This article is used for summarizing records of my own learning process, if infringement, please inform us to delete
Paper summary
1. Research background
Traditional target positioning mainly uses sensors that have the shortcomings that the sensor itself is affected by other sensors carried by the machine and cannot identify the target object. The visual sensor experimental environment requires loose and low cost for research. Visual positioning methods can be divided into positioning based on monocular vision, positioning based on binocular vision and positioning based on omni-directional vision.
2. Research framework
1. Based on monocular vision
1.1 Based on monocular target positioning model,
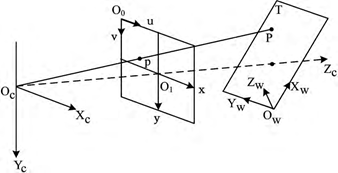
set a point in space P in camera coordinates The coordinates in the system are (Xc, Yc, Zc, 1)T, and the coordinates in the world coordinate system are (Xw, Yw, Zw, 1)T, then the relationship between the two is:
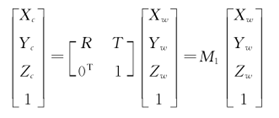
(X, y) are the image coordinates of point p, (Xc, Yc, cc) are the coordinates of the spatial point P in the camera coordinate system, and f is the camera focal length. Use the homogeneous coordinate relationship to express the above projection relationship:

the corresponding relationship between a point in the pixel coordinate system and a point in the world coordinate system is:
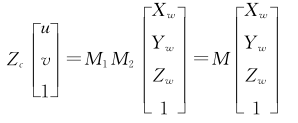
2. Based on binocular vision
Monocular vision has a small field of view, less depth information, and low positioning accuracy. Binocular vision has gradually become a research hotspot in the field of vision.
And how to select the images that have the same spatial location from the images collected by the left and right cameras The target point has always been the difficulty and key of binocular vision technology. The research on target positioning based on binocular vision is divided into binocular vision positioning methods based on feature points, binocular vision positioning methods based on regions, and dual vision based on features and regions. Visual positioning method.
2.1 Binocular vision positioning method based on feature points
| algorithm | advantage | Disadvantage |
|---|---|---|
| Harris | l High flexibility and strong stability | The matching effect is poor when the translation and rotation are changed. |
| SIFT | Good robustness when the translation and rotation are changed | High computational complexity and poor real-time performance |
| SURF | Better real-time |
2.2 Region-based binocular vision positioning method
Based on the region matching algorithm, the region-based stereo vision positioning method can obtain a dense and uniform image disparity map, and has a certain matching accuracy; however, it is effective for image rotation and external lighting. Changes are more sensitive and robust, and cannot handle similar texture areas or occlude image areas in the image. The area matching algorithm is to select a sub-window in the neighborhood of the pixel, and find the sub-image that is most similar to the sub-window image in an area in another image according to a certain similarity measurement algorithm, and the matched sub-image The corresponding pixel point in is the matching point of the pixel.
 2.3 The binocular vision positioning method based on feature and region combination.
2.3 The binocular vision positioning method based on feature and region combination.
Aiming at the advantages and disadvantages of the two algorithms of region matching and feature matching, complementary strategies are adopted to make full use of the compactness of the region matching disparity map and the robustness of the feature matching disparity map. Combining these algorithms, a binocular vision positioning method based on the combination of features and regions is proposed.
3. Positioning method based on omnidirectional vision
At present, omnidirectional vision sensors are mainly divided into two categories, one is the omnidirectional vision sensor composed of traditional vision sensors, and the other is the mirror-type omnidirectional vision sensor. The former omni-directional vision sensor needs to process a large amount of visual information, which requires a large amount of calculation and is difficult to achieve real-time performance. The mirror shape of the latter reflector will cause uneven distribution of the resolution of the omni-directional image and large distortion. In addition, the horizontal cross-section of the curved mirror is circular, which makes the omni-directional image also circular, which is difficult to process directly. . However, its computational complexity is small and does not need to solve the image fusion problem of the former omnidirectional vision sensor, so it is widely used in target detection and visual tracking.