1. Flume overview
1.1 Flume definition and role
Flume is a highly available, highly reliable, distributed mass log collection, aggregation, and transmission
system provided by Cloudera . Flume is based on a streaming architecture, which is flexible and simple.
Flume can only transfer text files, not pictures.
Flume's biggest role is to improve the real-time performance of the data stream.

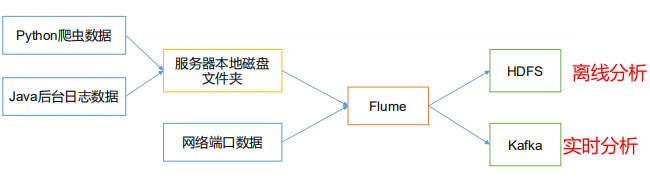
The main function of Flume is to read the data from the server's local disk in real time and write the data to HDFS
1.2Flume's infrastructure
The structure of Flume is shown in the figure



1.2.1 Agent
Agent is a JVM process, which sends data from the source to the destination in the form of events.
Agent mainly consists of 3 parts, Source, Channel, and Sink.
1.2.2 Source
Source is the component responsible for receiving data to Flume Agent. The Source component can process
log data of various types and formats, including avro (Apollo) , thrift, exec , jms, spooling directory, netcat , sequence
generator, syslog, http, legacy.
More used source

1.2.3 Sink
Sink continuously polls the events in the Channel and removes them in batches, and writes these events to the storage
or indexing system in batches , or sends them to another Flume Agent.
Sink component destinations include hdfs , logger , avro , thrift, ipc, file , HBase , solr, and self-
defined.
1.2.4 Channel
Channel is a buffer between Source and Sink. Therefore, Channel allows Source and Sink
to operate at different rates. Channel is thread-safe and can handle several Source write operations and several
Sink read operations at the same time .
Flume comes with two Channels: Memory Channel and File Channel and Kafka Channel.
Memory Channel is a queue in memory. Memory Channel is suitable for scenarios where you don't need to care about data loss
. If you need to be concerned about data loss, then Memory Channel should not be used, because program death, machine
downtime or restart will cause data loss.
File Channel writes all events to disk. Therefore, no data will be lost when the program is closed or the machine is down
.
1.2.5 Event
transmission unit, the basic unit of Flume data transmission, sends data from the source to the destination in the form of Event.
Event is composed of Header and Body. Header is used to store some attributes of the event, which is a KV structure, and
Body is used to store the data in the form of a byte array.

2. Flume Quick Start
2.1 Flume installation and deployment
2.1.1 Installation address
1) Flume official website address
http://flume.apache.org/
2) Document viewing address
http://flume.apache.org/FlumeUserGuide.html
3) Download address
http:// archive.apache.org/dist/flume/
2.1.2 Installation and deployment
1) Upload apache-flume-1.7.0-bin.tar.gz to the /opt/software directory of Linux
2) Unzip apache-flume-1.7. 0-bin.tar.gz to the /opt/module/ directory
[atguigu@hadoop102 software]$ tar -zxf apache-flume-1.7.0-
bin.tar.gz -C /opt/module/
3) Modify the name of apache-flume-1.7.0-bin to flume
[atguigu@hadoop102 module]$ mv apache-flume-1.7.0-bin flume
4) Change the flume-env.sh.template file under flume/conf Modify it to flume-env.sh and configure the flumeenv.sh file
[atguigu@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh
[atguigu@hadoop102 conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.2 Flume introductory case
2.2.1 Monitoring port data Official case
1) Case requirements:
Use Flume to monitor a port, collect the port data, and print it to the console.
2) Demand analysis:

3) Implementation steps:
1. Install netcat tool
[atguigu@hadoop102 software]$ sudo yum install -y nc
2. Determine whether port 44444 is occupied
[atguigu@hadoop102 flume-telnet]$ sudo netstat -tunlp | grep 44444
3. Create the Flume Agent configuration file flume-netcat-logger.conf Create a job folder in the flume directory and enter the job folder.
[atguigu@hadoop102 flume]$ mkdir job
[atguigu@hadoop102 flume]$ cd job/
Create the Flume Agent configuration file flume-netcat-logger.conf in the job folder.
[atguigu@hadoop102 job]$ vim flume-netcat-logger.conf
Add the following content to the flume-netcat-logger.conf file.
Note: The configuration file comes from the official manual http://flume.apache.org/FlumeUserGuide.html
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

One channel can be bound to multiple sinks, one sink can only be bound to one channel,
one channel can be bound to multiple sources, and one source can only be bound to multiple channels
. 4. First open the flume listening port
. The first way of writing:
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name
a1 --conf-file job/flume-netcat-logger.conf -
Dflume.root.logger=INFO,console
The second way of writing (recommended):
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f
job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
Parameter description:
–conf/-c: means that the configuration file is stored in the conf/ directory
–name/-n: means that the agent is named a1
–conf-file/-f: flume The configuration file read this time is in job The flume-telnet.conf
file in the folder. -Dflume.root.logger=INFO,console: -D means that when flume is running, dynamically modify the
parameter attribute value of flume.root.logger and set the console log printing level to INFO. Log levels include: log, info, warn,
error. 5. Use the netcat tool to send content to port 44444 of this machine
[atguigu@hadoop102 ~]$ nc localhost 44444
hello
atguigu
6. Observe the received data on the Flume monitoring page

3.Flume transaction

4. Internal Principles of Flume Agent

Important components:
1) ChannelSelector
The function of ChannelSelector is to select which Channel the Event will be sent to. There are two types, namely Replicating and Multiplexing.
ReplicatingSelector will send the same Event to all Channels, and Multiplexing will send different Events to different Channels according to the corresponding principles. 2) 2) SinkProcessor
SinkProcessor has three types, namely DefaultSinkProcessor, LoadBalancingSinkProcessor and FailoverSinkProcessor
DefaultSinkProcessor corresponds to a single Sink, LoadBalancingSinkProcessor and FailoverSinkProcessor correspond to Sink Group, LoadBaloverSinkProcessor can realize the function of load balancing. .
5.Flume topology
5.1 Simple series

This mode connects multiple flumes in sequence, starting from the initial source to the destination storage system for sink transmission. This mode does not recommend bridging too many flume quantities. Excessive flume quantities will not only affect the transmission rate, but also once a node flume goes down during the transmission process, it will affect the entire transmission system.
Copy and multiplex
5.2 Copy and multiplexing

Flume supports the flow of events to one or more destinations. In this mode, the same data can be copied to multiple channels, or different data can be distributed to different channels, and sinks can choose to transmit to different destinations.
5.3 Load balancing and failover
Solve the problem of excessive pressure on a single machine.
Agent1 is polled and distributed to agent2, agent3, and agent4.


Flume supports the use of logically grouping multiple sinks into a sink group. The sink group can be used with different SinkProcessors to achieve load balancing and error recovery.
5.4 Aggregation (recommended)


This model is our most common and very practical. Daily web applications are usually distributed on hundreds of servers, even thousands or tens of thousands of servers. The generated log is also very troublesome to process. This combination of flume can solve this problem well. Each server deploys a flume to collect logs, transfers to a centralized collection of logs flume, and then uploads this flume to hdfs, hive, hbase, etc. for log analysis.
5.5 In a production environment: aggregation + load balancing

6. Custom Interceptor (Interceptor)
Implementation step
1. Create a maven project and introduce the following dependencies.
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.7.0</version>
</dependency>
2. Define the CustomInterceptor class and implement the Interceptor interface.
package com.atguigu.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
public class CustomInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
if (body[0] < 'z' && body[0] > 'a') {
event.getHeaders().put("type", "letter");
} else if (body[0] > '0' && body[0] < '9') {
event.getHeaders().put("type", "number");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new CustomInterceptor();
}
@Override
public void configure(Context context) {
}
} }
3. Edit flume configuration file
Configure 1 netcat source, 1 sink group (2 avro sink) for Flume1 on hadoop102, and configure the corresponding ChannelSelector and interceptor.
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =
com.atguigu.flume.interceptor.CustomInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = type
a1.sources.r1.selector.mapping.letter = c1
a1.sources.r1.selector.mapping.number = c2
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop103
a1.sinks.k1.port = 4141
a1.sinks.k2.type=avro
a1.sinks.k2.hostname = hadoop104
a1.sinks.k2.port = 4242
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Use a channel which buffers events in memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
Configure an avro source and a logger sink for Flume2 on hadoop103.
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop103
a1.sources.r1.port = 4141
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1
Configure an avro source and a logger sink for Flume3 on hadoop104.
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop104
a1.sources.r1.port = 4242
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1
4. Start the flume process on hadoop102, hadoop103, and hadoop104 respectively, paying attention to the order.
5. Use netcat in hadoop102 to send letters and numbers to localhost:44444.
6. Observe the logs printed by hadoop103 and hadoop104.
7. Customize Source
Source is the component responsible for receiving data to Flume Agent. The Source component can process log data of various types and formats, including avro, thrift, exec, jms, spooling directory, netcat, sequence generator, syslog, http, legacy. There are many types of sources officially provided, but sometimes they cannot
meet the needs of actual development. At this time, we need to customize some sources according to actual needs. The official also provides a custom source interface:
https://flume.apache.org/FlumeDeveloperGuide.html#source According to the official instructions, customizing MySource needs to inherit the AbstractSource class and implement the Configurable and PollableSource interfaces.
The respective method is:
getBackOffSleepIncrement () // temporarily with
getMaxBackOffSleepInterval () // temporarily with
configure (Context context) // initialize the context (the contents read configuration files)
Process () // Get event data package into and write channel, the The method will be called cyclically.
Usage scenarios: Read MySQL data or other file systems.
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
8. Custom Sink
9.Flume data flow monitoring
3.8.1 Ganglia installation and deployment
10.Flume docking with Kafka
With flume, you can directly connect to hdfs, why does spark need flume->kafka->spark:
flume sink cannot be dynamically increased for use by multiple business lines, kafka consumption can dynamically increase consumers, and there is no need to increase copies.
1)配置 flume(flume-kafka.conf)
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /opt/module/data/flume.log
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2) Start the kafkaIDEA consumer
3) Enter the root directory of flume and start flume
$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf
4) Add data to /opt/module/data/flume.log to view the consumption of kafka consumers
$ echo hello >> /opt/module/data/flume.log
11. Real enterprise interview questions (emphasis)


