1. Common lose loss function?
1. Cross entropy loss function: used together with softmax regression, the output is a probability distribution.
2. Exponential loss function
3. Square loss function (least squares method)
2. Explain clearly the precision rate and recall rate:
The formula for precision is that it calculates the proportion of all "correctly retrieved items (TP)" to all "actually retrieved (TP+FP)".
The formula of the recall rate (recall) is that it calculates the proportion of all "correctly retrieved items (TP)" to all "items that should be retrieved (TP+FN)".
3.MobileNet
mobilenet was proposed by Google.
Advantages: small size, small calculation, suitable for convolutional neural networks of mobile devices.
Can achieve classification/target detection/semantic segmentation;
Miniaturization:
- The convolution kernel is decomposed, and the 1xN and Nx1 convolution kernels are used to replace the NxN convolution kernel.
- Using bottleneck structure, represented by SqueezeNet
- Save as a low-precision floating point number, such as Deep Compression
- Redundant convolution kernel pruning and Huffman coding.
。
mobilenet v1:
With reference to the traditional VGGNet and other chain architectures, the depth of the network is improved by stacking convolutional layers, thereby improving the recognition accuracy. Disadvantages: gradient dispersion phenomenon.
(Gradient dispersion: chain rule of derivative, successive multiple layers of gradient less than 1 will make the gradient smaller and smaller, eventually leading to a layer gradient of 0)
What problem do you want to solve?
In real scenarios, such as mobile devices, embedded devices, autonomous driving, etc., computing power will be limited, so the goal is to build a small and fast model.
What method was used to solve the problem (implementation):
- In the MobileNet architecture, deep separable convolution is used instead of traditional convolution.
- In the MobileNet network, two shrinkage hyperparameters are introduced: width factor and resolution multiplier.
What are the problems:
- The structure of MobileNet v1 is too simple, it is similar to the straight structure of VGG, resulting in the cost of this network is actually not high. If a series of subsequent ResNet, DenseNet and other structures (reusing image features and adding shortcuts) are introduced, the performance of the network can be greatly improved.
- There are potential problems with deep convolution, and some kernel weights are zero after training.
Deep separable convolution idea?
In essence, the standard convolution is divided into two steps: depthwise convolution and pointwise convolution, the input and output are the same.
Depthwise convolution: Use a separate convolution kernel for each input channel.
Pointwise convolution: 1×1 convolution, used to combine the output of depthwise convolution.
Most of the calculations (about 95%) and parameters (75%) of MoblieNet are in the 1×1 convolution, and most of the remaining parameters (about 24%) are in the fully connected layer. Since the model is small, the regularization methods and data enhancement can be reduced, because the small model is relatively difficult to overfit.
About mobilenet v2:
mobileNet v2 mainly introduces two changes: Linear Bottleneck and Inverted Residual Blocks.
About Inverted Residual Blocks: The
structure of MobileNet v2 is based on inverted residual. Its essence is a residual network design. The traditional Residual block has a large number of channels at both ends of the block. There are few in the middle;
and the inverted residual designed in this article is that the number of channels at both ends of the block is small, and the number of channels in the block is large. In addition, the depth separable convolution is retained
About Linear Bottlenecks: The
region of interest remains non-zero after ReLU, which is approximately regarded as a linear transformation;
ReLU can maintain the integrity of the input information, but it is limited to the low-dimensional subspace of the input space.
For low-latitude spatial processing, ReLU is approximated as a linear conversion.
Comparison between v1 and v2:
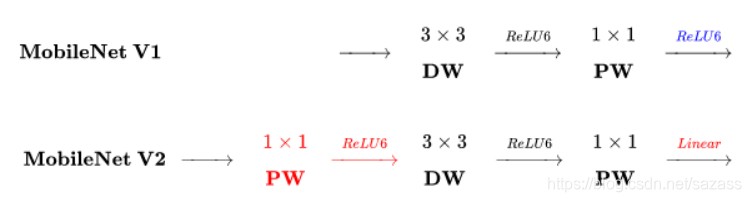
Similarities:
- Both use Depth-wise (DW) convolution and Point-wise (PW) convolution to extract features. Together, these two operations are called Depth-wise Separable Convolution, which was widely used in Xception before. The advantage of this is that theoretically, the time complexity and space complexity of the convolutional layer can be doubled.
Differences:
2. v2 adds a new PW convolution before DW convolution. The reason for this is because DW convolution does not have the ability to change the number of channels due to its own computational characteristics. As many channels as the upper layer gives it, how many channels it has to output. Therefore, if the number of channels given by the upper layer itself is small, DW can only extract features in low-dimensional space, so the effect is not good enough.
Now v2, in order to improve this problem, matches a PW before each DW, which is specifically used for dimension upgrading, and defines the dimension upgrading coefficient as 6, so that regardless of the number of input channels, after the first PW dimension upgrade, DW works hard in relatively higher dimensions.
V2 removes the activation function of the second pw, which the author calls Linear Bottleneck. The reason is that the author believes that the activation function can effectively increase the nonlinearity in the high-dimensional space, while it will destroy the eigenvalues in the low-dimensional space, which is not as good as the linear effect. The second main function of PW is dimensionality reduction, so according to the above theory, ReLU6 should not be used after dimensionality reduction.
Summarizing mobileNet v2: The
most difficult to understand is Linear Bottlenecks. It is very simple to implement, that is, there is no ReLU6 after the second PW in MobileNetv2. For low-latitude spaces, linear mapping will retain features, while nonlinear mapping will destroy feature.
mobileNet v3
Efficient network building modules:
v3 is a model obtained by neural architecture search. The internal modules used are:
1. The v1 model introduces deep separable convolution;
2. v2 introduces an inverted residual structure with a linear bottleneck;
3. Lightweight attention model based on squeeze and excitation structure;
Complementary search:
In the network structure search, the author combines two technologies: resource-constrained NAS and NetAdapt. The former is used to search for various modules of the network under the premise of limited calculations and parameters, so it is called module-level search.