Checkpoint introduction
The checkpoint mechanism is the cornerstone of Flink reliability. It can ensure that when a certain operator fails due to some reasons (such as abnormal exit), the Flink cluster can restore the state of the entire application flow graph to a state before the failure to ensure the application Consistency of flow graph status. The principle of Flink's checkpoint mechanism comes from the "Chandy-Lamport algorithm" algorithm.
When each application that needs checkpoint is started, Flink's JobManager creates a CheckpointCoordinator (checkpoint coordinator) for it , and CheckpointCoordinator is solely responsible for making snapshots of this application.
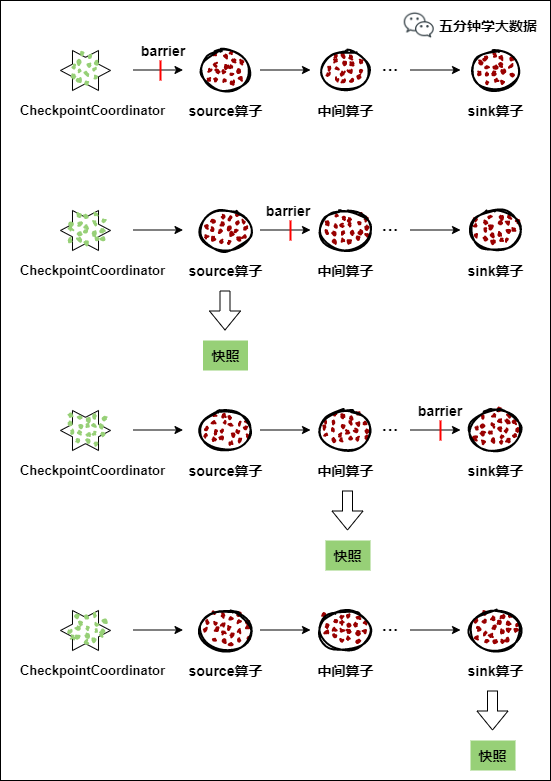
1) CheckpointCoordinator (checkpoint coordinator) periodically sends barriers to all source operators of the flow application.
2) When a source operator receives a barrier, it suspends the data processing process, then makes a snapshot of its current state and saves it to the specified persistent storage, and finally reports its snapshot production to CheckpointCoordinator, and at the same time Broadcast the barrier to all downstream operators to resume data processing
3) After the downstream operator receives the barrier, it will suspend its own data processing process, and then make a snapshot of its own related state and save it to the specified persistent storage, and finally report its own snapshot to CheckpointCoordinator, and at the same time all The downstream operator broadcasts the barrier and resumes data processing.
4) Each operator continuously makes a snapshot according to step 3 and broadcasts it downstream, until the barrier is passed to the sink operator, and the snapshot is completed.
5) After CheckpointCoordinator receives reports from all operators, it considers that the snapshot of this cycle is successfully made; otherwise, if it does not receive reports from all operators within the specified time, it is considered that the snapshot of this cycle has failed.
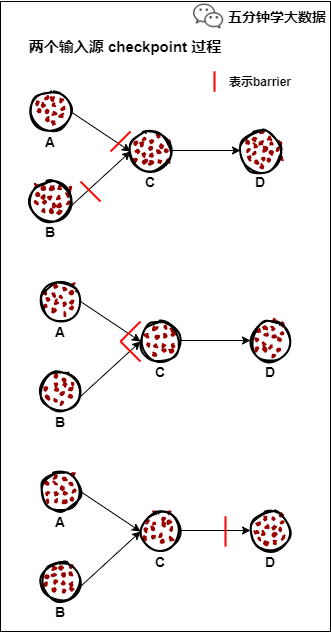
If an operator has two input sources, it temporarily blocks the input source that received the barrier first, and waits until the barrier with the same number of the second input source arrives, then takes a snapshot of itself and broadcasts the barrier downstream. The details are shown in the figure below:
1) Assume that operator C has two input sources, A and B
2) In the i-th snapshot period, due to some reasons (such as processing delay, network delay, etc.) the barrier from input source A comes first. At this time, operator C temporarily blocks the input channel of input source A, only Receive input source B data.
3) When the barrier from input source B arrives, operator C will take a snapshot of itself and report its snapshot production to CheckpointCoordinator, then merge the two barriers into one and broadcast to all operators downstream.
4) When a failure occurs due to some reasons, CheckpointCoordinator notifies all operators on the flow graph to restore to the checkpoint state of a certain period, and then resume data flow processing. The distributed checkpoint mechanism ensures that the data is processed only once (Exactly Once).
Persistent storage
MemStateBackend
The persistent storage mainly saves the snapshot data in the memory of the JobManager. It is only suitable for testing and the snapshot data volume is very small. It is not recommended for large-scale commercial deployment.
Limitations of MemoryStateBackend :
By default, the size limit of each state is 5 MB. You can increase this value in the constructor of MemoryStateBackend.
Regardless of the configured maximum state size, the state cannot be larger than the size of the akka frame (see configuration).
The aggregation state must fit in the JobManager memory.
It is recommended that MemoryStateBackend be used for :
Local development and debugging.
For jobs with few states, such as jobs that contain only one recording function (Map, FlatMap, Filter,...), kafka consumers need very few states.
FsStateBackend
The persistent storage mainly saves the snapshot data in the file system. Currently, the supported file systems are mainly HDFS and local files. If you use HDFS, you need to pass in a path starting with "hdfs://" when initializing FsStateBackend (ie: new FsStateBackend("hdfs:///hacluster/checkpoint")), if you use local files, you need to pass in The path starting with "file://" (ie: new FsStateBackend("file:///Data")). In a distributed situation, it is not recommended to use local files. If an operator fails on node A, it is restored on node B. When using local files, the data on node A cannot be read on B, resulting in failure to restore the state.
Suggest FsStateBackend:
Jobs with large status, long window, large key/value status.
All high availability settings.
RocksDBStateBackend
RocksDBStatBackend is between the local file and HDFS. The function of RocksDB is usually used to persist the data to the local file. When making a snapshot, the local data is made into a snapshot and persisted to FsStateBackend (FsStateBackend does not need to be specified by the user, Just pass in HDFS or local path during initialization, such as new RocksDBStateBackend("hdfs:///hacluster/checkpoint") or new RocksDBStateBackend("file:///Data")).
If the user uses a custom window (window), it is not recommended to use RocksDBStateBackend. In the custom window, the state is saved in the StatBackend in the form of ListState. If there are multiple value values in a key value, RocksDB will read the ListState very slowly, which affects performance. Users can choose FsStateBackend+HDFS or RocksStateBackend+HDFS according to the specific conditions of the application.
grammar
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000)
// advanced options:
// 设置checkpoint的执行模式,最多执行一次或者至少执行一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 设置checkpoint的超时时间
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 如果在只做快照过程中出现错误,是否让整体任务失败:true是 false不是
env.getCheckpointConfig.setFailTasksOnCheckpointingErrors(false)
//设置同一时间有多少 个checkpoint可以同时执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
Two ways to modify State Backend
The first type: single task adjustment
Modify the current task code
env.setStateBackend(new FsStateBackend("hdfs://namenode:9000/flink/checkpoints"));
or new MemoryStateBackend()
or new RocksDBStateBackend(filebackend, true); [Need to add third-party dependencies]
The second type: global adjustment
Modify flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
Note: The value of state.backend can be the following: jobmanager(MemoryStateBackend), filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
Advanced options of Checkpoint
The default checkpoint function is disabled. When you want to use it, you need to enable checkpoint first. The default checkpoint mode is Exactly-once.
//配置一秒钟开启一个checkpoint
env.enableCheckpointing(1000)
//指定checkpoint的执行模式
//两种可选:
//CheckpointingMode.EXACTLY_ONCE:默认值
//CheckpointingMode.AT_LEAST_ONCE
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
一般情况下选择CheckpointingMode.EXACTLY_ONCE,除非场景要求极低的延迟(几毫秒)
注意:如果需要保证EXACTLY_ONCE,source和sink要求必须同时保证EXACTLY_ONCE
//如果程序被cancle,保留以前做的checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
默认情况下,检查点不被保留,仅用于在故障中恢复作业,可以启用外部持久化检查点,同时指定保留策略:
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:在作业取消时保留检查点,注意,在这种情况下,您必须在取消后手动清理检查点状态
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业在被cancel时,删除检查点,检查点仅在作业失败时可用
//设置checkpoint超时时间
env.getCheckpointConfig.setCheckpointTimeout(60000)
//Checkpointing的超时时间,超时时间内没有完成则被终止
//Checkpointing最小时间间隔,用于指定上一个checkpoint完成之后
//最小等多久可以触发另一个checkpoint,当指定这个参数时,maxConcurrentCheckpoints的值为1
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
//设置同一个时间是否可以有多个checkpoint执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
指定运行中的checkpoint最多可以有多少个
env.getCheckpointConfig.setFailOnCheckpointingErrors(true)
用于指定在checkpoint发生异常的时候,是否应该fail该task,默认是true,如果设置为false,则task会拒绝checkpoint然后继续运行
Flink's restart strategy
Flink supports different restart strategies, which control how the job is restarted after it fails. The cluster can be restarted through the default restart strategy. This default restart strategy is usually used when no restart strategy is specified. If a restart strategy is specified when the job is submitted, this restart strategy will override the default restart strategy of the cluster.
Overview
默认的重启策略是通过Flink的 flink-conf.yaml 来指定的,这个配置参数 restart-strategy 定义了哪种策略会被采用。如果checkpoint未启动,就会采用 no restart 策略,如果启动了checkpoint机制,但是未指定重启策略的话,就会采用 fixed-delay 策略,重试 Integer.MAX_VALUE 次。请参考下面的可用重启策略来了解哪些值是支持的。
每个重启策略都有自己的参数来控制它的行为,这些值也可以在配置文件中设置,每个重启策略的描述都包含着各自的配置值信息。
除了定义一个默认的重启策略之外,你还可以为每一个Job指定它自己的重启策略,这个重启策略可以在 ExecutionEnvironment 中调用 setRestartStrategy() 方法来程序化地调用,注意这种方式同样适用于 StreamExecutionEnvironment。
下面的例子展示了如何为Job设置一个固定延迟重启策略,一旦有失败,系统就会尝试每10秒重启一次,重启3次。
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 延迟时间间隔
))
固定延迟重启策略(Fixed Delay Restart Strategy)
固定延迟重启策略会尝试一个给定的次数来重启Job,如果超过了最大的重启次数,Job最终将失败。在连续的两次重启尝试之间,重启策略会等待一个固定的时间。
重启策略可以配置flink-conf.yaml的下面配置参数来启用,作为默认的重启策略:
restart-strategy: fixed-delay
例子:
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
固定延迟重启也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 重启时间间隔
))
失败率重启策略
失败率重启策略在Job失败后会重启,但是超过失败率后,Job会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
失败率重启策略可以在flink-conf.yaml中设置下面的配置参数来启用:
restart-strategy:failure-rate
例子:
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
失败率重启策略也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启尝试的时间间隔
))
无重启策略
Job直接失败,不会尝试进行重启
restart-strategy: none
无重启策略也可以在程序中设置
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.noRestart())