1. Load and save the model
# 保存训练好的模型
joblib.dump(自己命名分类器名称, "保存地址")
# 比如 lr = LogisticRegression(),那里就写lr
# 调用保存好的模型(训练好的)去做预测
model = joblib.load("地址")
y_predict = model.predict(x_test)
# 当我们的x,y都被正则化的时候
#y_predict = std_y.inverse_transform(model.predict(x_test))
print("保存的模型预测的结果:", y_predict)
Two, logistic regression
Application scenarios
0-1 classification problem
official
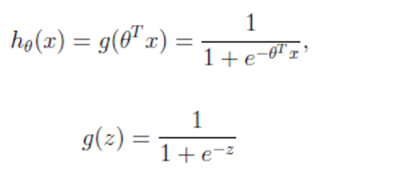
Pros and cons
Advantages: low computational cost, easy to understand and implement
Disadvantages: easy to underfit, classification accuracy is not high
Applicable data: numerical type and nominal type
Logistic regression example
# 默认内置函数为sigmoid,也可选择其它内置函数Relu
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# 读取数据,附上列标签
colum_names = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
data = pd.read_csv(r"C:\Users\dell\Desktop\breast-cancer-wisconsin.data", names=colum_names)
# 替换'?'为nan值,然后扔掉这16个nan值
data = data.replace(to_replace='?', value=np.nan)
data = data.dropna()
# 进行数据的分割
x_train, x_test, y_train, y_test = train_test_split(data[colum_names[1:10]], data[colum_names[10]], test_size=0.25)
# 进行数据标准化
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进入逻辑回归训练
lr = LogisticRegression()
lr.fit(x_train, y_train)
y_predict = lr.predict(x_test)
print(lr.coef_)
print(lr.score(x_test, y_test))
print("召回率:", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"]))
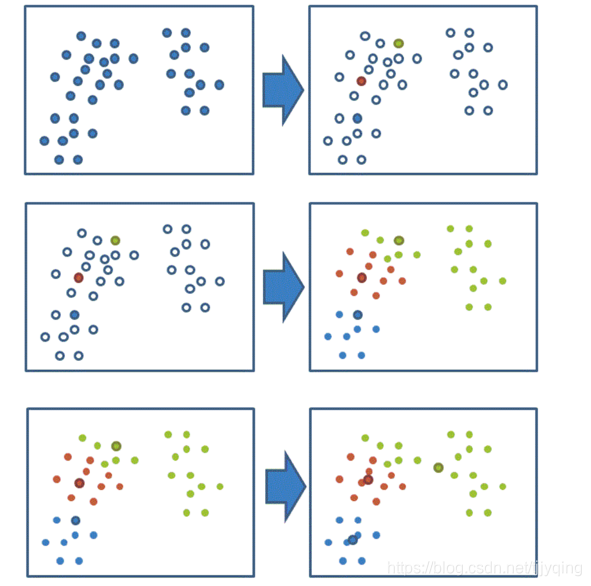
Three, cluster analysis
principle
Unsupervised learning

Code example
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# 读取表格
order_product = pd.read_csv("./data/market_analysis/order_products__prior.csv")
products = pd.read_csv("./data/market_analysis/products.csv")
orders = pd.read_csv("./data/market_analysis/orders.csv")
aisles = pd.read_csv("./data/market_analysis/aisles.csv")
# 合并表格
table1 = pd.merge(order_product, products, on=["product_id", "product_id"])
table2 = pd.merge(table1, orders, on=["order_id", "order_id"])
table = pd.merge(table2, aisles, on=["aisle_id", "aisle_id"])
# 然后我们要把表格变成适用机器学习的方式
# 行为用户,列为不同物品的类别
# 利用pandas中crosstab来交叉表(指定行和列)
table = pd.crosstab(table["user_id"], table["aisle"])
# 利用PCA进行主成分分析
transfer = PCA(n_components=0.9)
data = transfer.fit_transform(table)
# 我们可以进行主成分分析并查看剩余的特征数量
print(data.shape)
# 我们减少样本数量
x = data[:500]
# 接下来可以运用无监督学习的方式对这些用户进行分组
km = KMeans(n_clusters=3)
km.fit(x)
predict_x = km.predict(x)
# 对聚类进行评价
si = silhouette_score(x, predict_x)
print(si)
# 显示聚类的结果
plt.figure(figsize=(10, 10))
# 建立三个颜色的列表
colored = ['pink', 'black', 'yellow']
colr = [colored[i] for i in predict_x]
plt.scatter(x[:, 1], x[:, 5], color=colr)
# 画图
plt.xlabel("1")
plt.ylabel("5")
plt.show()