target detection benchmarks, and more than 70% of these 500 types have more than 1,000 samples.
-
LVIS is a newly collected benchmark containing 164,000 images and more than 1,000 categories.
-
ImageNet is also an important data set with 200 categories. However, the scale of the landscape is very large, but the scale range of the target is similar to the VOC data set, so it is usually not necessary to do the benchmark data set for target detection. However, the backbone of the target detection model is still using a large number of models pre-trained using ImageNet.
Sample example of the above data set:

1.2 Evaluation indicators:
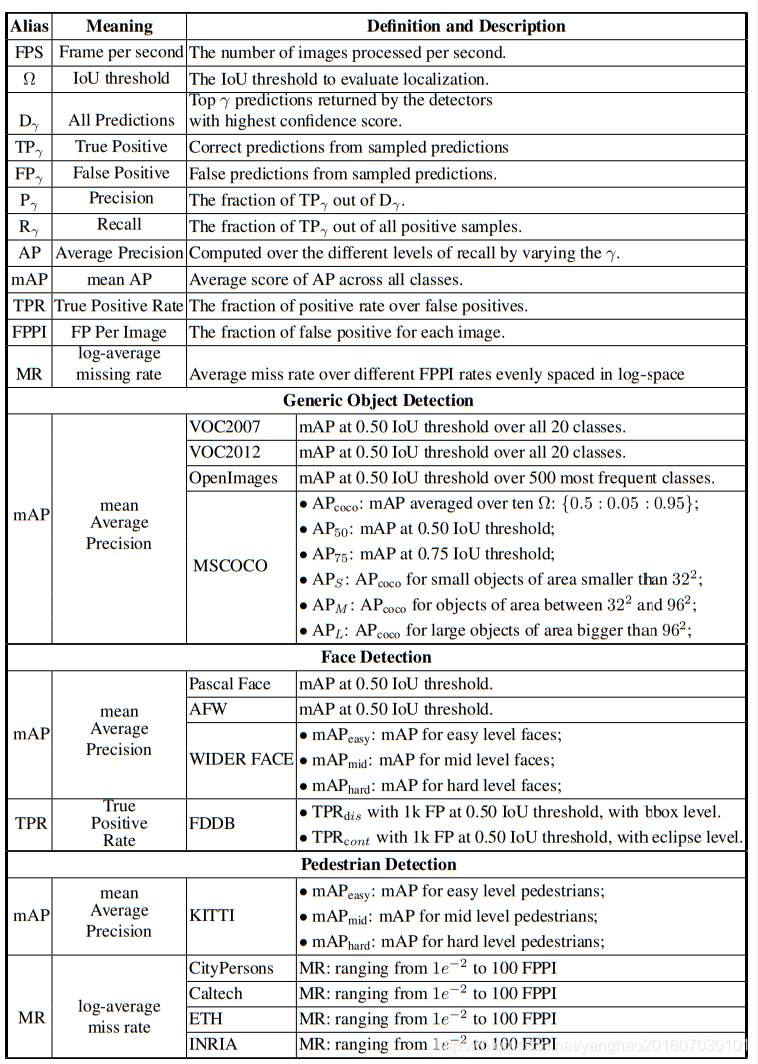
The target detection algorithm uses detection accuracy and inference time as evaluation indicators.
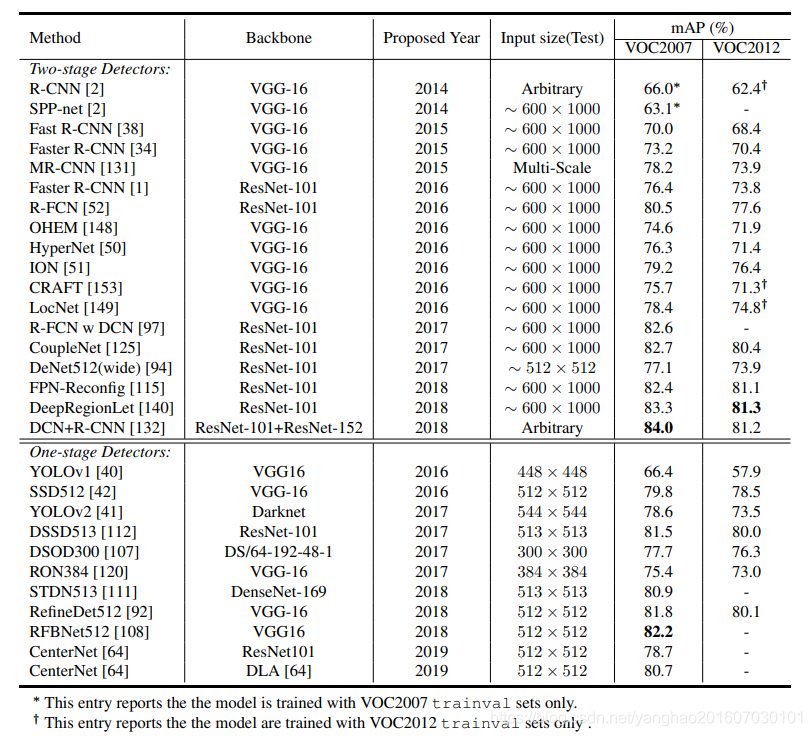
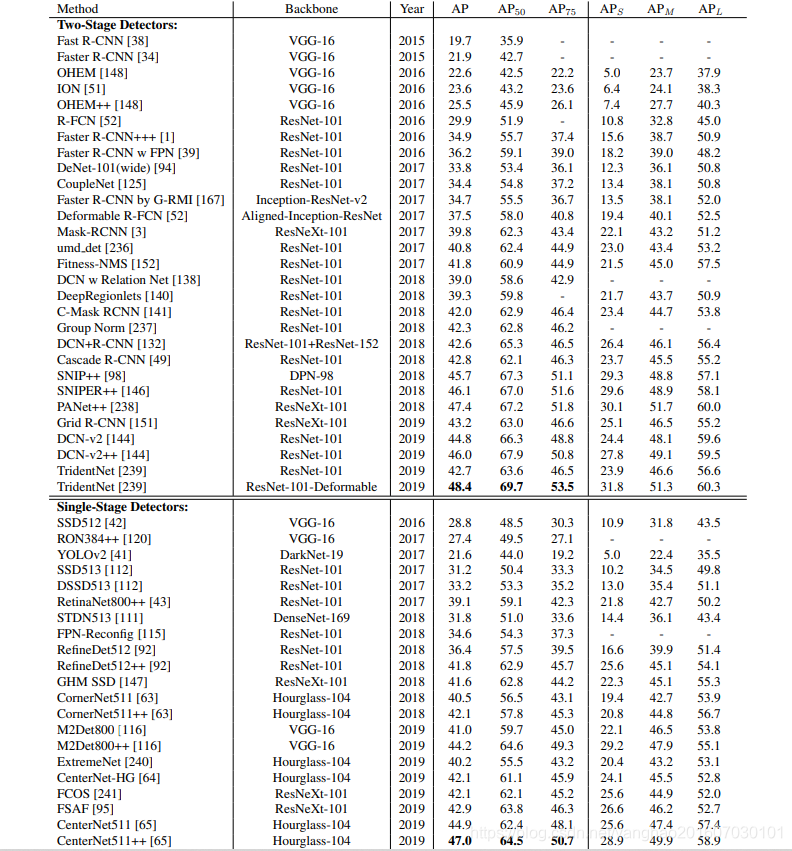
For detection accuracy, mean Average Precision (mAP) is used as the evaluation index on these benchmark data sets. For VOC2012, VOC2007 and ImageNet, the IoU threshold of mAP is set to 0.5, while MSCOCO uses a more comprehensive evaluation index, with a total of 6 evaluation scores corresponding to its evaluation indexes on different IoU thresholds and different target scales. For details, please refer to the table below.
Pascal VOC2007, VOC2007 and MSCOCO are the three most commonly used data sets for evaluating detection algorithms.
Each image of Pascal VOC2012 and VOC2007 has a mesoscale data set of 2-3 targets, and the size range of the targets in the VOC data set is not large. For MSCOCO, each image has nearly 10 targets, and most of the targets are small targets in a large-scale range, which brings great challenges to the detection algorithm. In Table 3 and Table 2, we give the benchmarks of VOC2007, VOC2012 and MSCOCO in recent years.