
The Scrapy web crawler framework not only provides the css() method (method) shared in the article [Scrapy tutorial 4] mastering the important CSS positioning element method of the Scrapy framework to locate the web element (Element), it also provides the xpath() positioning method ( Method) for developers to use.
XPath (XML Path Language) is a language that uses a syntax similar to archive paths to locate specific (nodes) in XML files. Because it can effectively find the location of nodes (nodes), it is also widely used on Python web pages. The element of the crawler is positioned.
This article will continue to use [Scrapy Tutorial 4] Master the important CSS positioning element method of the Scrapy framework . The Internet trend observation website of INSIDE in the article- AI News will be used to show you how to use the built-in xpath in the Scrapy framework. () Method (Method) to locate the content of the web page that you want to crawl. The key points include:
Scrapy XPath method to obtain a single element value
Scrapy XPath method to obtain multiple element values
Scrapy XPath method to obtain sub-element values
Scrapy XPath method to obtain element attribute values
One, Scrapy XPath method to obtain a single element value
First, open INSIDE's hard-cracked Internet trend observation website-AI news page, click the mouse shortcut in the article title, and select "Check", you can see the HTML source code as shown in the figure below:
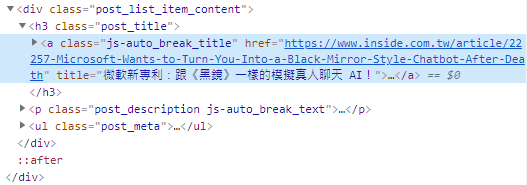
If you want to locate by XPath syntax The location of this tag has the same syntax as the file path, as in the following example:
// a [@ class ='js-auto_break_title']
It means the tag under the root directory, and use "[@ class ='']" to specify its style category (class), so that you can locate the tag of the article title.
Next, open the Scrapy web crawler project created by [Scrapy Tutorial 4] Mastering the important CSS positioning element method of the Scrapy framework . In the parse() method (Method) of spiders/inside.py, the result of the web page response ( response), call the xpath() method (Method) instead, and paste the XPath path just found, as in the following example:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回复。xpath (
“ // a [@ class ='js-auto_break_title'] / text()” )。得到()
打印(标题)
Then, use the following command to execute the inside web crawler:
$ scrapy爬进里面
Results of the
微软新专利:跟《黑镜》一样的模拟真人聊天AI!AI !
In line 11 of the above example, after using the XPath path to locate the tag to be crawled, since it is necessary to obtain the content of the web page, the keyword "/text()" needs to be added at the end of the XPath path, and call get () Method (Method) to obtain a single element value.
Second, the Scrapy XPath method to obtain multiple element values
If you want to use the Scrapy xpath() method (method) to obtain multiple element values, use the XPath path to locate the web page element tag to be crawled, and then call the getall() method (Method), as in the following example:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // a [@ class ='js-auto_break_title'] / text()” )。getall ()
打印(标题)
Results of the
[
'微软新专利:跟《黑镜》一样的模拟真人聊天AI!”, '微软新专利:跟《黑镜》一样的模拟真人聊天AI!” ,
'【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧“,'【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧“ ,
'2021台北电玩展以新形态亮相:虚实同步布局', “ 2021台北电玩展以新形态亮相:虚实同步布局” ,
“用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减”,“用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减” ,
“烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点“ breakie”,“ cakie””,“烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点“ breakie”,“ cakie”” ,
'她用数据战胜人性,主推近似课程一年后用户翻七倍','她用数据战胜人性,主推近似课程一年后用户翻七倍' ,
“【有线硬塞】你知道银河系的历史,已被重新改写了吗?”, “【有线硬塞】你知道银河系的历史,已被重新改写了吗?” ,
“祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年”,“祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年” ,
......
]]
As can be seen from the execution result, the getall() method (method) will return a list (List) containing all the label title texts whose style category (class) is "js-auto_break_title". Next, you need to return Circle to read, the following example:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // a [@ class ='js-auto_break_title'] / text()” )。getall ()
为标题在标题:
打印(标题)
Results of the
微软新专利:跟《黑镜》一样的模拟真人聊天AI!AI !
【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧【Arm专栏】一次看懂人工智慧:云端,边缘与终端人工智慧
2021台北电玩展以新形态亮相:虚实同步布局2021台北电玩展以新形态亮相:虚实同步布置
用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减
烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie」,「cakie」烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie 」,「cakie 」
她用数据战胜人性,主推疗法课程一年后用户翻七倍她用数据战胜人性,主推疗法课程一年后用户翻七倍
【有线硬塞】你知道银河系的历史,已被重新改写了吗?【有线硬塞】你知道银河系的历史,已被重新改写了吗?
2020年过的好吗?盘点脸书满城风雨的一年祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年
......
The get() and getall() methods (methods) used in this article are the same as the [Scrapy tutorial 4] Mastering the important CSS positioning elements of the Scrapy framework article for the official new version of Scrapy, while the old version of extract_first() and extract() The method (method) is still supported according to the following official documents, but it is still recommended that readers can use the new version of the method (method) to work closely with each other.

Third, the Scrapy XPath method to obtain the value of the child element.
When developing a Python web crawler, there is a very common chance that you need to locate the child element (Element) to be crawled through a layer-by-layer method. At this time, the Scrapy xpath() method In (Method), the replaced XPath takes the HTML source code of the tag as an example, as shown in the figure below:

Suppose we want to
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // div [@ class ='post_list_item_content'] / h3 [@ class ='post_title'] / a / text()” )。getall ()
为标题在标题:
打印(标题)
Results of the
微软新专利:跟《黑镜》一样的模拟真人聊天AI!AI !
【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧【Arm专栏】一次看懂人工智慧:云端,边缘与终端人工智慧
2021台北电玩展以新形态亮相:虚实同步布局2021台北电玩展以新形态亮相:虚实同步布置
用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减
烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie」,「cakie」烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie 」,「cakie 」
她用数据战胜人性,主推疗法课程一年后用户翻七倍她用数据战胜人性,主推疗法课程一年后用户翻七倍
【有线硬塞】你知道银河系的历史,已被重新改写了吗?【有线硬塞】你知道银河系的历史,已被重新改写了吗?
2020年过的好吗?盘点脸书满城风雨的一年祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年
......
Four, Scrapy XPath method to get element attribute value
In addition to crawling the content displayed on the web page, the Python web crawler can also obtain the attribute value of the web page element (element), which means that, for example, the src source attribute value of the image or the href URL attribute value of the hyperlink, etc., at this time , You need to add "@attribute name" at the end of the xpath() method (method) of the Scrapy framework, as shown in the following example:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // a [@ class ='js-auto_break_title'] / @ href” )。getall ()
为标题在标题:
打印(标题)
Results of the
https://www.inside.com.tw/article/22257-Microsoft-Wants-to-Turn-You-In-a-Black-Mirror-Style-Chatbot-After-Death://www.inside.com.tw/article/22257-Microsoft-Wants-to-Turn-You-to-a-Black-Mirror-Style-Chatbot-After-Death
https://www.inside.com.tw/article/22234-arm-AI-explained://www.inside.com.tw/article/22234-arm-AI-explained
https://www.inside.com.tw/article/22254-2021-TGS://www.inside.com.tw/article/22254-2021-TGS
https://www.inside.com.tw/article/22208-artificial-intelligence-finds-hidden-roads-threatening-amazon-ecosystems://www.inside.com.tw/article/22208-artificial-intelligence-finds-hidden-roads-threatening-amazon-ecosystems
https://www.inside.com.tw/article/22196-google-ai-concocts-breakie-and-cakie-hybrid-baked-goods://www.inside.com.tw/article/22196-google-ai-concocts-breakie-and-cakie-hybrid-baked-goods
https://www.inside.com.tw/article/22222-sofasoda-growth-in-tech-2021://www.inside.com.tw/article/22222-sofasoda-growth-in-tech-2021
https://www.inside.com.tw/article/22194-The-Milky-Way-Gets-a-New-Origin-Story://www.inside.com.tw/article/22194-The-Milky-Way-Gets-a-New-Origin-Story
https://www.inside.com.tw/article/22057-Mark-Zuckerberg-and-fb-2020://www.inside.com.tw/article/22057-Mark-Zuckerberg-and-fb-2020
......
The above example is to crawl all the tag href attribute values of the style category (class) "js-auto_break_title", which is the URL of the article title.
V. Summary
This article simply demonstrates another method of locating elements in the Scrapy framework
To obtain a single element value, call the get() method (method) to
obtain multiple element values, call the getall() method (method) to
obtain the text content, add the "/ text()" keyword to
obtain the attribute value, then add "@attribute name" Keywords
You can try to practice using the Scrapy xpath() method (method) shared here, and the css() method (method) of the article [Scrapy Tutorial 4] Master the important CSS positioning element method of the Scrapy framework , to crawl ideas I believe that friends who want to get started with the Scrapy framework to develop Python web crawlers can quickly get started with the required web content.