What papers and libraries will detonate the machine learning community in 2020? Which models and methods have topped the benchmark rankings in various fields? This article gives you the answer.
Almost Human reports, Author: Turre
The extraordinary 2020 is finally over! This year, due to the impact of the new crown pneumonia epidemic, major academic conferences such as CVPR, ICLR, and NeurIPS were changed to online. However, researchers and developers in the machine learning community did not stop and still contributed many important research findings.
Not long ago, the resource website Papers with Code published a summary of the Top 10 papers, libraries, and benchmarks in 2020, covering many fields such as natural language processing, image classification, target detection, semantic segmentation, instance segmentation, pose estimation, pedestrian re-recognition, and so on.

Top 10 popular papers
论文 1:EfficientDet: Scalable and Efficient Object Detection

Link to the paper: https://arxiv.org/pdf/1911.09070v7.pdf
Introduction: The first edition of this paper was originally published in November 2019. The heart of the machine reported on it . This article is the latest edition. Researchers at Google Brain discussed the efficiency of models in the field of computer vision, respectively proposed a weighted two-way feature pyramid network and a composite zoom method, and then developed a new EfficientDet target detector to achieve a new level of SOTA. This article was accepted by the CVPR 2020 conference.
论文 2:Fixing the train-test resolution discrepancy

Link to the paper: https://arxiv.org/pdf/2003.08237v5.pdf
Introduction: FixRes (Fixing Resolution) is a method that can improve the performance of any model. It can be used as a fine-tuning step after convolution training during several epochs, so it has a very high flexibility. FixRes can also be easily integrated into any existing training pipeline. FAIR researchers combined the FixRes method with the SOTA model EfficientNet, and proposed a new architecture FixEfficientNet, and achieved a top-1 accuracy rate of 88.5% on the ImageNet data set, achieving the SOTA performance at the time.
Paper 3: ResNeSt: Split-Attention Networks

Link to the paper: https://arxiv.org/pdf/2004.08955v2.pdf
Introduction: Researchers from Facebook, University of California, Davis, ByteDance and other institutions have proposed a modular Split-Attention block that can divide attention into several feature map groups. Stacking these Split-Attention blocks in the style of ResNet, they get a new variant of ResNet called ResNeSt . Among them, ResNeSt-50 achieved a top-1 accuracy rate of 81.13% on the ImageNet data set, which is more than 1% higher than the previous best ResNet variant. This improvement is meaningful for downstream tasks such as target detection, instance segmentation, and semantic segmentation.
论文 4:Big Transfer (BiT): General Visual Representation Learning

Link to the paper: https://arxiv.org/pdf/1912.11370v3.pdf
Introduction: Researchers at Google Brain proposed the transfer learning model Big Transfer (BiT). BiT is a set of pre-trained image models: even if each class has only a small number of samples, it can achieve excellent performance on the new data set after migration. BiT achieved 87.5%, 99.4%, and 76.3% top-1 accuracy on the ILSVRC-2012, CIFAR-10, and Visual Task Adaptation Benchmark (VTAB) data sets containing 19 evaluation tasks, respectively; on small data sets, BiT also achieved top-1 accuracy rates of 76.8% and 97.0% on the ILSVRC-2012 and CIFAR-10 data sets of 10 samples per class, respectively. This article was accepted by the ECCV 2020 conference.
论文 5:Object-Contextual Representations for Semantic Segmentation

Link to the paper: https://arxiv.org/pdf/1909.11065v5.pdf
Introduction: Researchers from the Institute of Computing Technology of the Chinese Academy of Sciences, Microsoft Asia Research and other institutions aim to solve the problem of semantic segmentation and focus on context aggregation strategies. They proposed a simple but effective method of object-contextual representation (OCR), which uses the representation of the corresponding object class to describe pixel features. Experimental results show that the OCR method proposed in this paper achieves quite good performance on a variety of challenging semantic segmentation benchmarks such as Cityscapes, ADE20K and PASCAL-Context. This article was accepted by the ECCV 2020 conference.
论文 6:Self-training with Noisy Student improves ImageNet classification

Link to the paper: https://arxiv.org/pdf/1911.04252v4.pdf
Description: Almost Human in November 2019 for the v1 version of the paper carried a report, this is the v2 version. Researchers at Google Brain and Carnegie Mellon University have proposed a semi-supervised learning method, Noisy Student Training, which works well when the annotation data is sufficient. Experimental results show that Noisy Student Training achieves an accuracy of 88.4% on the ImageNet dataset, which is 2.0% higher than the SOTA model that requires 3.5 billion (3.5B) weakly labeled Ins images. In the robustness test set, Noisy Student Training improved the top-1 accuracy of ImageNet-A from 61.0% to 83.7%, reduced the mean corruption error (MCR) of ImageNet-C from 45.7 to 28.3, and reduced ImageNet-A's mean corruption error (MCR) to 28.3. The mean flip rate (MFR) of -P has been reduced from 27.8 to 12.2. This article was accepted by the CVPR 2020 conference.
论文 7:YOLOv4: Optimal Speed and Accuracy of Object Detection

Link to the paper: https://arxiv.org/pdf/2004.10934v1.pdf
Introduction: In April 2020, YOLOv4 was open sourced on YOLO's official Github , which quickly attracted the attention of the CV community. The researcher compared YOLOv4 with the current best target detector and found that YOLOv4 achieves the same performance as EfficientDet, the speed is twice that of EfficientDet! In addition, compared with YOLOv3, the new version of AP and FPS have increased by 10% and 12%, respectively.
论文 8:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

Link to the paper: https://arxiv.org/pdf/2010.11929.pdf
Introduction: Researchers at Google Brain are inspired by the success of Transformer scaling in the field of NLP, and try to apply standard Transformers directly to images with minimal modification as much as possible. They proposed a new Vision Transformer (ViT) model , and achieved performance close to or even better than the current SOTA method on multiple image recognition benchmarks.
论文 9:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer

Link to the paper: https://arxiv.org/pdf/1910.10683v3.pdf
Introduction: Google researchers have explored the transfer learning method of natural language processing (NLP) by introducing a unified framework that converts all text-based language problems into text-to-text format. They proposed a new Text-to-Text Transfer Transformer (T5) model with a maximum of 11 billion parameters. The T5 model implements new SOTA on 17 NLP tasks covering summary generation, question answering, and text classification. In addition, the researchers open sourced the new Colossal Clean Crawled Corpus (C4) corpus, which contains hundreds of gigabytes of clean English text crawled from the Internet.
论文 10:Hierarchical Multi-Scale Attention for Semantic Segmentation

Link to the paper: https://arxiv.org/pdf/2005.10821v1.pdf
Introduction: Multi-scale inference is often used to improve the results of semantic segmentation. Researchers at Nvidia have proposed a hierarchical attention mechanism through which the network can learn to predict the relative weight between adjacent scales. The researchers tested the effect of the hierarchical attention mechanism on two datasets, Cityscapes and Mapillary Vistas. Among them, on the Cityscapes dataset with a large number of weakly labeled images, they also introduced an automatic labeling method to improve generalization performance. Experimental results show that the hierarchical multi-scale attention mechanism has achieved SOTA results, achieving 61.1% mIOU on Mapillary and 85.1% mIOU on Cityscapes.
Top 10 popular libraries
Transformers

Project address: https://github.com/huggingface/transformers
Introduction: The transformers library was created by the Hugging Face team to open up these NLP advances to the wider machine learning community. The library contains multiple well-designed SOTA Transformer architectures and uses a unified API. The transformers library brings together multiple pre-trained models built by the community and is open to the community. At present, the number of stars in the library is as high as 39.3k, and the transformers paper won the EMNLP 2020 Best Demo Paper Award .
PyTorch Image Models

Project address: https://github.com/rwightman/pytorch-image-models
Introduction: The pytorch-image-models library was created by Ross Wightman, a Canadian who is keen on building ML and AI systems. It contains image models, layers, utilities, optimizers, schedulers, data loader/amplification, inference training/validation Resources such as scripts. The library aims to integrate a variety of SOTA models to reproduce the training results on the ImageNet dataset. Currently, the number of stars in the library is 6.6k.
detectron2

Project address: https://github.com/facebookresearch/detectron2
Introduction: Detectron2 is a new generation software system of Facebook AI Research, which aims to realize SOTA target detection algorithm. The library was rewritten on the previous version of Detectron and contains all the model implementations of the maskrcnn-benchmark library (which has been deprecated). Currently, the number of stars in this library is as high as 14.5k.
insightface

Project address: https://github.com/deepinsight/insightface
Introduction: Insightface, created by the Deep Insight team, is an open source 2D and 3D deep face analysis toolbox, mainly based on the MXNet framework. The master branch of the library is suitable for MXNet 1.2-1.6 version and Python 3.x version. Currently, the star volume of the library is 8.4k.
imgclsmob

Project address: https://github.com/osmr/imgclsmob
Introduction: The imgclsmob library was created by senior software engineer Oleg Sémery, mainly researching convolutional networks for computer vision tasks. The library contains the realization or reproduction of various classification, segmentation, detection and pose estimation models and scripts for training, evaluation and conversion. Currently, the number of stars in this library is 2k.
DarkNet

Project address: https://github.com/pjreddie/darknet
Introduction: The darknet library was created by Joseph Redmon, who specializes in computer vision research. It is an open source neural network framework based on C language and CUDA. It is quick and easy to install, and supports CPU and GPU computing. Currently, the number of stars in this library is as high as 19.8k.
PyTorchGAN

Project address: https://github.com/eriklindernoren/PyTorch-GAN
Introduction: The PyTorchGAN library was created by Erik Linder-Norén, an ML engineer at Apple, and collected various PyTorch implementations of Generative Adversarial Networks (GAN) in the paper. The creator believes that the model architecture does not always reflect the views put forward in the paper, so he focuses on obtaining the core idea of the paper instead of just ensuring that each layer is configured correctly. Unfortunately, the library is outdated because the creator did not have time to maintain it. Currently, the star volume of the library is 8.4k.
MMDetection

Project address: https://github.com/open-mmlab/mmdetection
Introduction: MMDetection is an open source target detection toolbox based on PyTorch, created by the Multimedia Laboratory of the Chinese University of Hong Kong, and is part of the OpenMMLab project. The library started with the code base of the MMDet team (which won the 2018 COCO Challenge detection track), and then gradually developed into a unified platform covering many popular detection methods and modules. The library not only contains training and inference code, but also provides weights for more than 200 network models. Currently, the number of stars in this library is as high as 13.3k.
FairSeq

Project address: https://github.com/pytorch/fairseq
Introduction: Created by the PyTorch team, Fairseq is a sequence modeling toolkit that enables researchers and developers to train custom models for translation, abstract generation, language modeling, and other text generation tasks. Currently, the number of stars in this library is as high as 11k.
Gluon CV

Project address: https://github.com/dmlc/gluon-cv
Introduction: GluonCV was created by the Distributed Machine Learning Community (DMLC) to provide the implementation of SOTA deep learning models in the field of computer vision, aiming to enable engineers, researchers and students to quickly prototype products and research ideas based on these models. The library has the following main features: providing training scripts to reproduce the SOTA results of the paper; supporting PyTorch and MXNet; providing a large number of pre-trained models and a well-designed API that significantly reduces the implementation complexity; community support. Currently, the star volume of the library is 4.5k.
Top 10 popular benchmarks
Image classification benchmark on ImageNet dataset
The top-1 and top-5 accuracy rates are both the Meta Pseudo Labels semi-supervised learning method proposed by the Google Brain team. The top-1 accuracy rate is 90.2%, and the top-5 accuracy rate is 98.8. %.

- Base address: https://paperswithcode.com/sota/image-classification-on-imagenet
- Meta Pseudo Labels paper address: https://arxiv.org/pdf/2003.10580v3.pdf
Target detection benchmark on COCO test-dev dataset
The highest box AP value is the Cascade Eff-B7 NAS-FPN proposed by the Google Brain team, which achieved a mask AP of 49.1 and a box AP of 57.3 on the COCO instance segmentation task, which were 0.6 and 1.5 higher than the previous SOTA.
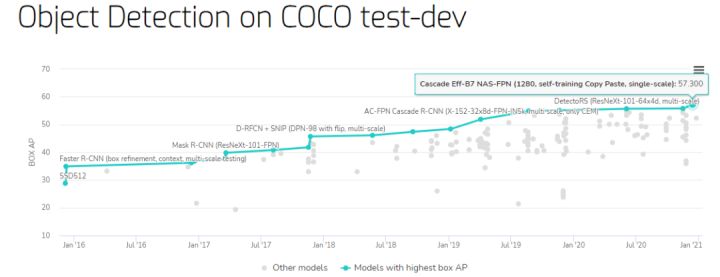
- Base address: https://paperswithcode.com/sota/object-detection-on-coco
- Cascade Eff-B7 NAS-FPN paper address: https://arxiv.org/pdf/2012.07177v1.pdf
Semantic segmentation benchmark on Cityscapes test dataset
The highest Mean IoU is HRNet-OCR (hierarchical multi-scale attention mechanism) proposed by Nvidia, which achieved an mIoU of 85.1% on the Cityscapes test data set.
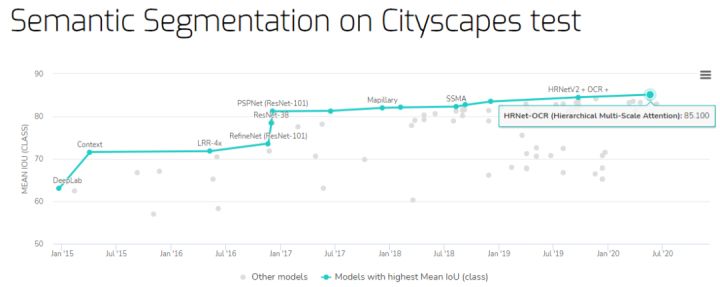
Base address: https://paperswithcode.com/sota/semantic-segmentation-on-cityscapes
- HRNet-OCR paper address: https://arxiv.org/pdf/2005.10821v1.pdf
Image classification benchmark on CIFAR-10 dataset
The Percentage Correct index ranked first is EffNet-L2 (SAM) proposed by Google Research Institute, which achieved a SOTA score of 99.7%.

- Base address: https://paperswithcode.com/sota/image-classification-on-cifar-10
- EffNet-L2 (SAM) paper address: https://arxiv.org/pdf/2010.01412v2.pdf
Image classification benchmark on CIFAR-100 dataset
The Percentage Correct index ranked first is still EffNet-L2 (SAM) proposed by Google Research, which achieved a SOTA score of 96.08%.

Base address: https://paperswithcode.com/sota/image-classification-on-cifar-100
Semantic segmentation benchmark on PASCAL VOC 2012 test dataset
The highest Mean IoU is the EfficientNet-L2+NAS-FPN proposed by the Google Brain team, which achieved a mIoU of 90.5% on the PASCAL VOC 2012 test data set.

- Base address: https://paperswithcode.com/sota/semantic-segmentation-on-pascal-voc-2012
- EfficientNet-L2+NAS-FPN paper address: https://arxiv.org/pdf/2006.06882v2.pdf
Pose estimation benchmark on MPII Human Pose dataset
The highest PCKH-0.5 is the Soft-gated Skip Connections proposed by Samsung AI Center, which achieved 94.1% of PCKH-0.5 on the MPII Human Pose dataset.

- Base address: https://paperswithcode.com/sota/pose-estimation-on-mpii-human-pose
- Soft-gated Skip Connections paper address: https://arxiv.org/pdf/2002.11098v1.pdf
Pedestrian re-identification benchmark on Market-1501 dataset
The highest mAP (Mean Average Precision) is the st-ReID proposed by Sun Yat-sen University in 2018. It achieved 95.5% mAP and 98.0% rank-1 accuracy on the Market-1501 data set, which are significantly better than the previous SOTA method.
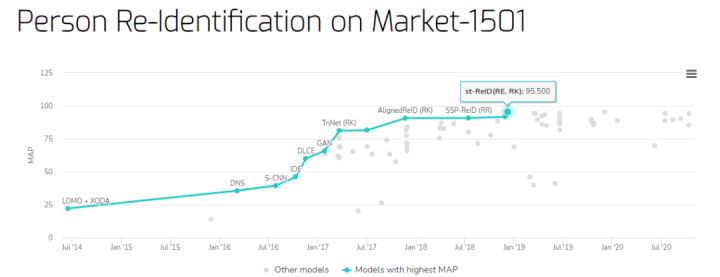
- Base address: https://paperswithcode.com/sota/person-re-identification-on-market-1501
- st-ReID paper address: https://arxiv.org/pdf/1812.03282v1.pdf
Image classification benchmark on the MNIST dataset
The highest accuracy rate is the Branching/Merging CNN + Homogeneous Filter Capsules proposed by Brunel University and Bradley University. It has achieved a SOTA accuracy rate of 99.84 on the MNIST data set, and the Percentage Error is also the lowest at 0.16%.

- Base address: https://paperswithcode.com/sota/image-classification-on-mnist
- Branching/Merging CNN + Homogeneous Filter Capsules Paper address: https://arxiv.org/pdf/2001.09136v4.pdf
3D human pose estimation benchmark on Human3.6M dataset
The Learnable Triangulation of Human Pose proposed by Samsung AI Center achieved the lowest Average MPJPE of 17.7 mm on this data set.
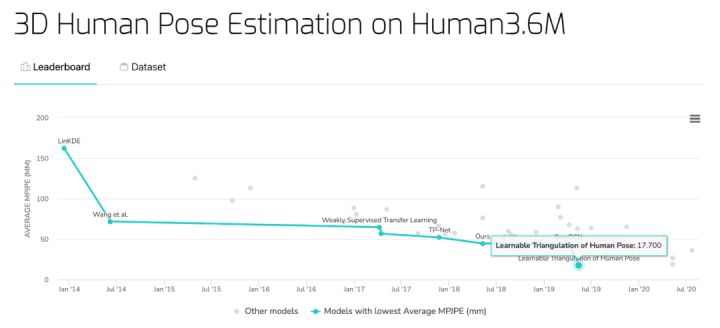
Base address: https://paperswithcode.com/sota/3d-human-pose-estimation-on-human36m
- Learnable Triangulation of Human Pose Paper address: https://arxiv.org/pdf/1905.05754v1.pdf
Reference link: https://medium.com/paperswithcode/papers-with-code-2020-review-938146ab9658
Published on 02-15