I talked about the value, construction ideas, and examples of the data warehouse. After completing the concept, logic, and physical model design of the data warehouse, the product selection of the data warehouse is also a part that needs to be considered. It can be selected according to the amount of data storage, query efficiency, and concurrency. MPP data warehouse and Hadoop-based distributed data warehouse, etc.;
1. MPP or Hadoop
Here we continue to explain with the diagram used before. The characteristic of the data warehouse is to process warm data and cold data, and provide offline analysis capabilities for business analysis. Therefore, the solution of Hadoop+MPP data warehouse combination is generally selected. Hive can provide large quantities Historical data storage and computing capabilities, Hbase can provide fast retrieval capabilities for semi-structured documents, and MPP can provide fast query capabilities based on a powerful and high compression ratio;

2. MPP data warehouse features
In the MPP solution, I have been in contact with vertica and GP, and I did not use td data warehouse during the internship at teradata;

The characteristics of data warehouse are large batches of queries and indexes, a small amount of re-search work, MPP (Massively Parallel Processing), that is, the general characteristics of massively parallel processing databases:
① Columnar storage means high compression ratio, high IO capability, fast query capability, intelligent index (when data is written);
② Shared nothing means mutual independence of nodes and redundant backup of data;
③ High scalability and high security of distributed storage/computing, storage/computing;
The architecture of MPP is divided into three types. GP is a master/slave model with a unified query entry (master), vertica is a non-centralized architecture, all nodes provide query services, and gbase is a storage/management dual-center architecture;
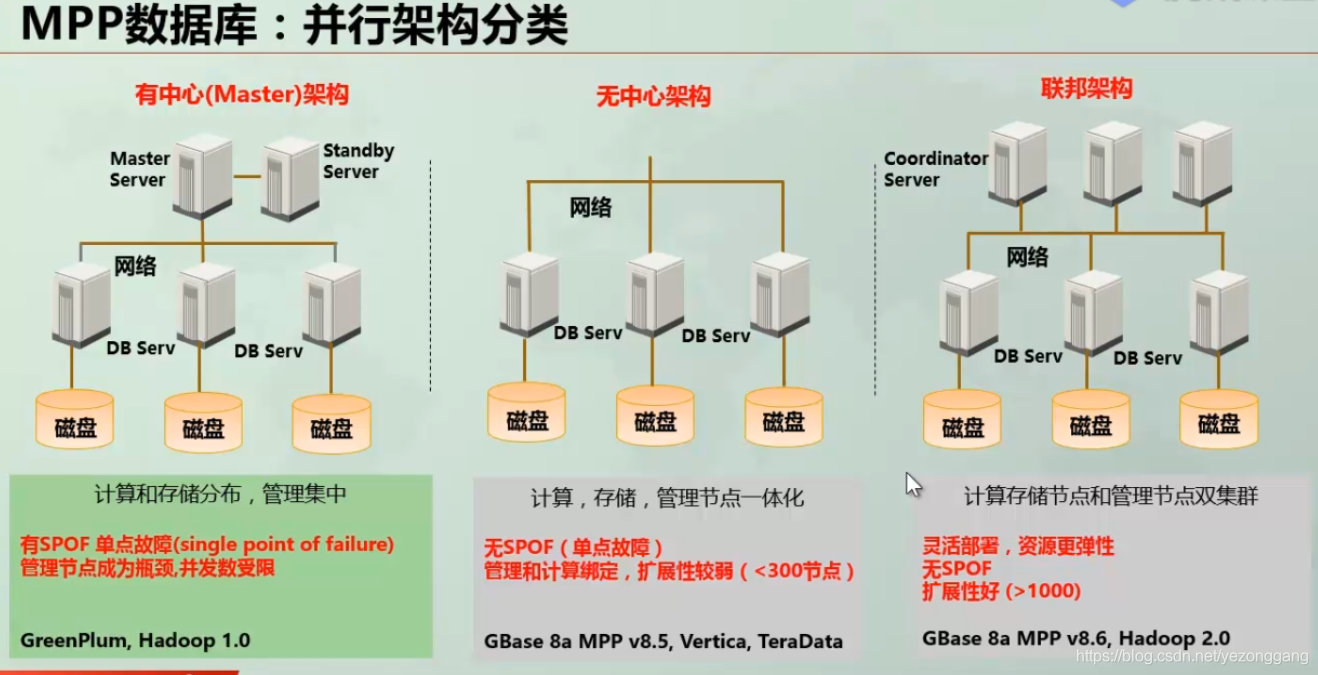
Shared nothing mode: x86 machines build a high-scalable computing/storage cluster, split multiple data and back them up;
shared disk mode: dedicated minicomputer, storing 1 copy of data;

Tic 、 Vertica 、 Greenplum 、 Gbase
Vertica is HP's data warehouse product, mpp without a central architecture, all nodes can provide connection query services, with very powerful performance;
Official document address: https://my.vertica.com/documentation/vertica/
Cluster management: vertica system learning , vertica cluster management
Greenplum is an open source data warehouse product based on the postgre database. Its database kernel is the same as vertica. The authors of both are the same person. GP is a master/slave model. Only the master provides query capabilities. Compared with vertica, there is a single point of failure of the master. risk;
Official document address: https://gp-docs-cn.github.io/
Deployment, features: greenplum cluster deployment , greenplum cluster management
gbase is a domestic digital warehouse product with a federal structure and very few documents. However, if the relevant services are in place after the product is purchased, the implementation is not complicated. The project is currently in use and is under investigation;
Deployment, features: Gbase features, deployment, cluster management