Flink Checkpoint in-depth understanding
- How to understand state in flink
- Case understanding of the state of flink (state)
- Why state management is needed
- What information is saved in checkpoint
- In the case of multiple parallelism and multiple Operators, the CheckPoint process
- What is barrier alignment?
- What is barrier misalignment?
- case study
- FAQ
How to understand state in flink
- State generally refers to the data stored in the processing of various elements/events by state functions and operators in flink (note: state data can be modified and queried, and can be maintained by itself. According to your own business scenarios, Save historical data or intermediate results to state (state);
Example of using state calculation:
- When the application searches for certain event patterns, the state will store the sequence of events encountered so far.
- When aggregating events every minute/hour/day, the state saves the pending aggregation.
- When training a machine learning model on a stream of data points, the state maintains the current version of the model parameters.
- When historical data needs to be managed, the state allows effective access to past events.
Case understanding of the state of flink (state)
- Stateless computing refers to the fact that when data enters Flink and passes through the operator, only the current data needs to be processed to get the desired result; stateful computing requires some historical state or related operations to calculate the correct result ;
Examples of stateless computing:
- For example: we just perform a string splicing, input a, output a_666, input b, output b_666. The output result has nothing to do with the previous state, and conforms to idempotence.
Idempotence: It means that the results of one request or multiple requests initiated by the user for the same operation are consistent, and there will be no side effects due to multiple clicks;
Examples of stateful computing:
- Take the calculation of pv/uv in wordcount as an example: the
output result is related to the previous state and does not conform to idempotence. If you visit multiple times, pv will increase;
Why state management is needed
Streaming jobs are characterized by running 7*24 hours, data is not repeated consumption, no loss, only one calculation is guaranteed, real-time output of data is not delayed, but when the state is large, the memory capacity is limited, or the instance runs crashed, or needed In the case of extended concurrency, how to ensure the correct management of the state and the correct execution of the task when the task is executed again, the state management is particularly important
The ideal state management is:
- Easy to use, flink provides a rich data structure, simple and easy to use interface;
- Efficient, flink reads and writes the state quickly, can be scaled horizontally, and saving the state does not affect computing performance;
- Reliable, flink can make the state persistent, and can guarantee exactly-once semantics;
Checkpoint execution process in flink
- The checkpoint mechanism is the cornerstone of Flink reliability. It can ensure that when a certain operator fails due to some reasons (such as abnormal exit), the Flink cluster can restore the state of the entire application flow graph to a state before the failure to ensure the application Consistency of flow graph status. The principle of Flink's checkpoint mechanism comes from the "Chandy-Lamport algorithm" algorithm. (Distributed snapshot calculation)
- When every application that needs checkpoint is started, Flink's JobManager creates a CheckpointCoordinator for it, and CheckpointCoordinator is solely responsible for making the snapshot of this application.
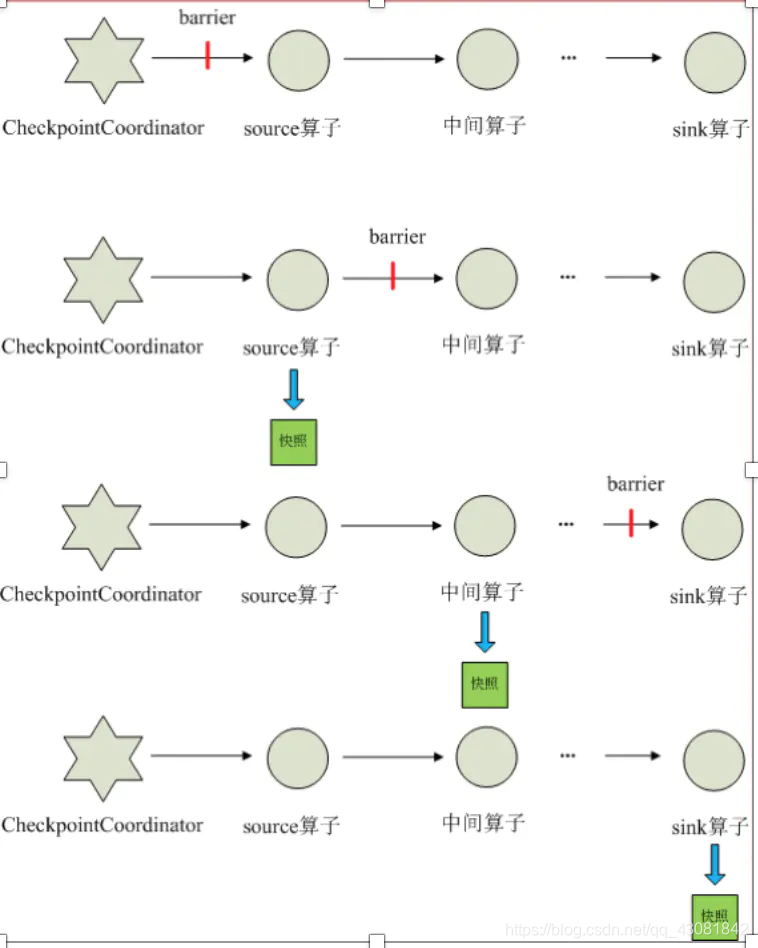
- CheckpointCoordinator periodically sends barriers to all source operators of the stream application.
- When a source operator receives a barrier, it suspends the data processing process, then makes a snapshot of its current state, and saves it to the specified persistent storage, and finally reports its snapshot production to CheckpointCoordinator and at the same time to itself All downstream operators broadcast the barrier and resume data processing
- After the downstream operator receives the barrier, it will suspend its own data processing process, and then make a snapshot of its own related state, and save it to the designated persistent storage, and finally report its own snapshot to CheckpointCoordinator, and at the same time to all its downstream operators. The child broadcasts the barrier to resume data processing.
- Each operator continuously creates a snapshot according to step 3 and broadcasts it downstream, until the barrier is passed to the sink operator, and the snapshot is completed.
- When CheckpointCoordinator receives reports from all operators, it considers that the snapshot of the cycle is successfully made; otherwise, if it does not receive reports from all operators within the specified time, it is considered that the snapshot of this cycle has failed;
What information is saved in checkpoint
- What are the specific functions CheckPoint does? Why can the task be resumed through CheckPoint after the task is suspended?
- CheckPoint saves the state at certain moments in history by taking a snapshot of the program. When the task hangs, it will restore the task from the last complete snapshot by default. The question is, what the hell is a snapshot? Can you eat it?
- SnapShot translates as a snapshot, which means to save some information in the program, which can be used to restore it later. For a Flink task,
What information is stored in the snapshot? Take the wordcount of kafka data consumed by flink as an example:
- We read a piece of log from Kafka, parse the app_id from the log, and then put the statistical result into a Map set in the memory, with app_id as the key and the corresponding pv as the value. You only need the corresponding app_id each time. Put the pv value of +1 into the Map;
- kafka topic:test;
- The flink calculation process is as follows:

Kafka topic has one and only one partition
- Assume that Kafka's topic-test has only one partition, and Flink's Source task records the offsets of all partitions currently consumed to the Kafka test topic
例:(0,1000)表示0号partition目前消费到offset为1000的数据
- The pv task of flink records the current calculated pv value of each app. For the convenience of explanation, I have two apps here: app1, app2
例:(app1,50000)(app2,10000)
表示app1当前pv值为50000
表示app2当前pv值为10000
每来一条数据,只需要确定相应app_id,将相应的value值+1后put到map中即可;
In this case, what information did CheckPoint record?
- What is recorded is actually the offset information of the nth CheckPoint consumption and the pv value information of each app. Record the current state information of CheckPoint that occurred, and save the state information to the corresponding state backend. (Note: The state backend is the place to save the state. It decides how to save the state and how to ensure that the state is highly available. We only need to know that we can get the offset information and pv information from the state backend. The state backend must be high Available, otherwise our state backend often fails, which will result in the inability to restore our application through checkpoint).
Example:
chk-100
offset: (0, 1000)
pv: (app1, 50000) (app2, 10000)
This status information indicates that at the 100th CheckPoint, partition 0 offset has consumed 1000, and the pv statistics result is (app1, 50000) ( app2, 10000) The
task is hung up, how to restore it?
- Suppose we set a CheckPoint every three minutes, and after saving the CheckPoint state of the chk-100 mentioned above, after ten seconds, the offset has been consumed to (0, 1100), and the pv statistics result becomes (app1, 50080 ) (App2, 10020), but suddenly the task hangs, what should I do?
- Don’t panic, it’s actually very simple. Flink only needs to consume from the offset (0, 1000) saved by the most recent successful CheckPoint. Of course, the pv value should also follow the pv value in the state (app1, 50000) (app2, 10000) ) For accumulation, it cannot be accumulated from (app1, 50080) (app2, 10020), because when the partition 0 offset consumption reaches 1000, the PV statistics result is (app1, 50000) (app2, 10000)
- Of course, if you want to recover from the state of offset (0, 1100) pv (app1, 50080) (app2, 10020), you can't do it, because the program suddenly hangs at that moment, and this state is not saved at all. The most efficient way we can do is to recover from the last successful CheckPoint, which is what I have always called chk-100;
The above explanation is basically the work undertaken by CheckPoint, and the scene described is relatively simple.
- Question, the task of calculating pv is always running, how does it know when to take this snapshot? In other words, how does the task that calculates pv guarantee that the pv value (app1, 50000) (app2, 10000) calculated by itself is the statistical result at the moment of offset (0, 1000)?
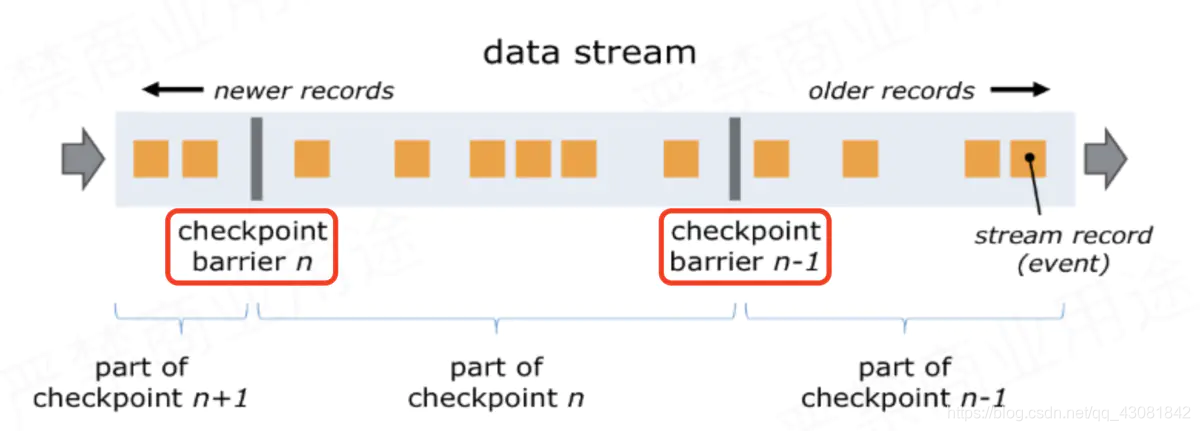
Flink adds a thing called barrier to the data (barrier Chinese translation: barrier). There are two barriers in the red circle in the figure below;
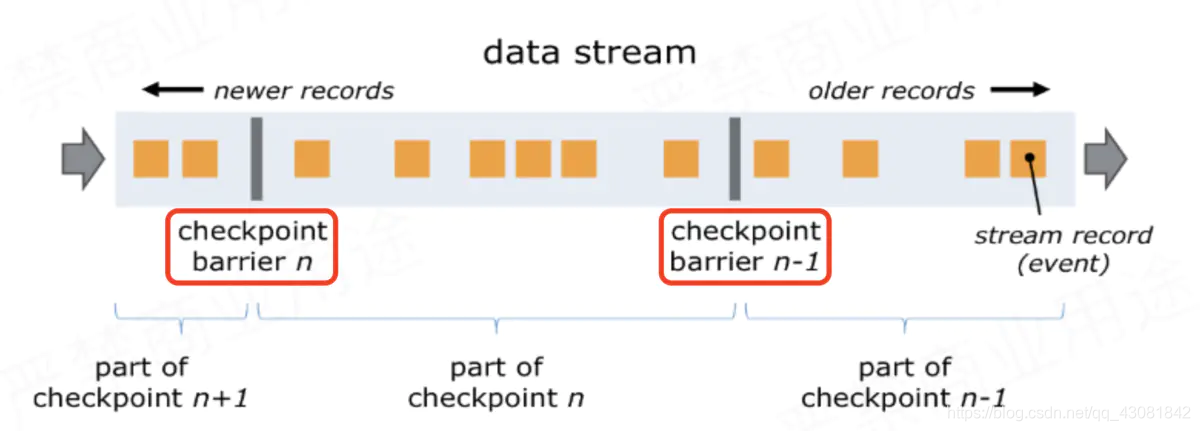
- The barrier is generated from the Source Task and flows to the Sink Task. During this period, all tasks will trigger themselves to take a snapshot as long as they encounter the barrier;
- The snapshot taken at CheckPoint barrier n-1 refers to all the status data of the job from the beginning to the barrier n-1;
- The snapshot taken at barrier n refers to all the state data from the start of the job to the processing of barrier n;
- Corresponding to the pv case, after the Source Task received the CheckPoint trigger request of JobManager numbered chk-100, it found that it happened to receive the data at kafka offset (0, 1000), so it would go to offset (0, 1000). After that, insert a barrier before the offset (0, 1001) data, and then start to take a snapshot by itself, that is, save the offset (0, 1000) to the state backend chk-100. Then the barrier is sent downstream. When the PV task receives the barrier, it will also suspend processing data, and save the PV information (app1, 50000) (app2, 10000) stored in its memory to the state backend chk-100 . OK, flink probably uses this principle to save snapshots;
- The task of statistics PV receives the barrier, which means that the data before the barrier has been processed, so there will be no data loss.
- The role of the barrier is to separate the data. In the CheckPoint process, there is a synchronization snapshot that cannot process the data after the barrier. Why?
- If the data is being processed while the snapshot is being taken, the processed data may modify the content of the snapshot, so first pause processing the data and save the snapshot in the memory before processing the data
- In terms of the case, the task that counts PV wants to take a snapshot of (app1, 50000) (app2, 10000), but if the data is still being processed, the snapshot may not be saved yet and the status has become (app1, 50001) ( app2, 10001), the snapshot is not accurate, and Exactly Once cannot be guaranteed;
State interaction in stream computing:
simple scenario, accurate one-time fault tolerance method: periodic snapshots of consumption offset and statistical status information or statistical results. When
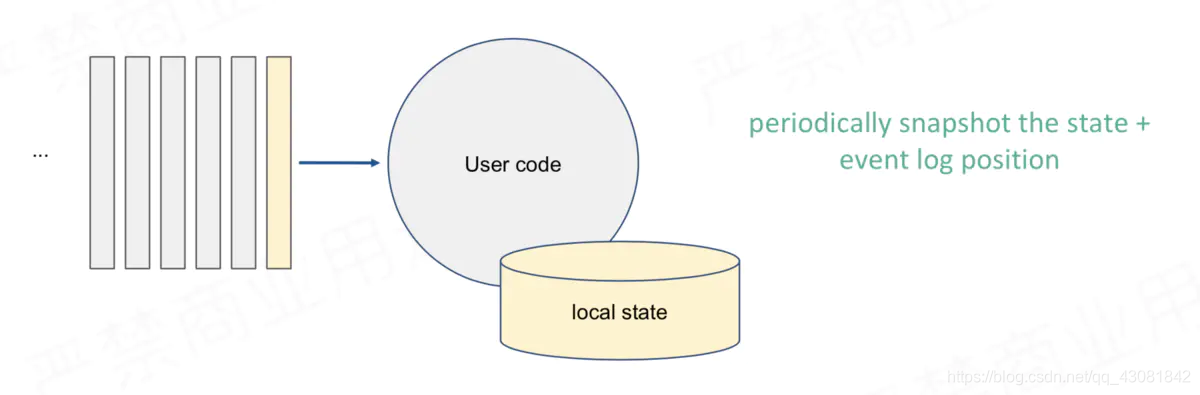
consuming to X position, save the state corresponding to X when
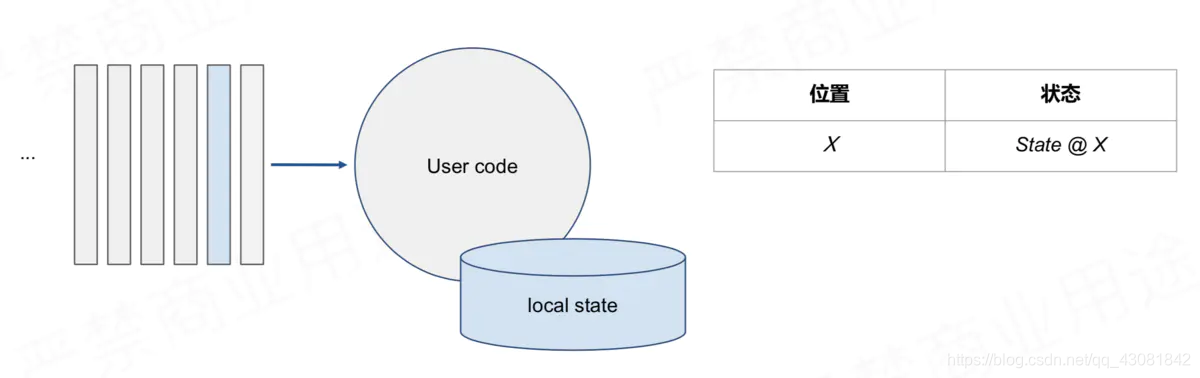
consuming to Y position , Save the state corresponding to Y
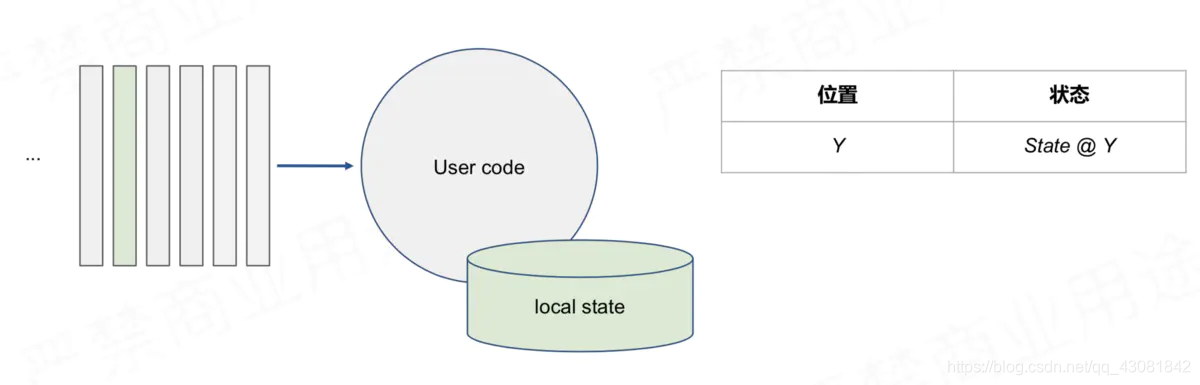
In the case of multiple parallelism and multiple Operators, the CheckPoint process
Problems and challenges faced by distributed state fault tolerance
- How to ensure that the state has an accurate fault tolerance guarantee?
- How to generate a globally consistent snapshot for multiple operators with local state in a distributed scenario?
- How to generate snapshots without interrupting operations?
In the case of multiple parallelism and multiple Operator instances, how to make a globally consistent snapshot?
- All Operators will take a snapshot of their own state after encountering the barrier during the running process, and save it to the corresponding state. The back end
corresponds to the PV case: some Operators calculate the PV of app1, and some Operators calculate the PV of app2. When they encounter the barrier, they all need to snapshot the current statistics of PV information to the state backend.
Simple snapshot of multiple parallel graphs and
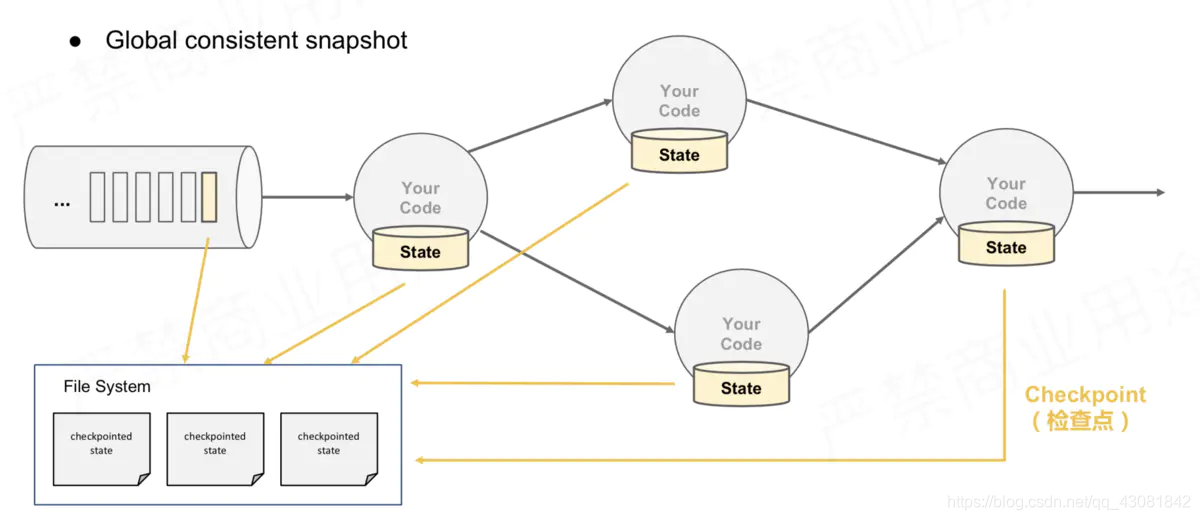
multiple operator state recovery
How to do this snapshot? All barrier policy before using the
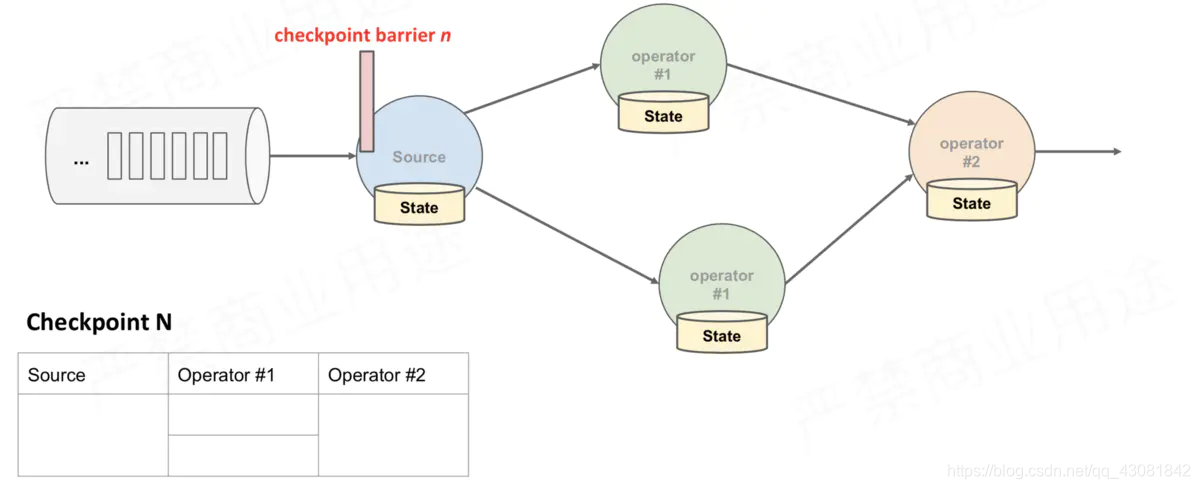
JobManager sends Source Task CheckPointTrigger, Source Task CheckPoint barrier will be placed in the data stream;
Source Task itself to do a snapshot, and saved to the back-end state;
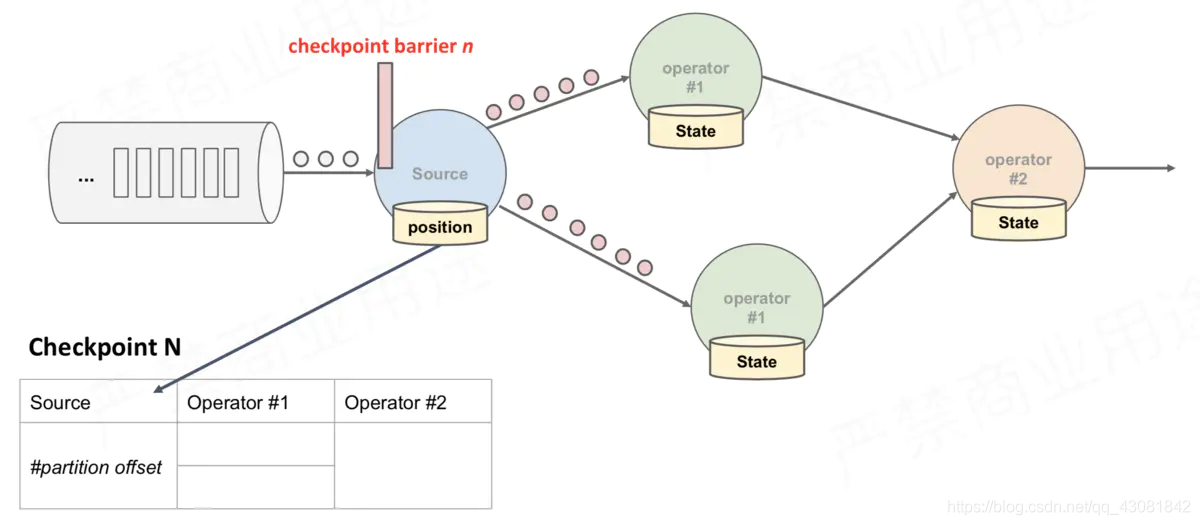
Source Task barrier will now send a data stream to downstream;
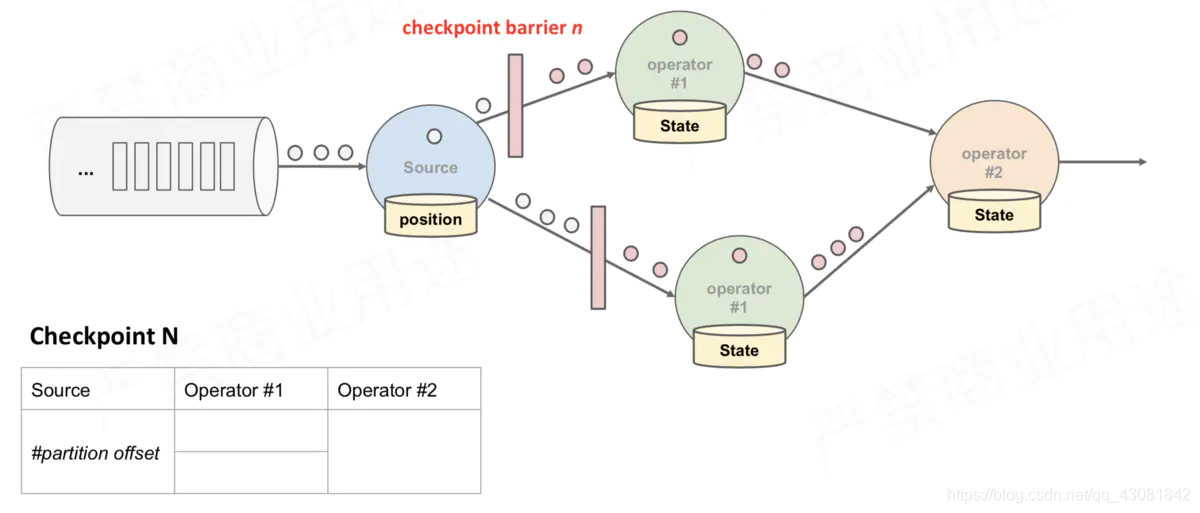
when After the downstream Operator instance receives the CheckPoint barrier, it takes a snapshot of itself. In the
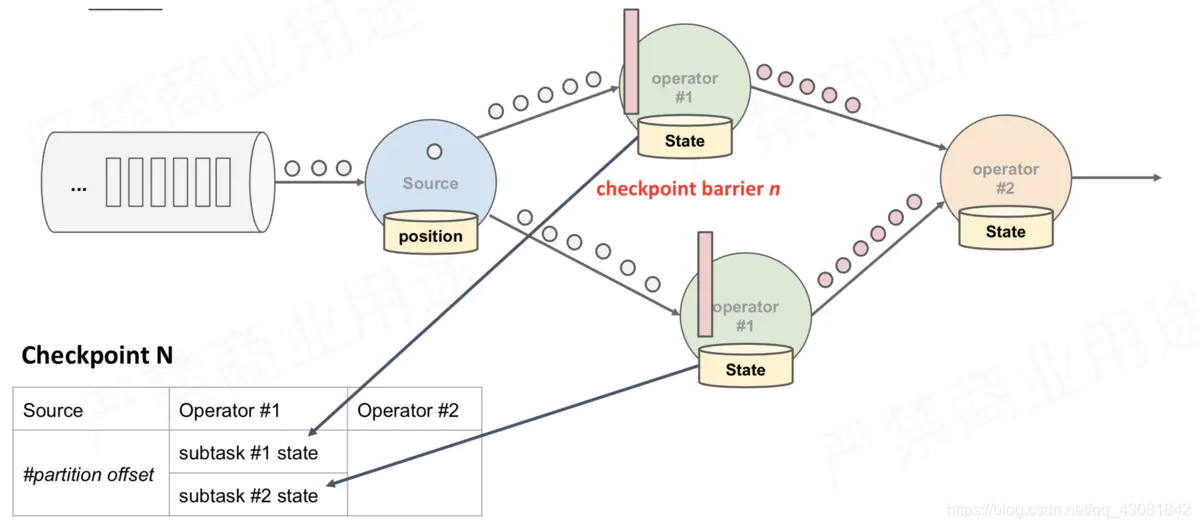
above figure, there are 4 Operator instances with states, and the corresponding state backend can be imagined as filling in 4 grids. The entire CheckPoint process can be regarded as the process of the Operator instance filling in its own grid. The Operator instance writes its own state to the corresponding grid in the state backend. When all the grids are filled, it can simply be considered that a complete CheckPoint is finished.
The above is just a snapshot process, the entire CheckPoint execution process is as follows
- The CheckPointCoordinator on the JobManager side sends CheckPointTrigger to all Source Tasks, and the Source Task will insert the CheckPoint barrier in the data stream.
- When the task receives all the barriers, it continues to pass the barriers to its own downstream, and then executes the snapshot itself, and writes its own state asynchronously to the persistent storage. Incremental CheckPoint just writes the latest part of the update to the external storage; in order to make CheckPoint downstream as soon as possible, it will send the barrier to the downstream first, and then synchronize the snapshot itself.
- When the task completes the backup, it will notify the CheckPointCoordinator of the JobManager of the address of the backup data (state handle); if the duration of the CheckPoint exceeds the timeout set by the CheckPoint, the CheckPointCoordinator has not collected all the State Handle, the CheckPointCoordinator will think If this CheckPoint fails, all status data generated by this CheckPoint will be deleted.
- Finally, the CheckPoint Coordinator will encapsulate the entire StateHandle into a completed CheckPoint Meta and write it to hdfs.
What is barrier alignment?

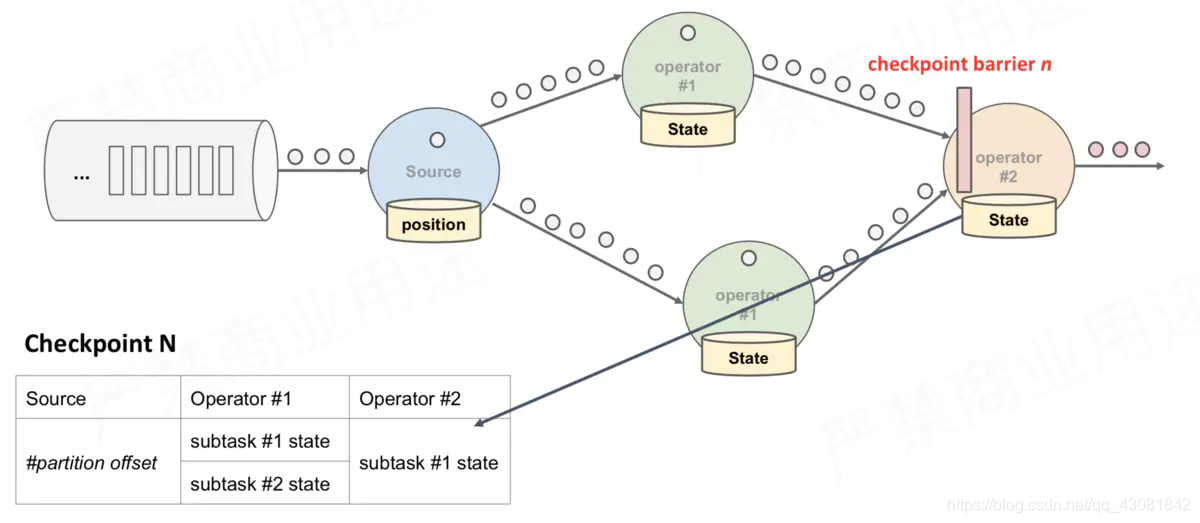
- Once the Operator receives CheckPoint barrier n from the input stream, it cannot process any data records from the stream until it receives barrier n from all other inputs. Otherwise, it will mix records belonging to snapshot n and records belonging to snapshot n + 1;
- The stream that received barrier n is temporarily shelved. The records received from these streams will not be processed, but put into the input buffer.
- In the second picture in the above figure, although the barrier corresponding to the digital stream has arrived, the data 1, 2, and 3 after the barrier can only be placed in the buffer, waiting for the barrier of the letter stream to arrive;
- Once finally all input streams have received barrier n, the operator will send the pending output data in the buffer, and then send CheckPoint barrier n downstream
- There will also be a snapshot of itself; after that, the Operator will continue to process the records from all input streams, processing the records from the input buffer before processing the records from the stream.
What is barrier misalignment?
Checkpoint is to wait until all barriers are all reached before it is completed
- In Figure 2 above, when there are other input stream barriers that have not yet arrived, the data 1, 2, and 3 after the arrived barrier will be placed in the buffer, and can only be processed after the arrival of the barrier of other streams.
- Barrier misalignment means that when there are other streams of barriers that have not yet arrived, in order not to affect performance, you don't need to bother, and directly process the data after the barrier. After the barriers of all streams have arrived, you can checkpoint the Operator;
Why is barrier alignment necessary? Is it possible to misalign?
- Answer: The barrier must be aligned when Exactly Once, if the barrier is not aligned, it becomes At Least Once;
The purpose of CheckPoint is to save the snapshot. If it is not aligned, some data after the offset corresponding to chk-100 has been processed before the chk-100 snapshot. When the program resumes the task from chk-100, the offset corresponding to chk-100 Later data will be processed once, so there will be repeated consumption. It’s okay if you don’t understand, there are cases below to let you know.
case study
Combining the pv case, the previous case is simple, the topic of Kafka described has only 1 partition, here to describe the barrier alignment, so the topic has 2 partitions;
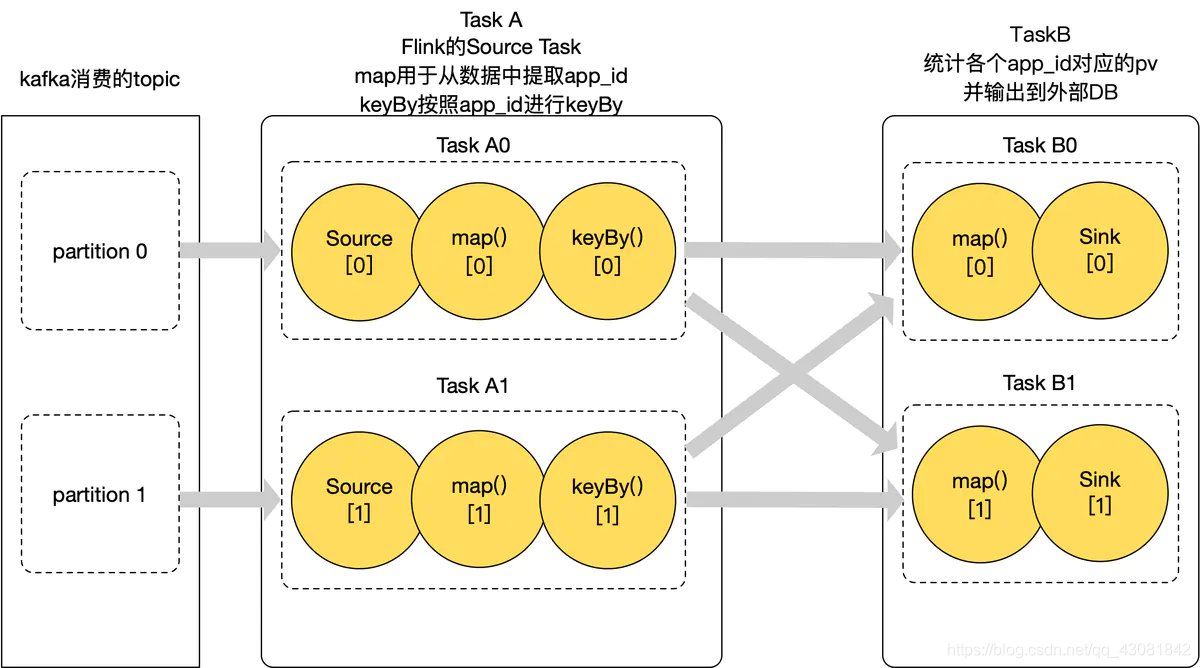
combined with the business, first introduce the functions of all the above operators in the business
- The Consumer of kafka of Source, reads data from kakfa to the map in TaskA in the flink application, and converts a kafka log read into the app_id we need to count
- keyBy performs keyBy according to app_id, and the same app_id will be assigned to the same instance of downstream TaskB
- TaskB's map finds the pv value corresponding to the app_id in the state, then +1, and stores it in the state. Use Sink to write the statistical pv value to the external storage medium;
- We consume data from the two partitions of Kafka, TaskA and TaskB have two parallel degrees, so there are a total of 4 Operator instances in flink, here we call them TaskA0, TaskA1, TaskB0, TaskB1;
Assuming that 99 CheckPoint has been successfully done, here is a detailed explanation of the 100th CheckPoint process;
- There is a timing schedule inside the JobManager. If the time for the 100th CheckPoint is now 10:00:00, the CheckPointCoordinator process of the JobManager will send CheckPointTrigger to all Source Tasks, that is, send CheckPointTrigger to TaskA0 and TaskA1.
- TaskA0 and TaskA1 receive CheckPointTrigger, they will insert a barrier into the data stream, send the barrier to the downstream, record the offset position of the barrier in their own state, and then take a snapshot of themselves and save the offset information to the back end of the state.
- Here, suppose the offset of partition0 consumed by TaskA0 is 10000, and the offset of partition1 consumed by TaskA1 is 10005. Then the state will save (0, 10000) (1, 10005), which means that the 0th partition consumes the offset 10000 position, and the 1st partition consumes the offset 10005 position;
- Then there is no state in the map and keyBy operators of TaskA, so there is no need to take a snapshot.
Then the data and barrier are sent to the downstream TaskB. The same app_id will be sent to the same TaskB instance. Here, suppose there are two apps: app0 and app1 After keyBy, suppose app0 is assigned to TaskB0, and app1 is assigned to TaskB1. Based on the above description, all app0 data in TaskA0 and TaskA1 are sent to TaskB0, and all app1 data is sent to TaskB1
Now let's assume that the barrier is aligned when TaskB0 is used for CheckPoint, and the barrier is not aligned when TaskB1 is used for CheckPoint. Of course, this configuration cannot be done. I will give you an example to analyze the impact of the barrier on the statistical results.
- The CheckPoint of chk-100 mentioned above, the offset position is (0, 10000) (1, 10005), TaskB0 uses barrier alignment, which means that TaskB0 will not process the data after the barrier, so TaskB0 is in the chk-100 snapshot At that time, the pv data of app0 saved in the state backend is the pv value calculated from all the data from the start of the program to the Kafka offset position (0, 10000) (1, 10005), one is not many (after the barrier is not processed, so Will not repeat), a lot (all the data before the barrier has been processed, so it will not be lost), if the saved state information is (app0, 8000), it means the consumption of (0, 10000) (1, 10005) offset At this time, the pv value of app0 is 8000
- The barrier used by TaskB1 is not aligned. If TaskA0 is due to other fluctuations such as the server's CPU or network, TaskA0 is slow to process data, and TaskA1 is very stable, so it processes data faster. The result is that TaskB1 first receives the barrier of TaskA1. Because the configured barrier is not aligned, TaskB1 will continue to process the data after the TaskA1 barrier. After 2 seconds, TaskB1 receives the barrier of TaskA0, so it checks the app1 stored in the state. Start the CheckPoint snapshot of the pv value, and the saved state information is (app1, 12050), but we know that this (app1, 12050) actually processes the data after the barrier sent by TaskA1 for 2 seconds, which is the corresponding kafka topic For the data after partition1 offset 10005, the real PV data of app1 must be less than 12050. Although the offset saved by partition1's offset is 10005, we may actually have processed the data of offset 10200, assuming that it is processed to 10200;
- Although the pv value of the state save is too high, it cannot explain the repeated processing, because my TaskA1 did not consume the data of the offset 10005~10200 of partition1 again, so there is no repeated consumption, but the displayed results are more real-time
At this point in the analysis, let's sort out what our state has saved:
chk-100:
- offset:(0,10000)(1,10005)
- pv:(app0,8000) (app1,12050)
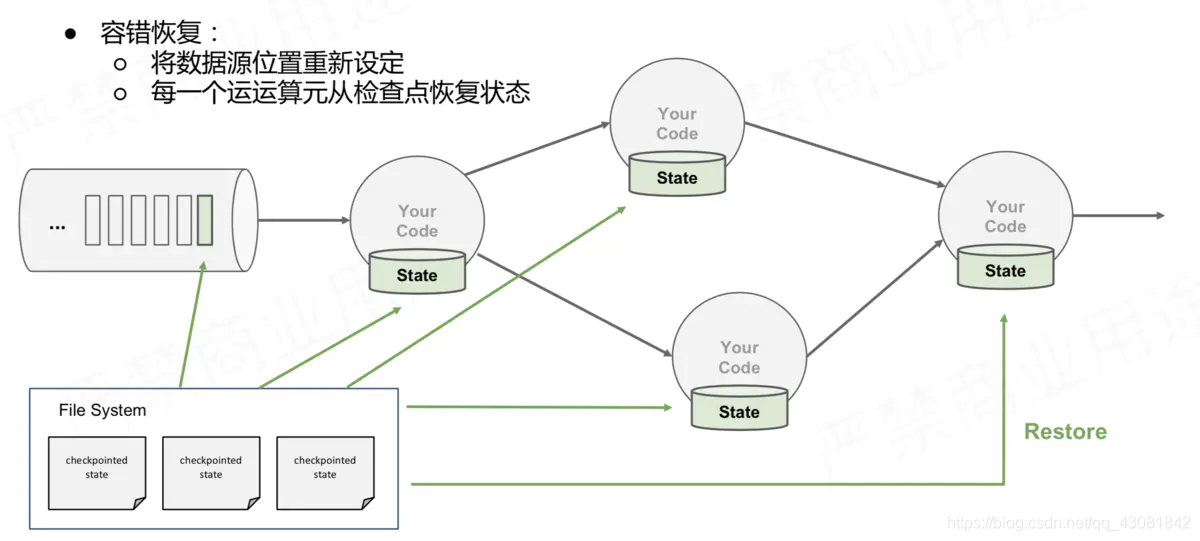
- Then the program continues to run. After 10 seconds, one of our four Operator instances is down due to a server hanging down, so Flink will resume from the last state, which is the chk- we just discussed in detail. 100 restorations, how did they recover?
- Flink will also set up four Operator instances. I also call them TaskA0, TaskA1, TaskB0, and TaskB1. The four Operators will read the saved state information from the state backend.
- Start consumption from offset: (0, 10000) (1, 10005), and accumulate statistics based on the value of pv: (app0, 8000) (app1, 12050), and then you should find that the pv value of app1 12050 is actually included The data of offset 10005~10200 of partition1, so when partition1 resumes the task from offset 10005, the data of offset 10005~10200 of partition1 is consumed twice
- The barrier set by TaskB1 is not aligned, so the state corresponding to CheckPoint chk-100 consumes more data after the barrier (sent by TaskA1). After restarting, it is restored from the offset saved in chk-100. This is what is called At Least Once
- Because the barrier set by TaskB0 is aligned above, there will be no repeated consumption of app0, because app0 does not consume offset: (0, 10000) (1, 10005) after the data, which is the so-called Exactly Once;
Seeing this, you should already know what kind of repeated consumption will occur, and you should also understand why barrier alignment is Exactly Once, and why barrier alignment is At Least Once.
When exactly will barrier alignment occur?
- First set the CheckPoint semantics of Flink: Exactly Once
- Operator instance must have multiple input streams to appear barrier alignment
FAQ
In the first scenario, when calculating PV, Kafka has only one partition. It makes no difference if it is accurate once, at least once?
- Answer: If there is only one partition, the source task parallelism of the corresponding flink task can only be 1. There is indeed no difference, there will not be at least one existence, it must be accurate once. Because it is possible to repeat processing only if the barrier is not aligned, the parallelism here is already 1, and the default is aligned. Only when there are multiple parallelism upstream, the barrier that multiple parallelism sent to the downstream needs to be aligned. The parallelism will not cause barrier misalignment, so it must be accurate once. In fact, it is still necessary to understand that barrier alignment means that Exactly Once will not be repeatedly consumed, and barrier misalignment means that At Least Once may be repeatedly consumed. Here, there is only a single degree of parallelism and there is no barrier misalignment, so there will be no at least once semantics;
In order to make CheckPoint downstream as soon as possible, the barrier will be sent to the downstream first, and then the snapshot will be synchronized by itself. In this step, what if the synchronization snapshot is slow after the barrier is sent down? The downstream has been synchronized, not yet?
- Answer: It may happen that the downstream snapshot is earlier than the upstream snapshot, but this does not affect the snapshot result, but the downstream snapshot is more timely. I only need to ensure that the downstream process all the data before the barrier and does not process the data after the barrier. Then take a snapshot, then the downstream also supports accurate one time. Don't think about this problem from the overall perspective. If you think about the upstream and downstream examples individually, you will find that the upstream and downstream status is accurate, and there is neither loss nor double counting. One thing to note here, if there is an Operator's CheckPoint that fails or the CheckPoint timeout will also cause the failure, then the JobManager will consider the entire CheckPoint to fail. The failed CheckPoint cannot be used to restore the task. All checkpoints of the operators must be successful, then the CheckPoint can be considered as successful this time and can be used to restore the task;
The CheckPoint semantics of Flink in my program is set Exactly Once, but the data is duplicated in my mysql? The CheckPoint is set once every 1 minute in the program, but the data is written to mysql every 5 seconds and commit;
- Answer: Flink requires that the end to end must implement TwoPhaseCommitSinkFunction exactly once. If your chk-100 is successful, after 30 seconds, because it commits once every 5 seconds, you have actually written 6 batches of data into mysql, but suddenly the program hangs and resumes from chk100. In this case, the previously submitted Six batches of data will be written repeatedly, so repeated consumption occurs. There are two cases for Flink's accuracy once. One is the accuracy inside Flink and the other is the end-to-end accuracy. This blog describes the accuracy of Flink internally. I will post another blog to introduce Flink in detail later. How to achieve end-to-end precision once