1. Distributed system design strategy
The essence of a distributed system is to get better throughput, performance, and availability through low-cost hardware.
In a distributed environment, there are several issues of general concern, which we call design strategies:
- How to detect that the current node is still alive?
- How to ensure high availability?
- Fault-tolerant processing
- Load balancing
1.1. Distributed system design strategy-heartbeat detection mechanism
In a distributed environment, we mentioned that there are a lot of nodes (Node), the essence of which is that these nodes share the task of running, computing or program logic processing. Then there is a very important question, how to detect that a node fails or even fails to work?
Usually to solve this problem is to adopt the method of heartbeat detection, just like some diagnosis of the patient through the instrument.
The heartbeat, as the name implies, is a way to report the current node status to other nodes at a fixed frequency. After receiving the heartbeat, it can generally be considered that a node and the current network topology are good. Of course, when the heartbeat is reported, it usually carries some additional status and metadata information for management
As shown in the figure, the Client requests the Server, and the Server forwards the request to the specific Node to obtain the request result. Server needs to maintain a heartbeat connection with the three Node nodes to ensure that the Node can work normally
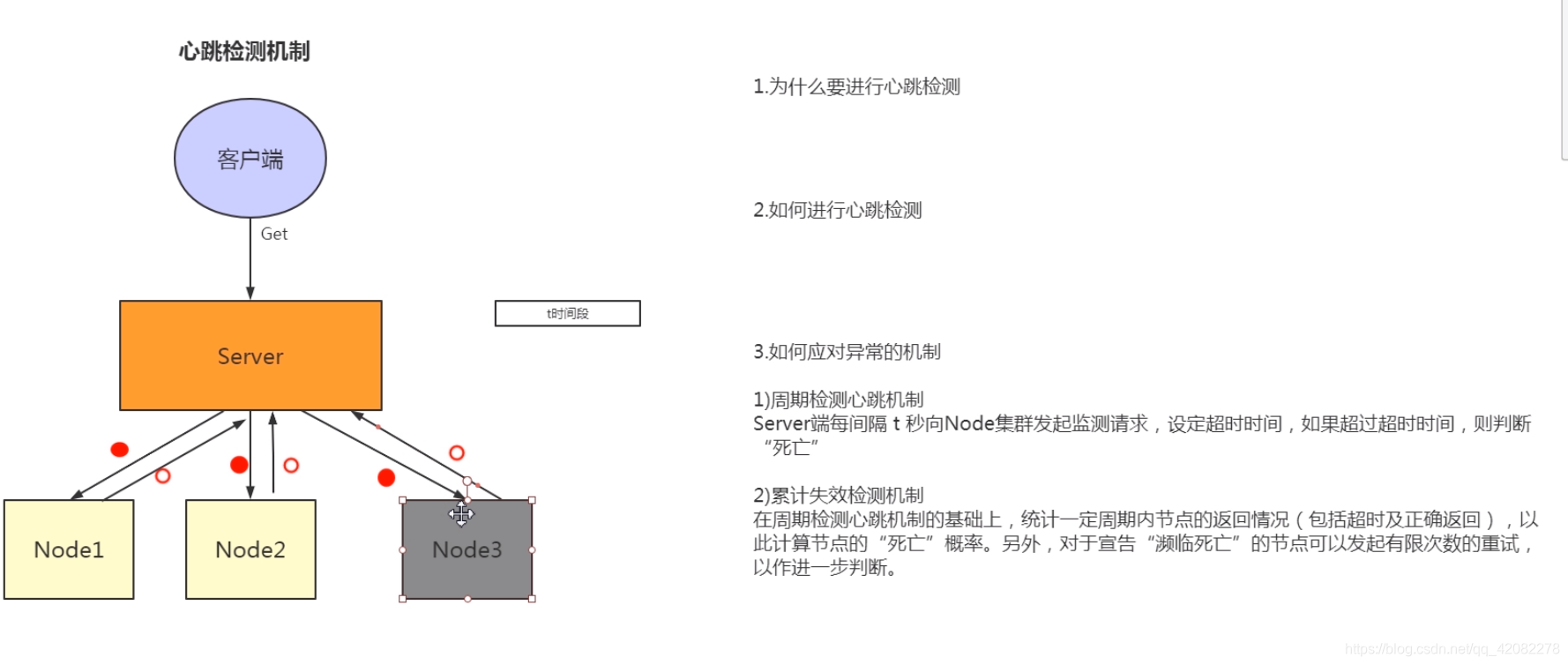
If the Server does not receive the heartbeat of Node3, the Server thinks that Node3 is disconnected. However, the loss of connection is a loss of contact, and it is not sure whether it is Node3 failure. It may be that Node3 is busy, causing the call detection to time out; it may also be that the link between Server and Node3 fails or is interrupted. Therefore, the heartbeat is not a panacea. Receiving the heartbeat can confirm that the node is normal, but if the heartbeat is not received, it cannot be considered that the node has declared "dead". At this point, some methods can be used to help Server make decisions: periodic detection of heartbeat mechanism, cumulative failure detection mechanism.
Periodic detection heartbeat mechanism The
server side initiates a monitoring request to the Node cluster every t seconds, and sets the timeout period. If the timeout period exceeds the timeout period, it is judged as "dead".
Cumulative failure detection mechanism
Based on the periodic detection heartbeat mechanism, the return status of the node in a certain period (including timeout and correct return) is counted to calculate the "death" probability of the node. In addition, a limited number of retries can be initiated for a node that declares "near death" for further judgment.
The periodic detection heartbeat mechanism and cumulative failure detection mechanism can help determine whether a node is "dead". If it is judged as "dead", the node can be kicked out of the cluster
1.2. Distributed system design strategy-high availability design
High Availability (High Availability) is one of the factors that must be considered in the design of the system architecture. It usually refers to the design to reduce the time that the system cannot provide services.
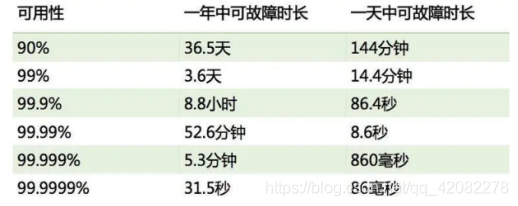
There are three common design patterns for system high availability: master-slave, active-active and cluster.
1.2.1 Active/Standby Mode
1. Active-Standby mode The active-standby mode is the Active-Standby mode. When the host is down, the standby machine takes over all the work of the host. After the host returns to normal, it can be automatically (hot standby) or manual (cold) according to the user's settings. (Standby) mode to switch the service to run on the host. In the database part, it is customary to call it MS mode. The MS mode is the Master/Slave mode, which is commonly used in database high availability solutions. For example, MySQL, Redis, etc. use the MS mode to achieve master-slave replication. Ensure high availability, as shown in the figure.
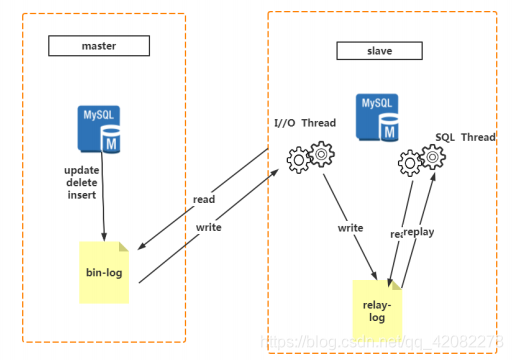
The basis of data replication between MySQL is the binary log file. Once the binary log is enabled for a MySQL database, as the master, all operations in its database will be recorded in the binary log in the form of "events". Other databases act as slaves to communicate with the master server through an I/O thread and monitor The master’s binary log file changes. If it finds that the master’s binary log file has changed, it will copy the changes to its own relay log, and then a SQL thread of the slave will execute the related "events" to its own database. In this way, the consistency of the slave database and the master database is realized, and the master-slave replication is realized
1.2.2 Mutual backup mode
Mutual backup mode Mutual backup mode means that two hosts run their own services at the same time and monitor each other. In the high-availability part of the database, the common mutual backup is the MM mode. The MM mode is the Multi-Master mode, which refers to the existence of multiple masters in a system, and each master has read-write capabilities, and merges versions based on timestamps or business logic.
Most of the MySQL services we have used and built are Single-Masters, and only one Master in the entire topology undertakes write requests. For example, master-slave replication based on the Master-Slave architecture, but for various reasons, we may need the MySQL service to have the feature of Multi-Master, and hope that more than one Master in the entire topology can undertake write requests
1.2.3 Cluster Mode
Cluster mode means that there are multiple nodes running, and service requests can be shared through the master node. Such as Zookeeper. The cluster mode needs to solve
the high availability problem of the master node itself, and generally adopts the active/standby mode.
1.3. Distributed system design strategy-fault-tolerant design
Fault tolerance, as the name implies, is the ability of IT systems to tolerate errors.
Fault tolerance processing is to ensure the high availability or robustness of the corresponding system in a distributed environment. A typical case is the solution to the cache penetration problem.
Let's take a look at this example in detail, as shown in the figure
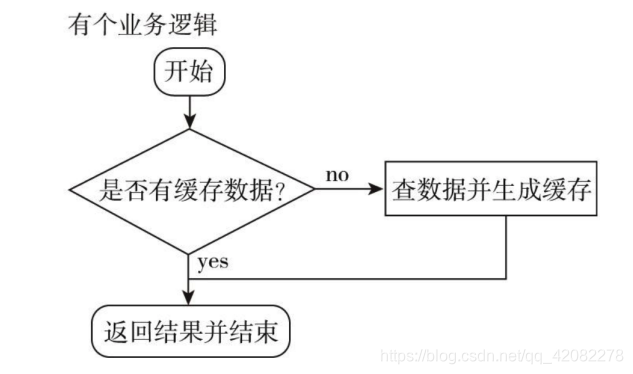
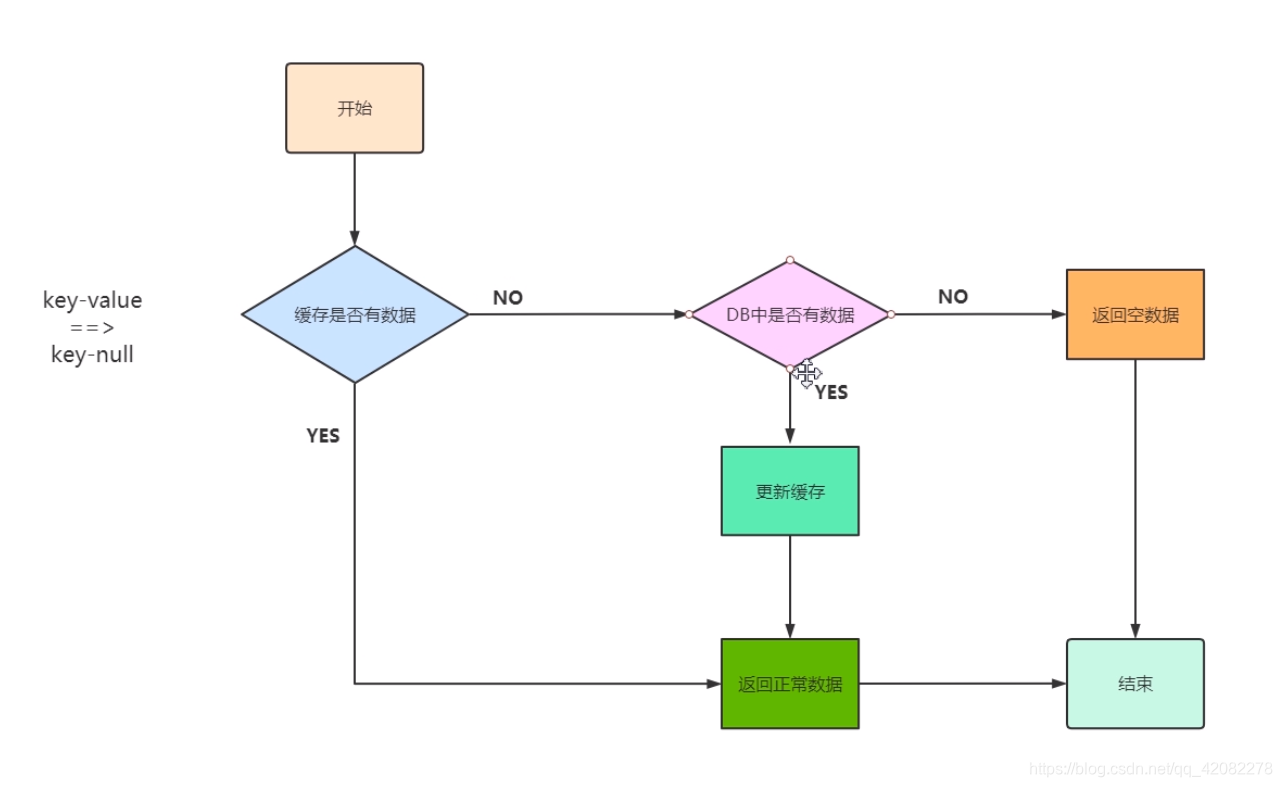
Description of the problem:
We usually use the cache in the project to check whether it exists in the cache first, if it exists, return the cached content directly, if it does not exist, directly query the database and then cache the query result to return. At this time, if a certain data we query does not exist in the cache, it will cause every request to query the DB, so that the cache loses its meaning. When the traffic is large, or someone maliciously attacks
If you frequently initiate a query with an id of "-1", the DB may be down.
So what is a good way to solve this kind of problem?
A more clever way is to preset a value for this non-existent key. For example, key="null". When returning this null value, our application can think that this is a non-existent key, and then our application can decide whether to continue waiting for access or abandon the operation. If you continue to wait for access, and after a time polling point, request this key again. If the value retrieved is no longer null, it can be considered that the key has a value at this time, thus avoiding transparent transmission to the database and putting a lot of similar The request is blocked in the cache.
1.4. Distributed system design strategy-load balancing strategy
Load balancing: The key is to use multiple cluster servers to share computing tasks, and distribute network requests and calculations to different server nodes available in the cluster, so as to achieve high availability and better user operating experience.
As shown in the figure, different users User1, User2, and User3 access the application and are assigned to different nodes through the load balancer.
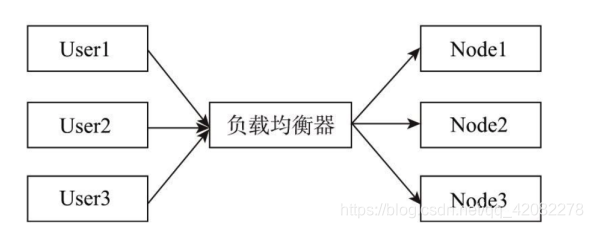
Load balancers have hardware solutions and software solutions. The hardware solutions include the famous F5, and the software includes LVS, HAProxy, Nginx, etc.
Taking Nginx as an example, load balancing has the following strategies:
- Polling: Round Robin, according to the order in the Nginx configuration file, distributes the client's Web requests to different back-end servers in turn.
- Least connection: who is currently the least connected and distributed to whom.
- IP address hash: Make sure that the same IP request can be forwarded to the same back-end node for processing to facilitate session retention.
- Weight-based load balancing: Configure Nginx to distribute more requests to high-profile back-end servers, and relatively few requests to low-profile servers.