Editor's note
The focus of the second half of media convergence will be toward the trend toward intelligence. How to create practical and effective media data products and services, and then complete the transformation of digital intelligence, has become the most concerned issue of the media industry.
In this article, focusing on the transformation needs of current media organizations, the Baixin Technology Big Data technical team systematically introduced Baixin Technology's media data center construction methodology and practical results.
1. Background of media data center construction
Traditional media represented by newspapers, publications, radio and television, and new media products represented by websites, news clients, Weibo, WeChat official accounts, IPTV, OTT, etc., whether it is presentation mode, communication channel, or construction The goals and technical systems are very different, which leads to the repeated waste of system construction, each application system and release channel are in their own way, there are related fragmentation and isolation between business systems, data standards are not standardized, and the data of each system is difficult to integrate and data quality. There is no guarantee, the data cannot be used effectively, and the rapid business iterative innovation cannot be responded to.
The traditional media technology architecture system has been difficult to meet the current business needs of the media industry, and Zhongtai can solve these problems well. Media data center is based on content construction. Based on Internet thinking, it gathers internal and external data resources, and centers on content, channels, platforms, operations, management and other construction needs to form media data of "data integration, capacity sharing, and application innovation" The middle station service system can provide support for media production assistance, media operation assistance, media release terminal applications, and media think tanks for foreground applications.
Through the construction of the media data center, business can be empowered forward, business and application innovation can be realized; data can be accumulated backward, data integration can be realized, and data support can be strengthened and strengthened. Therefore, the media data center has brought about improvements and changes in multiple aspects such as news topic selection, content production, quality control, release channels, communication effects, and content operations. Through the media data center architecture, the "data capability sinks and business applications rise" to create a technical layout of "large and middle stations and small front desks" to form a sustainable media data and service support platform.
2. Methodology of media data center construction
Media Data Center is a comprehensive platform covering multiple levels of data collection, data processing, data asset management, data governance, data services, data analysis and data applications. It not only gathers internal and external resources of media organizations, but also provides unified data storage, builds unified data standards and data resource management, and provides unified basic data services to business parties. At the same time, in order to strengthen the big data analysis capabilities of media organizations, it is also necessary to introduce intelligent analysis services to realize various public intelligent analysis application services that meet business needs.
The overall construction goal of the media data center is mainly to increase the service reuse rate, endow the business with rapid innovation capabilities, and finally build a platform-based, asset-based, intelligent, scene-based, and service-based "central kitchen"-style fusion media data platform.
- The four major components of media data
From the perspective of strategic construction, the media data center includes data asset management platform, data intelligent analysis platform, resource release and display platform, resource service sharing platform and other parts: the essence of data asset management platform is to capitalize data; data intelligent analysis The essence of the platform is to make data intelligent; the essence of the resource publishing and display platform is to scene data; the essence of the resource service sharing platform is to service data.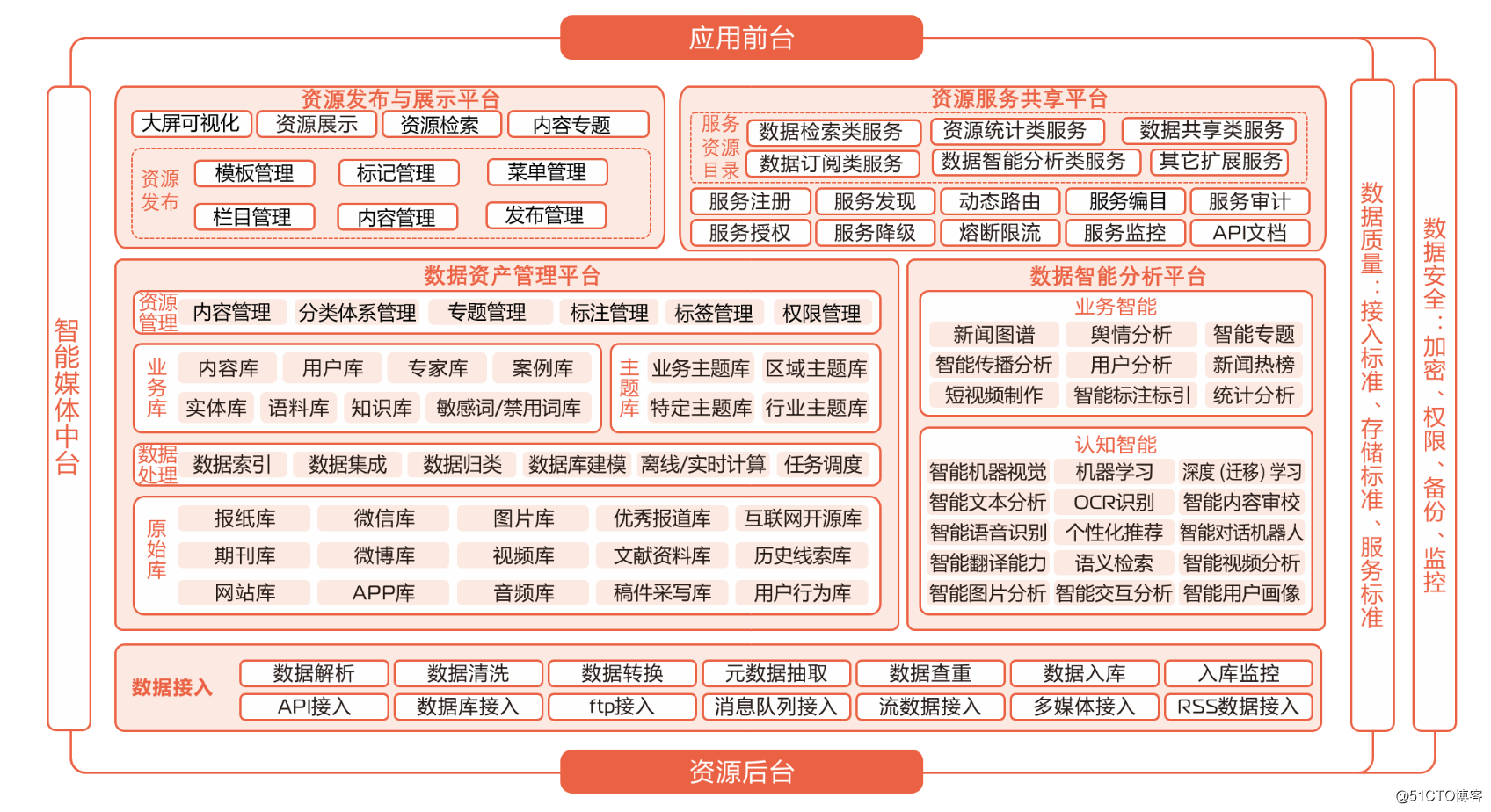
(1) Data asset management platform
The data asset management platform is mainly to build the management and control capabilities of media data assets. It is a data platform integrating data collection, integration, governance, organization management, and intelligent analysis. The final data will be provided to front-end applications as a service to improve business Operational efficiency and continuous promotion of business innovation are the goals. The final output is a theme library suitable for each business, supporting business scenarios such as news production, intelligent publishing, media operations, and public opinion analysis.
The data asset management platform can realize the effective aggregation and management of various data resources such as manuscript data, product data, operation data, behavioral data, and external Internet resources in the media organization, through the establishment of unified data standards and data resource management. Unified basic data services to the business side.
At the same time, guided by the global idea of data diversity, media data centers will generally collect and introduce full services (collection, editing, feed, etc.), multiple terminals (PC, H5, APP, etc.), and multiple forms (own business system, three-party purchases) , Internet targeted capture) data, to achieve effective use and integration of media data resources. Through the combination of AI intelligent technology and manual work, the data indexing of text, pictures, audio and video is carried out to realize the digitization of content resources, fully explore the relationship between data, and enhance the potential value of data. Use functions such as automatic topic and customized topic to realize the rapid generation of business library and topic library, and provide the ability of agile library construction.
(2) Data intelligent analysis platform
The data intelligence analysis platform provides two types of AI capabilities: cognitive intelligence and business intelligence. Among them, cognitive intelligence is mainly based on artificial intelligence technologies such as machine learning, deep learning, and migration learning, providing basic capabilities such as natural language processing, image recognition, OCR recognition, and video analysis. Business intelligence is based on basic intelligence and organizes and encapsulates basic intelligence. It includes a series of basic service capabilities that are commonly used in business. It provides in-depth data processing at the data level and in-depth analysis of the business at the business level. Business intelligence includes intelligence. Recommendations, user portraits, content indexing, topic analysis, content review and intelligent topics, etc. Through the construction of the big data center capability platform, the intelligent processing capabilities of media organizations are improved, which is helpful to realize capability reuse, reduce development costs, and realize product innovation.
The goal of the data intelligent analysis platform is to build media AI capabilities, provide AI capability support inside and outside the society, realize the transformation and upgrading of media from digital to intelligent, and provide intelligent assistance for media production, intelligent publishing, media operation, communication effect evaluation and public opinion analysis .
(3) Resource release and display platform
It can be said that the resource release and display platform is the face of the entire media data center. For media organizations, data and capabilities can be unified encapsulated and then displayed in a centralized manner. It is a unified portal for shared resources to serve related users and realizes the unified presentation of shared resources. , As well as the retrieval of resources, the flexible organization and page publishing of resources, while providing flexible rights management, creating a "one-door" service platform.
The resource release and display platform mainly includes two parts, the front-end resource display part and the back-end resource release part. The front-end display provides browsing and use of the content data in the media data, including the website portal homepage, browsing channels, browsing articles, and intelligent retrieval capabilities integration. Backstage management is mainly the management of users and content, including content management, menu management, template management, mark management and user management.
(4) Resource service sharing sub-platform
When media organizations effectively integrate dispersed and heterogeneous information resources, eliminate the shackles of "information islands", and form their own data assets and AI capabilities, they need to provide services to external parties to realize their value and share resources and services. The demand came into being.
At present, enterprise resource sharing mainly faces three problems. First, the data demander cannot directly obtain data due to the inconsistent data format and low data extraction efficiency. Second, data owners cannot manage efficiently due to problems such as low development efficiency, imperfect data authorization management system, insufficient data service methods, and complex calling relationships. Third, the data demander and the data owner cannot achieve seamless data interconnection, and the data service method is single, which cannot meet the multi-scenario sharing needs of the big data era.
The resource service sharing platform will encapsulate data capabilities and analysis capabilities into a unified API service interface in the form of microservices, so as to provide external support for data services and capabilities, form a data service resource catalog, and realize the rapid development and external development of data interfaces. Release to respond to the data service capability requirements of the business side in real time. Through simple and visual configuration, issues such as data interface API creation, API release, API version management, and API document management can be realized, reducing daily operation and maintenance costs.
Therefore, the entire media data center is supported and coordinated by the above four platforms, which together constitute the overall system architecture of the media data center, which runs through the entire process of data collection, storage, analysis, and release.
- Data architecture design
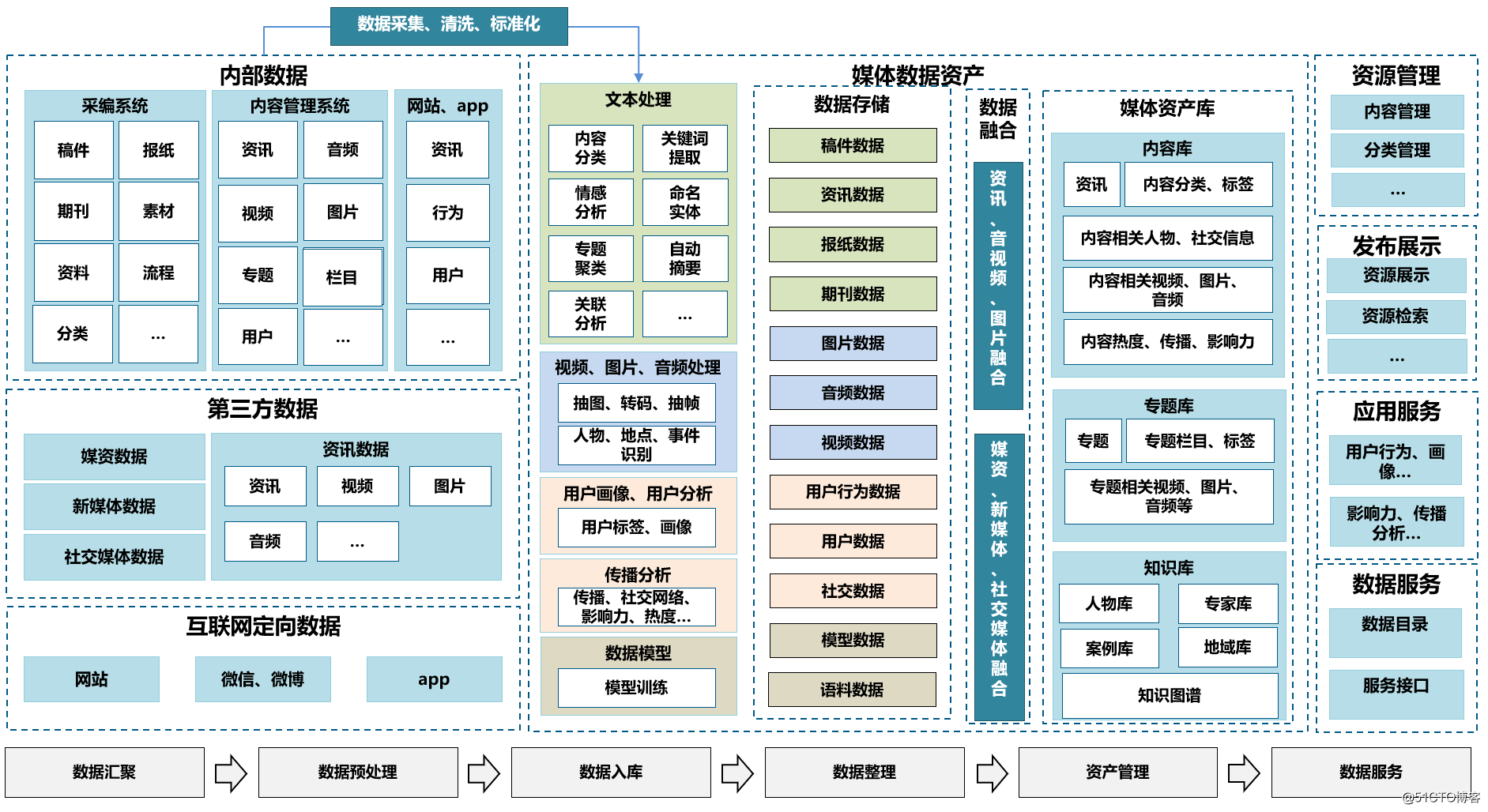
The overall structure of the data center is shown in the figure above, which can be divided into processes such as resource aggregation, data preprocessing, data storage, data sorting, data assets, and data services.
Data resource aggregation includes data collection and data integration. These resource data mainly come from content production data, third-party data, Internet targeted data, etc., including data types such as manuscripts, newspapers, periodicals, social media, mobile clients, and websites. Support multiple access methods such as database, file, streaming, etc. to access multi-source heterogeneous data, converge and integrate data resources. It is worth noting that the convergence process needs to implement convergence processing for the current business system planning, and a unified storage plan for data.
Data preprocessing mainly refers to the preliminary cleaning and standardization of data. The preprocessing before data storage will perform field analysis, mapping, conversion, and processing field incompleteness, errors, and data deduplication. The cleaned data needs to be standardized, and data in different formats is converted according to the unified data format specification. At the same time, automatic indexing and data classification are generally required before data is stored in the database: for text data, automatic classification, automatic summarization, keyword, sentiment analysis and other aspects of recognition and label extraction will be carried out; for image type data, it will be carried out Recognition and label extraction of picture characters, picture scenes, picture attributes, news events, landmark buildings, etc.; for audio data, recognition and content extraction of speech recognition, audio attributes, news events, etc.; for video data, Recognition and label extraction of video characters, video scenes, video attributes, news events, landmark buildings, etc.
Data storage is the layered and partitioned storage of parsed text, pictures, audio and video, files and other data. The data to be stored in the database needs to ensure the integrity, standardization and timeliness of the data, and must be uniformly converted and stored in the database in accordance with the data format specifications required by the platform.
The main tasks of data sorting are manual indexing and data integration of the data in the database. Through the functions of data selection, indexing, and proofreading, the data is indexed and organized, retrieved and displayed in an orderly manner. At the same time, you can gather resources based on tags to form a service interface for third-party systems to call. Manual indexing can improve the accuracy of data tags and lay the foundation for the accuracy of some important topics.
The data asset link is to divide the accessed data based on the current business situation and future planning, and carry out in-depth processing of the accessed data to realize the classified management of data resources, metadata management, and asset management. Media data assets are mainly composed of two parts: content database and theme database. The business database is constructed based on the business system, and provides business-oriented data assets such as thematic database, corpus, entity database, and knowledge base for front office business. The theme library is to respond to the need for rapid database construction. Through simple search and screening, a theme library that meets business needs is formed, which reduces the cost of data development.
Data capabilities and intelligent analysis capabilities are all provided externally in the form of microservices. The data center ensures the performance and stability of data services, data quality and accuracy, and realizes unified management and control and comprehensive management of services.
-
Three stages of media data center construction
It is difficult to build all the contents of the media data center at one time. Many companies do it in stages, especially for traditional media units. Many businesses have not yet been digitized, let alone building a data center. The overall planning and construction of the media data center adopts the concept of "phased, vertical business in batches". The entire media data center can be constructed in three stages.
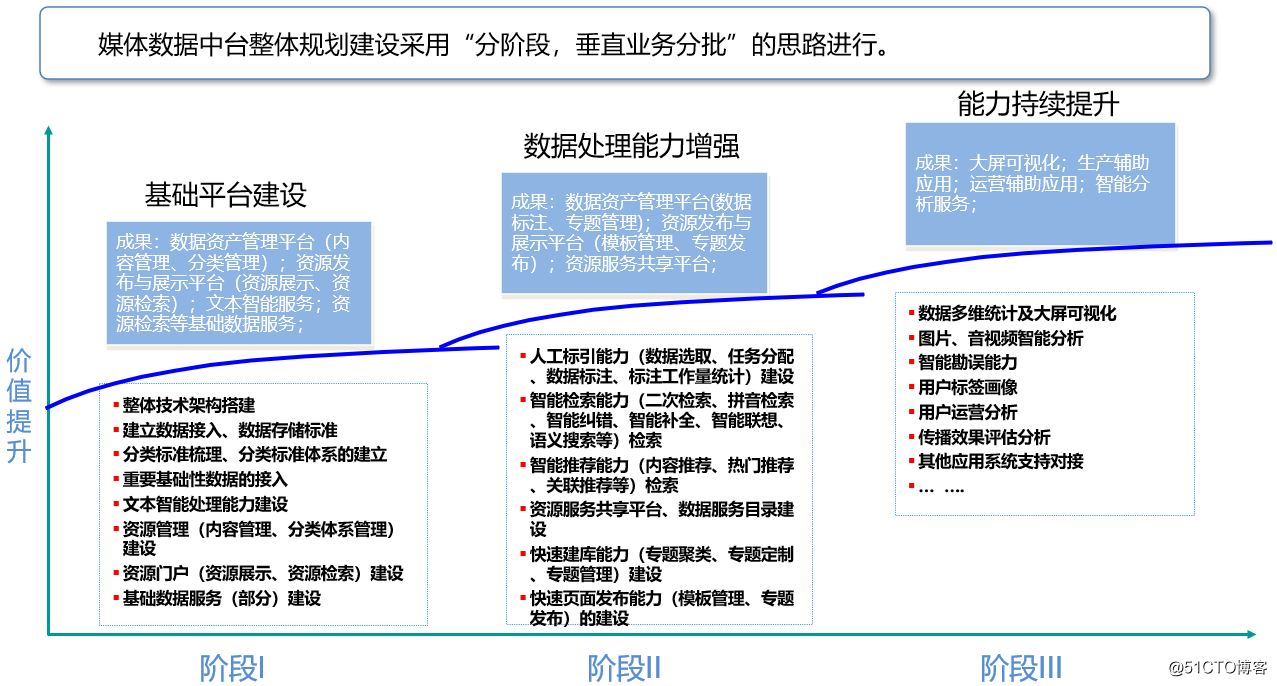
Phase 1: Basic platform construction
The goal of building:
The first stage of the media data center mainly focuses on building a framework, establishing standards, and gathering data. The most important task of the first stage of construction is to connect with the production data of various departments, establish unified data access, data classification, data interface, and data storage standards, and give priority to access to basic data that affects business development. At the same time, it sorts out data classification standards, realizes automatic classification, abstract, keyword, sentiment analysis and other aspects of identification and label extraction through intelligent text processing capabilities, and supports the processing and maintenance of data content and classification system. At the same time, the platform provides support for basic data services and page capabilities that meet different businesses. Provide resource management functions for data managers to realize content processing and classification. Provide basic data service interfaces for developers, and provide interface services such as resource retrieval, viewing, and downloading. Provide users with resource portal access services and support users to view and retrieve data resources.
Construction Content:
Overall technical architecture construction
Establish data access and data storage standards
Sorting out classification standards and establishing classification standards system
Access to important basic data
Text intelligent processing capacity building
Resource management (content management, classification system management) construction
Resource portal (resource display, resource retrieval) construction
Basic data service (partial) construction
Construction results:
Complete data access, data storage, data classification, and data service standards;
Complete the construction of intelligent text processing capabilities for automatic classification, abstraction, keyword extraction, and named entities;
Complete the content management and classification system management functions of the data asset management platform for inbound resources;
Complete the resource display and resource retrieval functions of the resource portal part of the resource release and display platform;
Complete basic data services such as resource retrieval and resource download.
Phase 2: Enhanced data integration capabilities
The goal of building:
The second stage of the media data center mainly focuses on data deep processing and sorting, data intelligent services, rapid database construction and content publishing as the stage goals. In the second stage, manual indexing capabilities will be introduced, and data selection, indexing, proofreading and other processes can be realized through indexing tools, and the value of data can be deeply explored. The indexed manuscripts can be organized, retrieved, and displayed through tags. At the same time, tags can be used to aggregate data, laying the foundation for the rapid generation of thematic databases.
The rapid database construction combines the automatic collection of thematic data with manual processing, and uses the clustering algorithm of machine learning to automatically discover and generate thematic clusters. By manually labeling the clusters, the function of automatic discovery and creation of thematics is achieved. At the same time, customized topics provide business personnel with resource aggregation services centered on "topics", through the combination of related dimensions (keywords, entity words, classification tags, attributes, etc.) to achieve rapid aggregation of historical data and real-time data. Content publishing supports the rapid generation of thematic pages, and the presentation and access of thematic pages is realized through template technology. At the same time, the retrieval capabilities and recommendation capabilities will be improved at this stage, providing intelligent error correction, smart completion, smart association, semantic search, content recommendation and other functions to optimize the effects of content retrieval and recommendation and enhance the user experience. In terms of data services, it will strengthen the management and monitoring of data services, conduct unified registration and authorization of data services, form a data service catalog, and provide external support for service capabilities.
Construction Content:
Manual indexing ability (data selection, task allocation, data indexing, indexing workload statistics) construction
Intelligent retrieval capabilities (secondary retrieval, pinyin retrieval, smart error correction, smart completion, smart association, semantic search, etc.) retrieval
Intelligent recommendation capabilities (content recommendation, popular recommendation, related recommendation, etc.) retrieval
Data service catalog construction
Rapid database construction capabilities (topic clustering, topic customization, topic management) construction
Construction of fast page publishing capabilities (template management, topic publishing)
Construction results:
Complete the data selection, task allocation, data indexing, and indexing workload statistics functions of the data indexing module in the data asset management platform;
Complete the thematic clustering, thematic customization, and thematic management functions of the thematic management module in the data asset management platform;
Complete the template management and thematic release functions of the release management module of the resource release and display platform;
Complete basic data services such as resource retrieval and resource downloading, and form service catalogs and services such as data subscription, data retrieval, intelligent analysis, and data statistics.
Stage 3: Continuous improvement of capabilities
The goal of building:
The third stage of the media data center mainly takes auxiliary content production and media operation, multi-dimensional statistics of data, large-screen visualization, and intelligent data analysis as the stage goals. Through artificial intelligence and big data technology, the transformation and upgrading of financial media will be empowered to provide more technical support for future business innovation. Build intelligent, precise, and real-time functions such as driving information collection, topic selection planning, auxiliary production, user portraits, channel distribution, communication effect monitoring, and public opinion supervision to help media units achieve productivity, guidance, influence, and credibility The promotion. Media production assistance applications are mainly used to support business processes such as topic selection planning, news interviews, news editing, news review, news release, etc., and provide production assistance capabilities such as intelligent topic selection, news gathering, media resource library, intelligent topics, and personalized recommendations . Media operation auxiliary applications provide operational auxiliary capabilities such as media communication analysis, media influence analysis, user holographic portraits, and decision analysis.
Construction Content:
Data multi-dimensional statistics and large-screen visualization
Intelligent analysis of pictures, audio and video
Intelligent errata capability
User tag portrait
User operation analysis
Communication effect evaluation analysis
Other application systems support docking
… ….
Construction results:
Complete the large-screen visualization and index statistics functions of the resource release and display platform;
Complete the cognitive intelligence related functions and applications in the data intelligence analysis platform;
Completion of the auxiliary content production and media operation applications related to business intelligence in the data intelligence analysis platform.
- Media data mid-stage implementation process
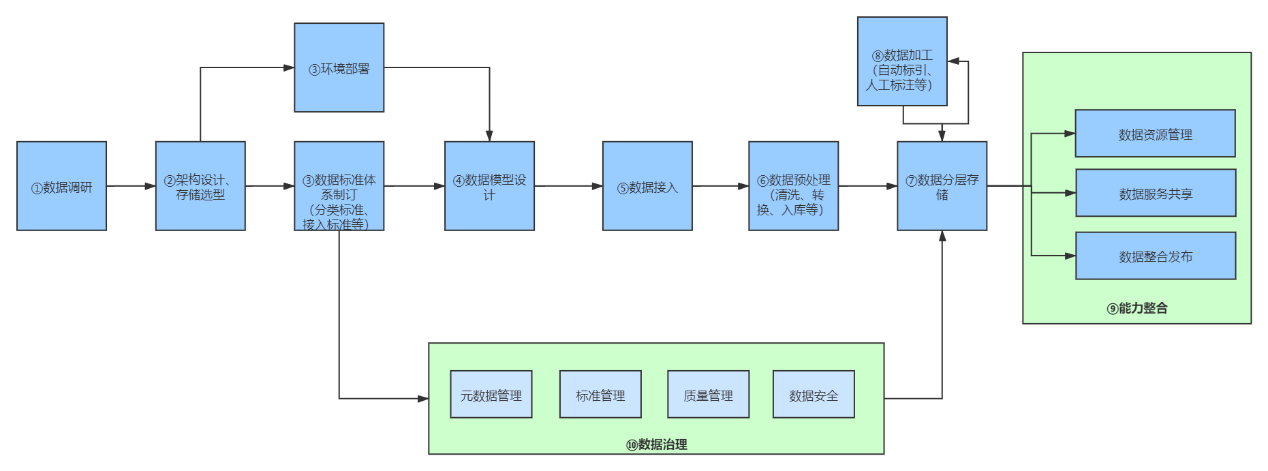
(1) Data research
Make data an asset through data inventory, and understand what data the enterprise has, where, and how much order it has. It mainly includes business process combing, data process combing, data identification and classification.
Inventory the structured, semi-structured, and unstructured data that needs to be accessed, and collect data information through survey forms and interviews. Data sources usually include newspapers, periodicals, websites, apps, social media, etc. Confirm whether historical data migration is required.
The information that structured data needs to collect usually includes:
Data access information: The key includes system information, database information, manager information, data volume information, encryption mechanism information, incremental information, and database table information that can be accessed;
Data dictionary: table structure collection, mainly including table primary and foreign keys, definition rules of each field, verification rules, etc.;
Code table: collection of code table information used in the system;
Data integration rules: the collection of integration rules when data content conflicts.
Information that needs to be collected for unstructured data usually includes:
Unstructured data usage;
Storage location and how to obtain metadata;
File type;
File content analysis, format conversion, whether to extract content;
How to return to use.
(2) Architecture design and technology selection
Determine the overall design ideas according to the project requirements, and carry out the overall system architecture, technical architecture and application architecture design. On this basis, the overall data plan is determined, and the corresponding storage method is designed according to the data type, business use scenario, and presentation form of the data to meet the data service requirements. If necessary, centralized testing can be carried out, and the data storage selection can be finally determined through comprehensive judgment of the test results of indicators such as read and write speed and reliability.
(3) Development of data standard system
Combine national standards, industry standards and actual business, sort out and figure out the data situation of each data source, and formulate data access standards, data classification standards, data storage standards, and data service standards for key business process data and business result data.
Access standards. Data access is responsible for the unified access of various resources to the data center. It is necessary to formulate corresponding data access specifications, adapt to different data access requirements, and be able to provide common access methods such as databases, message queues, APIs, and files. The newly added data type can be accessed as long as it meets the data access specification. Through this standard data access pipeline and expansion method, it is possible to flexibly respond to the constantly changing access requirements of the business side and ensure the versatility and unity of data access.
Classification criteria. Refer to domestic and foreign classification standards such as "News Materials Classification Law" and "China News Information Classification Law", based on the existing classification system, combined with the actual characteristics of the data to cooperate with customers to complete the design, adjustment and improvement of the classification system.
Storage standards. For different data types from multiple data sources, it is necessary to determine the corresponding field conversion, storage methods, and storage standards. Standardize data storage components, storage paths, storage formats, copy strategies, backup mechanisms, etc., and design hierarchical and partitioned data to ensure the rationality and scalability of data storage.
Service standards. Sort out the list of services that need to be built and classify the interfaces in the list of services. Split the service according to the type of service carried by the service interface. Define the data interface access method, access path, request format, return result format, and return status code type to ensure the overall standardization and consistency of data services.
(4) Data model design
Data model design. Media data is very unstructured. The biggest difference from traditional data warehouses is that more than 90% of the data in the media industry is unstructured, such as text, pictures, and videos. Therefore, it is necessary to create original libraries, business libraries, theme libraries, knowledge bases, etc., according to business scenarios and multiple heterogeneous data sources.
(5) Data access
Through data access, a data standardization process is established to realize data collection, cleaning and standardization.
Data standardization connects various resources to the data center.
Supports different data types such as text, pictures, audio and video, files, structured and unstructured.
The access mode can be flexibly configured and managed, and can adapt to the access of different data resources to ensure data integrity.
The data interface has good fault tolerance and safety to avoid affecting the stability and reliability of the overall system due to data interface problems.
It has a visual WEB configuration management and operation and maintenance management interface, supports data management personnel to configure and define the elements of the access task, supports the monitoring of data access tasks and daily operation and maintenance operations, supports the data access process can be recorded, and the collection Provide reports on system work results; support abnormal alarm capabilities for data access systems, and actively feed back information such as data access failures.
(6) Data preprocessing
Data cleaning: Perform data pre-processing work such as data validity inspection and filtering and deduplication when accessing data to ensure data quality. Analyze the data and map the fields to complete the standardized operation of the data.
Based on the characteristics of media industry data, data preprocessing adopts batch-stream combination to solve the data requirements of business scenarios. Data comes from different data sources, such as API, MQ, log, file, etc. The data needs to do text deduplication, data structuring, content labeling, and light real-time statistics in real-time calculations. After data storage, the theme needs to be carried out. Construction, relationship mining, knowledge graph calculation, and algorithm training, so it is necessary to meet the needs of the data itself through the processing method of batch-stream combination.
Among them, content tagging is to understand news through automatic indexing, understand what information news is related to, and realize the classification and marking of content data based on text mining.
Specifically, automatic indexing is to call the Chinese semantic interface to tag the data in the database. The main tags include keywords, text classification, automatic abstraction, Chinese word segmentation, part-of-speech indexing, and named entities.
Text implementation process:
Sort out and formulate text classification system;
Develop text program;
Deploy text program;
Call the text interface during data access;
Manually index the training model according to the returned results to improve accuracy.
(7) Hierarchical data storage
The entire data architecture reasonably selects and designs related data architecture and system architecture models based on the current data asset status to support the platform's current and future data storage pressure requirements and external service requirements.
(8) Data processing
Through data processing, reorganize the data to make the data more usable. Use manual indexing to sort out important report data and establish report label dimensions. And sort out the indexing specifications according to requirements and data content to form a work instruction. Perform operations such as proofreading, full inspection, and label modification on the indexing results, and aggregate them into topics through indexing.
The platform will divide all data into different themes and construct, store and process them according to different themes. The media is a very complex industry, and it has demands for data in various industries. The media needs to dig out a large number of data from different industries to support news production and reporting. After the data comes in, they can dig out potential news points, generate topic selection plans, and help The user does work such as selecting topics.
(9) Data governance
Data governance is implemented at each stage of the entire data processing process. Data governance ensures that data is managed, and data management ensures that the managed data achieves the specified goals. Guide and supervise the specific data management and control of metadata management, standard management, quality management, safety management and other functions. Quality management mainly analyzes source system table data, verifies the source system data in terms of timeliness, completeness, accuracy, validity, and consistency, discovers and records data quality problems, and generates data quality problem reports. Metadata management describes the information in the use process of data. Through blood relationship analysis, key information can be tracked and recorded. Impact analysis helps understand the downstream data information of the analyzed object and quickly grasp the possible impact of metadata changes. Data management is an extension of data governance, including functions such as data asset view and intelligent search.
(10) Capability integration
Integrate data resource management, data services, data publishing and other capabilities, and through the construction of a systematic platform, achieve more efficient, concise and flexible data services for business systems and application development, so that upper-level applications will not be limited to the changeable underlying Data format, data type, data processing and management logic, as well as complex infrastructure construction and operation and maintenance, maximize the value of data.
There are three main aspects to the integration and opening of data platform capabilities.
First, the integration and openness of data. After any data enters the platform, it will be processed in the entire big data processing chain for calculation, integration, content structuring, and adding tags. At the same time, based on the range of data that users are interested in, the feature filtering of tags is performed to filter what users want. data.
Second, provide integration and openness of intelligent analysis capabilities. Through open algorithm capabilities, it helps users to apply data capabilities and algorithm capabilities, and provides text content entity recognition services, text deduplication judgment services, image person recognition services, and image labeling services.
Third, the integration and opening of product capabilities, for example, opening the capabilities of user portraits, content recommendations, and communication analysis to the outside world.
- Media data mid-stage landing practice
At present, Baixin Technology has served many national-level newspaper and publishing customers, including Xinhua News Agency, China Daily, Science and Technology Daily, Xinhuanet, Southern Newspaper, People's Publishing House, etc.
For example, the media intelligence data center established for Southern Press collects all-media big data resources, and performs distributed storage, efficient retrieval, and intelligent analysis of the collected massive all-media data. At present, the Southern Data Service Platform has thousands of database sets and hundreds of data intelligent application tools, which can provide multi-end integrated acquisition and editing auxiliary support, such as hotspot clustering, topic extension, content summary, machine translation, robot collaboration, entity influence New technologies and applications, such as portraits and personalized recommendations, help Nanfang News consolidate its data service capabilities, and use data and AI capabilities to empower all aspects of strategy, acquisition, editing and distribution.
Baixin Technology also built an all-media center for Xinhua News Agency, especially during the epidemic last year, it took only one month to quickly build and launch innovative products for special news applications such as the "Two Sessions Report". Through the professional data services provided by Zhongtai, it assists all media editing and editing.
to sum up
In summary, when a media organization has a certain data foundation and business scale, that is, its own data is diversified, the business scale is expanding, and the business is independent of each other, it needs the all-media middle station to help it solve the problems of efficiency, cost and quality. However, the construction of all-media mid-stage needs to be top-down, and detailed preliminary planning and design must be carried out. It must conform to the actual conditions of each media organization and cannot be copied in full. It must be adjusted in accordance with the actual situation to maximize value and drive Digital transformation of the media.
As a partner of Baifen Technology’s long-term service in the media field, Nanfang News Media Group has been at the forefront of intelligent media transformation. Its deputy editor-in-chief Cao Ke believes that the difficulties and challenges lie in the transition from media to data, and from communication. To service, from interviews to collection, from internal to external, the process of kinetic energy conversion requires conversion of ideas, conversion mechanisms, and conversion forms. Through the use of data, data maintenance, data aggregation, and data management, from data operation to operation data business, Form a new closed-loop system for media data production and application.
It is worth noting that for the construction of an all-media middle station, the media organization first needs to have a certain data foundation and business scale. Only when its own data is diversified, the business scale is expanding, and the business is mutually independent, it is urgent to solve the efficiency, Cost and quality issues.
Moreover, media data cannot be limited to current media asset data, but should be various types of data based on media connection capabilities, geographic advantages, and service positioning characteristics. The construction of the media database cannot remain in the simple media asset database era. Revitalizing the use of media data requires new thinking. The strategic goal of accelerating the development of media integration and innovation in the digital economy era is the strategic goal, the value of "data assets" is the consideration, the market demand is the guide, and the needs of different users and market needs are focused on creating practical and effective Media data products and data services.
Note: Some views of the article are quoted from "Smart Media, Data First-Practice and Exploration of the Construction of the Southern Press "Central Database"", "People's Data, Xinhua Data, Caixin Data, Southern Data-New Concept of "Media Data" And Prospective Analysis" and other articles.
Moreover, media data cannot be limited to current media asset data, but should be various types of data based on media connection capabilities, geographic advantages, and service positioning characteristics. The construction of the media database cannot remain in the simple media asset database era. Revitalizing the use of media data requires new thinking. The strategic goal of accelerating the development of media integration and innovation in the digital economy era is the strategic goal, the value of "data assets" is the consideration, the market demand is the guide, and the needs of different users and market needs are focused on creating practical and effective Media data products and data services.
Pay attention to the realization of data circulation and create valuable databases. Data accumulation is one aspect, and more important is the realization of data realization to realize the value-added of media data assets. Whether it is traditional media or new media, on the basis of the original business profit model, grasp the opportunities of the development of the digital economy, open up media data service capabilities, and open up new profit channels.