Author: Little Ming
Python reads the text box of Excel
basic needs
Today I saw a very strange problem, to read the text in the text box of the Excel file, such as this:

I thought that openxlpy could be read, but I didn't find the corresponding API when I checked the official openxlpy documentation. I consulted a few big guys, and they haven't dealt with similar problems.
Under the rascal, I am ready to use my strong data analysis ability and write a method to read these things by myself.
Processing code
The essence of the xlsx file is a compressed package in xml format, and the decompressed file can be parsed and extracted to extract the corresponding data.
Originally I was going to use lxml as xpath to parse xml, but the actual test found that these xml files have a lot of namespaces, and the parsing is extremely complicated. I tried several common xml parsing libraries, which can be parsed smoothly, but I think it is not as convenient as regular , So I finally chose to use regular expressions for xml parsing.
The final processing code is as follows:
import re
import os
import shutil
from zipfile import ZipFile
def read_xlsx_textbox_text(xlsx_file):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
result = []
for xml_name in xml_names:
with open(xml_name, encoding="utf-8") as f:
text = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", text)
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
result.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
return "\n".join(result)
have a test:
result = read_xlsx_textbox_text("test.xlsx")
print(result)
result:
什么是JSON?
就是一种数据格式;比如说,我们现在规定,有一个txt文本文件,用来存放一个班级的成绩;然后呢,我们规定,这个文本文件里的学生成绩的格式,是第一行,就是一行列头(姓名 班级 年级 科目 成绩),接下来,每一行就是一个学生的成绩。那么,这个文本文件内的这种信息存放的格式,其实就是一种数据格式。
学生 班级 年级 科目 成绩
张三 一班 大一 高数 90
李四 二班 大一 高数 80
ok,对应到JSON,它其实也是代表了一种数据格式,所谓数据格式,就是数据组织的形式。比如说,刚才所说的学生成绩,用JSON格式来表示的话,如下:
[{"学生":"张三", "班级":"一班", "年级":"大一", "科目":"高数", "成绩":90}, {"学生":"李四", "班级":"二班", "年级":"大一", "科目":"高数", "成绩":80}]
其实,JSON,很简单,一点都不复杂,就是对同样一批数据的,不同的一种数据表示的形式。
JSON的数据语法,其实很简单:如果是包含多个数据实体的话,比如说多个学生成绩,那么需要使用数组的表现形式,就是[]。对于单个数据实体,比如一个学生的成绩,那么使用一个{}来封装数据,对于数据实体中的每个字段以及对应的值,使用key:value的方式来表示,多个key-value对之间用逗号分隔;多个{}代表的数据实体之间,用逗号分隔。
...
In this way, we have successfully implemented, read all the text of the text box from an Excel file.
Note: If you have any special other requirements, you can modify the code according to the actual situation, or you can contact the author (Xiao Ming) of this article to customize accordingly.
Read the content of the text box of the xls file
The above method only supports the reading of xlsx format files. If you want to read xls format, we need to perform format conversion first.
Complete code:
import win32com.client as win32
def read_xls_textbox_text(xls_file):
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
# excel_app.DisplayAlerts = False
try:
wb = excel_app.Workbooks.Open(xls_file)
xlsx_file = xls_file+"x"
wb.SaveAs(xlsx_file, FileFormat=51)
finally:
excel_app.Quit()
return read_xlsx_textbox_text(xlsx_file)
If you want to not be prompted when there is an xlsx file with the same name, just close the comment
Test read:
print(read_xls_textbox_text(r"E:\tmp\test2.xls"))
result:
我们的数据从哪里来?
互联网行业:网站、app、系统(交易系统。。)
传统行业:电信,人们的上网、打电话、发短信等等数据
数据源:网站、app
都要往我们的后台去发送请求,获取数据,执行业务逻辑;app获取要展现的商品数据;发送请求到后台进行交易和结账
后台服务器,比如Tomcat、Jetty;但是,其实在面向大量用户,高并发(每秒访问量过万)的情况下,通常都不会直接是用Tomcat来接收请求。这种时候,通常,都是用Nginx来接收请求,并且后端接入Tomcat集群/Jetty集群,来进行高并发访问下的负载均衡。
比如说,Nginx,或者是Tomcat,你进行适当配置之后,所有请求的数据都会作为log存储起来;接收请求的后台系统(J2EE、PHP、Ruby On Rails),也可以按照你的规范,每接收一个请求,或者每执行一个业务逻辑,就往日志文件里面打一条log。
网站/app会发送请求到后台服务器,通常会由Nginx接收请求,并进行转发
...
Batch convert xls format to xlsx
Suppose we have a batch of xls files and want to convert them to xlsx in batches:
My approach is to close the application after the entire folder is converted. This is relatively faster, but it may consume more memory. The code is as follows:
import win32com.client as win32 # 导入模块
from pathlib import Path
import os
def format_conversion(xls_path, output_path):
if not os.path.exists(output_path):
os.makedirs(output_path)
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xls_path).glob("[!~]*.xls"):
dest_name = f"{output_path}/{filename.name}x"
wb = excel_app.Workbooks.Open(filename)
wb.SaveAs(dest_name, FileFormat=51)
print(dest_name, "保存完成")
finally:
excel_app.Quit()
have a test:
excel_path = r"F:\excel文档"
output_path = r"E:\tmp\excel"
format_conversion(excel_path, output_path)
result:
E:\tmp\excel/008.离线日志采集流程.xlsx 保存完成
E:\tmp\excel/009.实时数据采集流程.xlsx 保存完成
E:\tmp\excel/011.用户访问session分析-模块介绍.xlsx 保存完成
E:\tmp\excel/012.用户访问session分析-基础数据结构以及大数据平台架构介绍.xlsx 保存完成
E:\tmp\excel/013.用户访问session分析-需求分析.xlsx 保存完成
E:\tmp\excel/014.用户访问session分析-技术方案设计.xlsx 保存完成
E:\tmp\excel/015.用户访问session分析-数据表设计.xlsx 保存完成
E:\tmp\excel/018.用户访问session分析-JDBC原理介绍以及增删改查示范.xlsx 保存完成
E:\tmp\excel/019.数据库连接池原理.xlsx 保存完成
...
Batch extract text box text of xlsx file
Above we have obtained a folder of xlsx files. Below, our requirement is to extract the text box content of each xlsx file in this folder and save it in the corresponding txt format.
Processing code:
from pathlib import Path
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[!~]*.xlsx"):
filename = str(filename)
destname = filename.replace(".xlsx", ".txt")
print(filename, destname)
txt = read_xlsx_textbox_text(filename)
with open(destname, "w") as f:
f.write(txt)
After execution, the corresponding txt file has been successfully obtained:
Demand upgrade
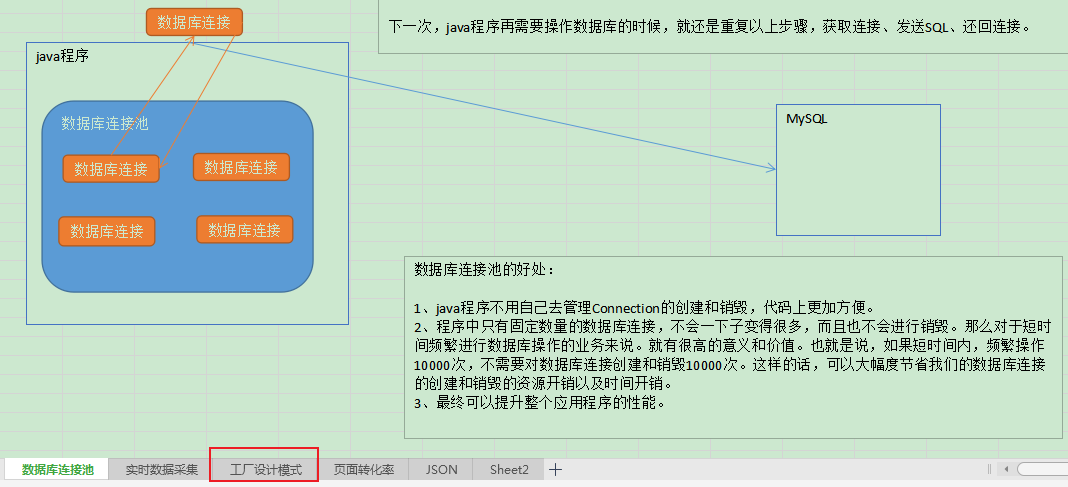
The above reading method is to merge all the text box contents of the entire excel file, but sometimes there are text boxes in multiple sheets of our excel file. We hope to be able to distinguish between different sheets:
Let's improve our reading method to return the text box text corresponding to each sheet name, and test it first.
First unzip the required files:
from zipfile import ZipFile
from pathlib import Path
import shutil
import os
import tempfile
import re
xlsx_file = "test3.xlsx"
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(".")])-1)
print(xml_names, sheets_names, ids)
result:
['C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing1.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing2.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing3.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing4.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing5.xml'] C:\Users\Think\AppData\Local\Temp/xl/workbook.xml [0, 1, 2, 4, 5]
Read sheet name:
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'<sheet .*?name="([^"]+)" .*?/>', text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
sheet_names
result:
['JSON', '数据库连接池', '实时数据采集', '工厂设计模式', '页面转化率']
Analysis:
result = {
}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", xml)
tmp = []
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
tmp.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
result[sheet_name] = "\n".join(tmp)
result
Result (most of the text omitted):
{'JSON': '什么是JSON?....',
'数据库连接池': 'java程序\n数据库连接\n数据库连接\n数据库连接\nMySQL...',
'实时数据采集': '...实时数据,通常都是从分布式消息队列集群中读取的,比如Kafka....',
'工厂设计模式': '如果没有工厂模式,可能会出现的问题:....',
'页面转化率': '用户行为分析大数据平台\n\n页面单跳转化率,....'}
You can see that the content of the text box corresponding to each sheet has been successfully read, and there is a one-to-one correspondence.
Read the corresponding text box text of each sheet separately
We integrate and encapsulate the above process as a method:
import re
import os
from zipfile import ZipFile
import tempfile
def read_xlsx_textbox_text(xlsx_file, combine=False):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(".")])-1)
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'<sheet .*?name="([^"]+)" .*?/>', text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
result = {
}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", xml)
tmp = []
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
tmp.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
result[sheet_name] = "\n".join(tmp)
if combine:
return "\n".join(result.values())
return result
Calling method:
result = read_xlsx_textbox_text("test3.xlsx")
print(result)
You can pass in combine=True to merge the results of the sheet into one text, but it is better to call the previously written method directly.
Batch extract the text of the text box and save it in separate sheets
Below, our requirement is to create a folder with the same name for each xlsx file, and save the text in the text box separately according to the sheet name under each folder.
Processing code:
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[!~]*.xlsx"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_xlsx_textbox_text(filename)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
After testing, a directory was successfully created for each excel file. In each directory, there is a corresponding sheet name file according to which sheets exist in the text box.
Use Python to call VBA to solve the final demand
VBA official document address: https://docs.microsoft.com/zh-cn/office/vba/api/overview/excel
On the whole, the above method of parsing xml by itself is still quite troublesome. After writing the above method, I thought about it. Doesn't VBA have a ready-made method to read the text box? And Python can write VBA code fully compatible, then the problem is simple. Through VBA, not only the code is simple, but also the problem can be solved directly without considering the problem of format conversion. The reading code is as follows:
import win32com.client as win32
def read_excel_textbox_text(excel_file, app=None, combine=False):
if app is None:
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
else:
excel_app = app
wb = excel_app.Workbooks.Open(excel_file)
result = {
}
for sht in wb.Sheets:
if sht.Shapes.Count == 0:
continue
lines = []
for shp in sht.Shapes:
try:
text = shp.TextFrame2.TextRange.Text
lines.append(text)
except Exception as e:
pass
result[sht.Name] = "\n".join(lines)
if app is None:
excel_app.Quit()
if combine:
return "\n".join(result.values())
return result
Test read:
result = read_excel_textbox_text(r'F:\jupyter\test\提取word图片\test3.xlsx')
print(result)

Read the results smoothly.
Batch processing:
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xlsx_path).glob("[!~]*.xls"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_excel_textbox_text(filename, app)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
finally:
app.Quit()
After testing, the shortcomings of VBA processing are also obvious. It takes up to 25 seconds for 63 files, while it takes only 259 milliseconds to directly parse xml, and the performance difference is not an order of magnitude.
to sum up
Reading the data in excel, there is basically nothing that VBA can't do. Python calling VBA is also very simple, just use pywin32 directly. Of course, the 2007 xlsx is essentially a compressed package in xml format. There is no data that cannot be read when parsing xml text, but the code is very laborious to write. Of course, you have to have a better understanding of the storage principle of xlsx.
In this way, the advantages and disadvantages of VBA and direct xml parsing are very obvious:
- VBA is an API directly supported by excel applications. The code is relatively simple to write, but the execution efficiency is low.
- Parsing the xml file directly requires a better understanding of the storage format of excel, which is very laborious to code, but the execution efficiency is extremely high.
What is your opinion as a reader? You are welcome to express your views in the message area below.