string
【Knowledge Framework】

[Contents of the syllabus]
- String pattern matching
One, the definition of string
A string is a finite sequence of zero or more characters, also known as a string.
Generally recorded as:
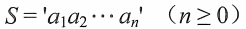
Among them, S is the string name, the character sequence enclosed in single quotes is the value of the string; ai can be letters, numbers or other characters; the number of characters in the string n is called the length of the string.
There are also some other concepts:
- Empty string: The string when n=0 is called an empty string.
- Space string: is a string containing only spaces. Pay attention to the difference between it and the empty string. The space string has content and length, and it can have more than one space.
- Substring and main string: The subsequence composed of any number of consecutive characters in the string is called the substring of the string, and accordingly, the string containing the substring is called the main string.
- The position of the substring in the main string is the serial number of the first character of the substring in the main string.
The logical structure of a string is very similar to that of a linear table . The only difference is that the data object of the string is limited to a character set. In the basic operation, there is a big difference between a string and a linear table. The basic operations of a linear table mainly take a single element as the operation object, such as finding, inserting or deleting an element, etc.; the basic operation of a string usually takes a substring as the operation object, such as finding, inserting or deleting a substring.
Second, the storage structure of the string
1. Fixed-length sequential storage representation
Similar to the sequential storage structure of a linear table, a set of memory cells with consecutive addresses are used to store character sequences of string values. In the fixed-length sequential storage structure of a string, a fixed-length storage area is allocated for each string variable, that is, a fixed-length array.
#define MAXLEN 255; //预定义最大串长为255
typedef struct{
char ch[MAXLEN]; //每个分量存储一个字符
int length; //串的实际长度
}SString;
The actual length of the string can only be less than or equal to MAXLEN, and the string value exceeding the predefined length will be discarded, which is called truncation. There are two ways to express the string length: one is to use an extra variable len to store the length of the string as described in the above definition; the other is to add an end tag character "\" after the string value, which is not included in the string length. 0", the string length at this time is an implicit value.
In some string operations (such as inserting, joining, etc.), if the length of the string value sequence exceeds the upper limit MAXLEN, it is agreed to use the "truncation" method. To overcome this drawback, the maximum length of the string length can only be unrestricted, that is Use dynamic allocation.
2. Heap allocation storage representation
Heap allocation storage means that the string-valued character sequence is still stored in a set of memory cells with consecutive addresses, but their storage space is dynamically allocated during program execution.
typedef struct{
char *ch; //按串长分配存储区,ch指向串的基地址
int length; //串的长度
}HString;
In the C language, there is a free storage area called "heap", and use malloc () and free () functions to complete the action, then return a pointer to the starting address, as the base address of the string, this string It is indicated by the ch pointer; if the allocation fails, NULL is returned. The allocated space can be released with free().
The above two storage representations are usually used by high-level programming languages. The block chain storage representation is only a brief introduction.
3. Block chain storage representation
Similar to the chain storage structure of the linear table, the chain value can also be stored in the chain table method. Due to the particularity of the string (each element has only one character), in specific implementation, each node can store either one character or multiple characters. Each node is called a block, and the entire linked list is called a block chain structure. Figure (a) is a linked list with a node size of 4 (that is, each node stores 4 characters). When the last node is not full, it is usually filled with "#"; Figure (b) is a node size of 1. Linked list.

Three, the basic operation of string
- StrAssign(&T, chars): Assignment operation. Assign string T to chars
- Strcopy(&TS): Copy operation. The string T is copied from the string S.
- StrEmpty(S): Determine empty operation. If S is an empty string, it returns TRUE, otherwise it returns FALSE
- StrCompare(S,T): Comparison operation. If S>T, the return value>0; if S=T, the return value=0; if S<T, the return value<0.
- StrEngth(S): Find the string length. Returns the number of elements in the string S
- Substring(&Sub,S,pos,1en): Find the substring. Use Sub to return a substring of length len starting from the pos-th character of the string S.
- Concat(&T,S1,S2): Connect in series. Use T to return a new string formed by connecting S1 and S2.
- Index(S,T): Positioning operation. If there is a substring with the same value as the string T in the main string S, return its first occurrence position in the main string S; otherwise the function value is 0
- Clearstring(&S): Clear operation. Clear S to an empty string
- Destroystring(&S): Destroy the string. Destroying string S
Different high-level languages can have different definition methods for the basic operation set of string. In the above-defined operations, the five operations of string assignment StrAssign, string comparison StrCompare, string length strength, concatenation Concat, and substring Substring constitute the minimum operation subset of the string type, that is, these operations cannot use other string operations. On the contrary, other string operations (except string clear Clearstring and string destroy Destroystring) can all be implemented on this minimum operation subset.
For example, the positioning function Index (S, T) can be realized by operations such as judgment, string length and substring.
int Index(Sring S, String T){
int i = 1, n = StrLength(S), m = StrLength(T);
String sub;
while(i <= n-m+1){
SubString(sub, S, i, m); //取主串第i个位置,长度为m的串给sub
if(StrCompare(sub, T) != 0){
++i;
}else{
return i; //返回子串在主串中的位置
}
}
return 0; //S中不存在与T相等的子串
}
Four, string pattern matching (emphasis)
1. Simple pattern matching algorithm
The positioning operation of the substring is usually called the pattern matching of the string, which seeks the position of the substring (often called the pattern string) in the main string. A fixed-length sequential storage structure is used here, and a brute force matching algorithm that does not depend on other string operations is given.
int Index(SString S, SString T){
int i = 1, j = 1;
while(i <= S.length && j <= T.length){
if(S.ch[i] == T.ch[j]){
++i; ++j; //继续比较后继字符
}else{
//指针后退重新开始匹配
i = i-j+2;
j = 1;
}
}
if(j > T.length){
return i - T.length;
}else{
return 0;
}
}
The following figure shows the matching process of the pattern string T ='abcac' and the main string S

The worst time complexity of a simple pattern matching algorithm is O(nm), where n and m are the lengths of the main string and the pattern string, respectively.
2. KMP algorithm
In the simple matching above, each failed match is the pattern is shifted one bit backward and then compared from the beginning. However, a sequence of characters that have been matched to be equal is a certain prefix of the pattern. This frequent repeated comparison is equivalent to the pattern string being continuously compared with itself, which is the source of its inefficiency.
Therefore, you can start from analyzing the structure of the pattern itself. If a suffix in the matched prefix sequence is exactly the prefix of the pattern, then the pattern can be slid back to the position aligned with these equal characters, the main string i pointer There is no need to backtrack, and continue to compare from this position. The calculation of the number of digits for the backward sliding of the pattern is only related to the structure of the pattern itself, and has nothing to do with the main string.
The characteristic of the KMP algorithm is: only the pattern string is moved backward, and the comparison pointer does not backtrack . It's a cow breaking.
(1) The prefix, suffix and partial matching value of the string
To understand the structure of substrings, we must first figure out several concepts: prefix , suffix and partial matching value . The prefix refers to all the head substrings of the string except the last character; the suffix refers to all the tail substrings of the string except the first character; the partial match value is the prefix and the suffix of the string before the longest equal Suffix length. Let's take'ababa' as an example for illustration
- The prefix and suffix of'a' are both empty sets, and the longest equal length of the prefix and suffix is 0.
- The prefix of'a' is {a}, the suffix is {b}, {a}∩{b}=NULL, and the longest equal length of the prefix and suffix is 0.
- The prefix of'aba' is {a,ab}, the suffix is {a,ba}, {a,ab}∩{a,ba} = (a), the longest equal suffix length is 1
- The prefix of'abab' {a, ab, aba} ∩ suffix {b, ab ,bab }={ab}, the longest equal suffix length is 2.
- The prefix of'ababa' {a, ab, aba, abab} ∩ suffix {a, ba, aba, baba}={ a, aba}, there are two common elements, and the longest equal suffix length is 3.
Therefore, the partial match value of the string'ababa' is 00123.
What is the effect of this partial matching value?
Going back to the original question, the main string is'abacabcacbab' and the substring is'abcac'.
Using the above method, it is easy to write the partial match value of the substring'abcac' as 00010, and write the partial match value in the form of an array to get a partial match value (Partial match, PM) table.
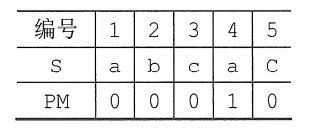
The following uses the PM table to perform string matching: the
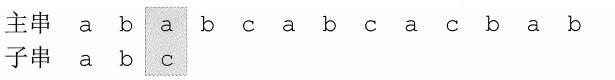
first matching process: it is
found that c does not match a, and the first two characters'ab' are matched. Checking the table shows that the partial matching value corresponding to the last matching character b is 0, so calculate the number of digits that the substring needs to move backward according to the following formula: digits of
movement = number of matched characters-corresponding partial matching value digits of movement = number of matched characters-corresponding partial matching valueShift movement digit number=It has been matched with the character character number−To be a portion of partial match with values
as 2-0 = 2, the rearward movement of the two sub-string, a second pass matching is as follows:

the second pass matching process:
The c and b do not match, the first four characters' abca' is matched, the partial matching value corresponding to the last matching character a is 1, 4-1=3, and the substring is moved backward by 3 positions, and the third matching is performed as follows: the
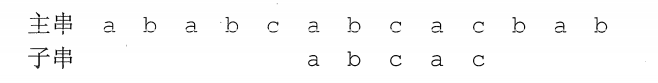
third matching process:
all substrings The comparison is complete and the match is successful. During the whole matching process, the main string never retreats, so the KMP algorithm can complete the pattern matching operation of the string in the order of O(n + m) time, which greatly improves the matching efficiency.
(2) Improved algorithm
When using a partial matching value, whenever the matching fails, find the partial matching value of the previous element. This is a bit inconvenient to use, so move the PM table to the right by one position, so which element fails to match, directly look at its own Partial matching value is sufficient. Shift the PM table of the string'abac' in the above example to the right by one position, and you will get the next array:
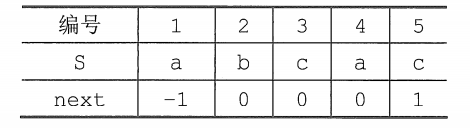
sometimes in order to make the formula more concise and simple to calculate, the entire next array is +1. Therefore, the next array becomes:
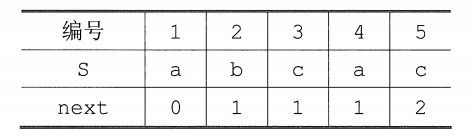
Finally, the substring pointer change formula j=next[ j] is obtained.
The meaning of next[ j] is: when the j-th character of the substring is mismatched with the main string, jump to the next[ j] position of the substring to compare with the current position of the main string.
Through analysis, it can be known that, except for the first character, the value of the next array corresponding to the remaining characters in the pattern string is equal to its maximum common prefix and suffix length plus 1
next [j] = maximum common prefix and suffix length + 1 next[ j] = maximum common prefix and suffix length + 1 next[j]=Most large public were before the prefix length of+1
Scientific derivation leads to the following formula:
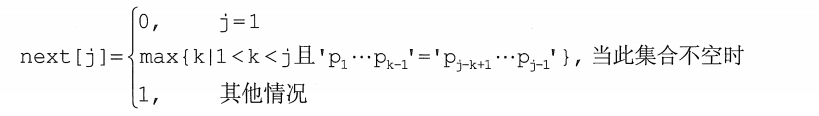
Through scientific deduction, we can write the program for finding the next array as follows:
void get_next(String T, int *next){
int i = 1, j = 0;
next[1] = 0;
while (i < T.length){
if(j==0 || T.ch[i]==T.ch[j]){
//ch[i]表示后缀的单个字符,ch[j]表示前缀的单个字符
++i; ++j;
next[i] = j; //若pi = pj, 则next[j+1] = next[j] + 1
}else{
j = next[j]; //否则令j = next[j],j值回溯,循环继续
}
}
}
Compared with the solution of the next array, the KMP algorithm is much simpler, and is very similar to the simple pattern matching algorithm:
int Index_KMP(String S, String T){
int i=1, j=1;
int next[255]; //定义next数组
get_next(T, next); //得到next数组
while(i<=S.length && j<=T.length){
if(j==0 || S.ch[i] == T.ch[j]){
//字符相等则继续
++i; ++j;
}else{
j = next[j]; //模式串向右移动,i不变
}
}
if(j>T.length){
return i-T.length; //匹配成功
}else{
return 0;
}
}
(3) Further optimization of KMP algorithm
The next array defined above is still flawed in some cases and can be further optimized. As shown in Figure 4.7, when the pattern 'aaaab' is matched with the main string 'aaabaaaaab':
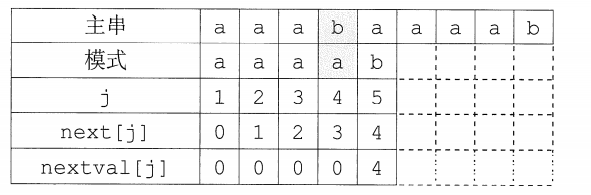
Obviously, it is meaningless to use the same character as p4 for the next 3 times, and it will definitely be mismatched.
It makes no sense. So what should be done if this type
appears ? If it does , you need to recurse again, modify next[j] to next [next[j]], until the two are not equal, the updated array is named nextval. The algorithm for calculating the correction value of the next array is as follows, and the matching algorithm is unchanged at this time.
void get_nextval(String T, int *nextval){
int i = 1, j = 0;
nextval[1] = 0;
while (i < T.length){
if(j==0 || T.ch[i]==T.ch[j]){
//ch[i]表示后缀的单个字符,ch[j]表示前缀的单个字符
++i; ++j;
if(T.ch[i] != T.ch[j]){
//若当前字符与前缀字符不同
nextval[i] = j; //则当前的j为nextval在i位置的值
}else{
//如果与前缀字符相同
//则将前缀字符的nextval值给nextval在i位置上的值
nextval[i] = nextval[j];
}
}else{
j = nextval[j]; //否则令j = next[j],j值回溯,循环继续
}
}
}
Summarizing the improved KMP algorithm, it calculates the next value at the same time, if the a-bit character is equal to the b-bit character pointed to by its next value, then the nextval of the a-bit points to the nextval value of the b-bit, if not, Then the nextval value of the a bit is the next value of its own a bit.
This piece of logic is very simple. With the next array, we can easily derive its nextval array.
appendix
Link above
Data structure: stack and queue
Link below
Data structure: tree (to be updated)
Reference
1. Cheng Jie: "Dahua Data Structure"
2. Yan Weimin, Wu Weimin: "Data Structure (C Language Edition)"
3. Wangdao Forum: "2021 Data Structure Postgraduate Review Guide"