java multithreading
Threads and processes
The process is the basic unit of the system for resource scheduling and allocation, and the foundation of the operating system. Thread is the smallest unit of system scheduling and the computing unit of the process. A process may contain one or more threads.
Thread life cycle
There are six life cycles of threads: new, ready & running, blocking, waiting, timing waiting, and destroying
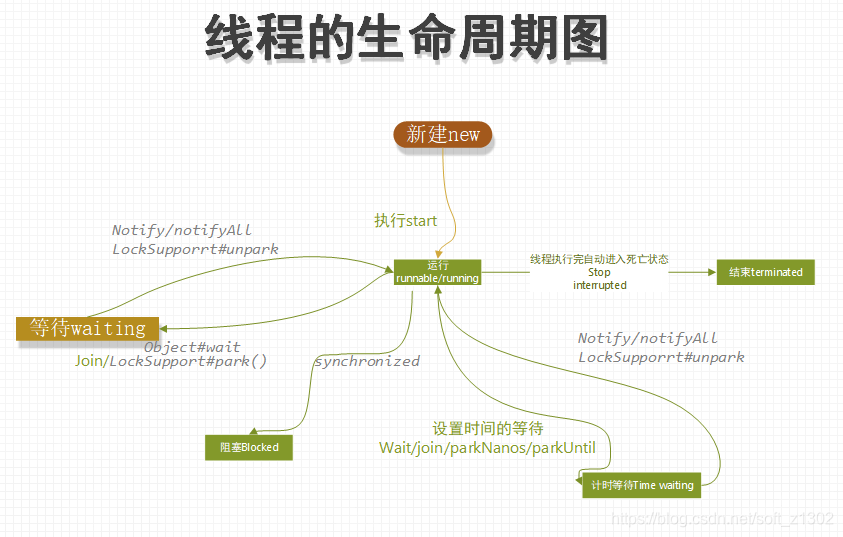
New
There are several ways to create threads: Thread class creation, implementation of Runnable interface, Callable and Future creation
# 1、thread
new Thread() {
@Override
public void run() {
}
}.start();
# runnable
public class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println("runnable thread");
}
public static void main(String[] args){
Thread t = new Thread(new RunnableThread());
t.start();
}
}
# Callable&Future
public class CallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("Callable Thread return value");
return 0;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> future = new FutureTask<Integer>(new CallableThread());
new Thread(future).start();
System.out.println(future.get());
}
}
In fact, if you look at it carefully, it is finally implemented in Runnable. Let's interpret part of the source code of Thread together:
1. Why does the thread have the six states described above? This is the java.lang defined by the thread Thread object. .Thread.State enumeration properties
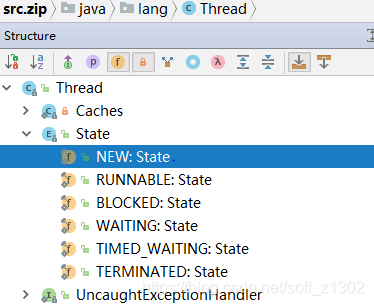
The meaning and implementation of each state are clearly described in English. In fact, when I was a beginner in threading, I still had some questions. Why use threads and the difference between the start and run methods of executing threads? Next, I will interpret the source code flow with my senses:
线程初始化方法:
/**
* Initializes a Thread.
*
* @param g 线程组,是维护线程树的对象,所有线程必须具备的属性要素,这里可以判断线程是否具有相应的权限,以及是否合法,线程状态,是否守护线程等;目标是维护一组线程和线程组,同时我们要注意的线程之前的通讯是局限于线程组,是一组线程中维护的线程**
* @param target 运行线程的对象,线程执行时拿到的run或者call方法的目标对象
* @param name 当前线程名称
* @param stackSize 新建线程时栈大小,当为0时可忽略
*
* @param acc 上下文权限控制
*/
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
// ………… 省略部分代码
/*获取安全管理策略,主要用来检查权限相关因素,若权限不满足时,抛出异常SecurityException,启动时是通过jvm参数设置[java.security.manager],具体可查看 [java API](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/lang/SecurityManager.html)*/
SecurityManager security = System.getSecurityManager();
if (g == null) { // 当java.security.manager不设置时,这里为空
// 若需要安全管理策略,直接取得线程组
if (security != null) {
g = security.getThreadGroup();
}
// 不存在父级树寻找
if (g == null) {
g = parent.getThreadGroup();
}
}
// 检查权限
g.checkAccess();
/*
* 检测是否能被实力构造和重写
*/
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
// 以便垃圾回收,增加未启动线程数
g.addUnstarted();
// 设置是否守护线程,线程优先级,安全控制,执行目标,堆栈长度以及线程id等
………… 省略部分代码
}
Next, I will explain the difference between the direct execution of run and the start method. The execution of run is the current thread execution method body of the existing JVM. Executing start is to allocate resources to the process where the jvm is located, and create a stack frame space to create a new execution unit. Allocate the stack frame space and so on, call the run method of Thread in the current stack frame space, and then run calls the run method of the incoming target (if you are interested, you can interpret the start0 method of open jdk).
# Thread#run
@Override
public void run() {
if (target != null) {
target.run(); // runnable
}
}
Runable&Runnging
When we execute start after creating a new thread, we enter the ready state Runnable. When the run method is called inside the thread, it enters the running stage Running, but directly executing the run method does not start the thread. The specific verification is as follows.
public class RunStartThread extends Thread {
public RunStartThread(String name) {
super(name);
}
@Override
public void run() {
System.out.println(System.currentTimeMillis());
try {
sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
RunStartThread rst = new RunStartThread("runThread");
rst.run(); // 主线程运行run方法
rst.start(); // 启动子线程运行run
}
}
Run the run method of the above code to grab the thread dump as shown below. We observe that the thread name is " main ".
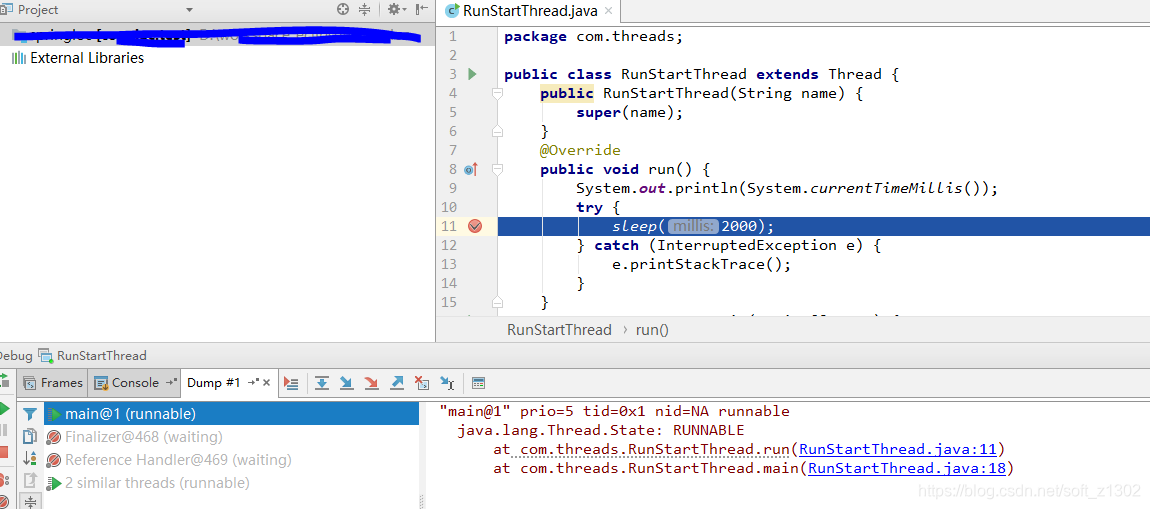
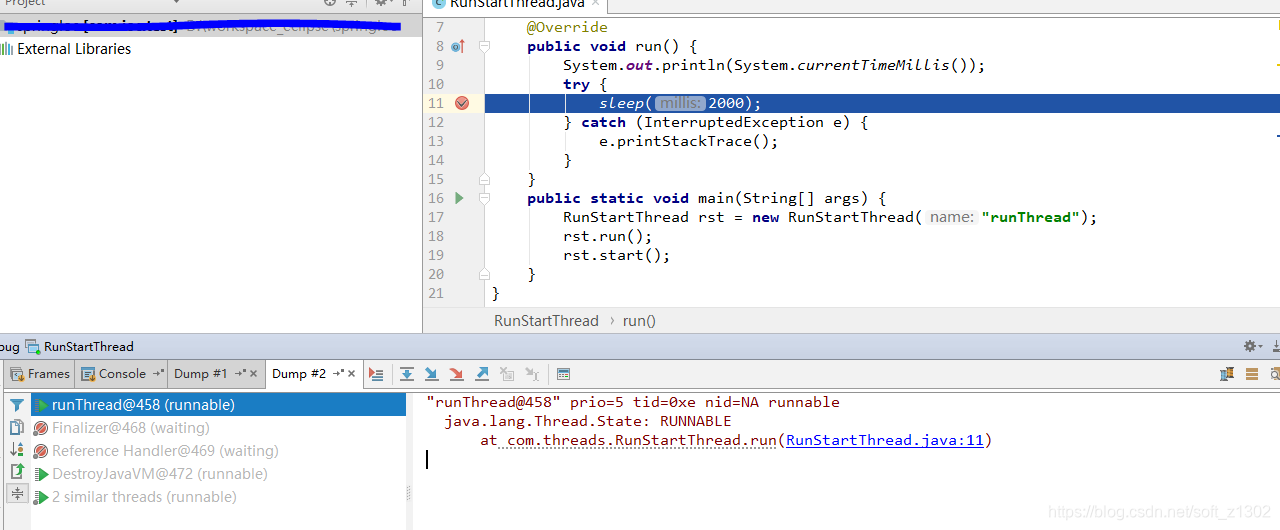
When we run the start method, when we grab the dump again, we find that the currently running thread name is my custom thread name runThread. In addition, we found that start does not directly call runnable's run, but calls start0 in the local stack to let jvm handle thread scheduling.
Blocked
When a thread enters the blocked state, it usually automatically waits and then enters the running state or directly dies. Generally, the block is synchronized, as shown in the following code example. Therefore, we mainly try not to use synchronized during development. The reason is that the automatic release of the key is uncontrollable. Single-threaded operation, the same object cannot run at the same time, if you really need to control thread safety programming, try to use Lock:
public class BlockThreads {
public static void main(String[] args) throws InterruptedException {
TestThread th = new TestThread();
th.runThread(th,"Thread1");
th.runThread(th,"Thread2");
th.runThread(th,"Thread3");
System.out.println("111");
}
private static class TestThread {
public synchronized void sayHello() throws InterruptedException {
System.out.println(System.currentTimeMillis());
Thread.sleep(3000);
}
public void runThread(TestThread th, String threadName) {
new Thread(threadName) {
@Override
public void run() {
try {
th.sayHello();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
}
}
}
Waiting
The methods that cause the thread to wait include Object#wait (Object#notify or Object#notifyAll recovery), Thread#join, and LockSupport#park (LockSupport#unpark), which causes the CPU to release resources while in the waiting state.
Time waiting
Object#wait(time), LockSupport#parkNanos, and LockSupport#parkUntil waiting time. In fact, we use the concept of Time waiting in many scenarios, such as nginx tuning, thread destruction time tuning, and request concurrency timeout setting. Effective setting of the timeout period is beneficial to increase the throughput of the system
Terminated
Thread destruction includes automatic destruction and manual destruction. Automatic destruction means that after the thread executes the run method, the JVM will destroy the thread. Manual destruction can be destroyed using the Thread#stop method, but this method has been abandoned because it is a violent method, and the internal JVM may be The monitoring information cannot be monitored either. The Thread#interrrupted method performs destruction judgment. If it cannot be destroyed, an InterruptedException will occur.
Thread pool concept and multi-thread usage scenarios
A thread is an execution unit, and a thread pool is a collective composed of a group of execution units, which is a way of using threads. The thread pool is used to maintain the mechanism of starting, taking, and scheduling threads. In the multi-core CPU and multi-task scheduling, we can use the thread pool to handle multi-threading, increase the use of the CPU while controlling the high pressure of the CPU, improve performance and avoid blocking. For example, SMS sending, http request, timed task, asynchronous call, etc.
Parameter analysis of thread pool
The thread creation object that comes with JDK is ThreadPoolExecutor. There are several parameters in the object: core thread number, maximum number of threads, thread survival time, thread factory, and thread rejection strategy. The following source code
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
Several specific meanings have a simple text introduction: the number of core threads corePoolSize is the number of running threads. When the number of threads at the same time is greater than the number of core threads, the threads enter the waiting queue workQueue. When the waiting queue exceeds the waiting queue, there will be a new non-core thread (maximumPoolSize -corePoolSize) is executed. When the number of threads is greater than maximumPoolSize+workQueue#size, a rejection strategy will occur. The specific rejection strategy will be discussed later. The technical team of Tumei Group quoted from the technical team of Meituan
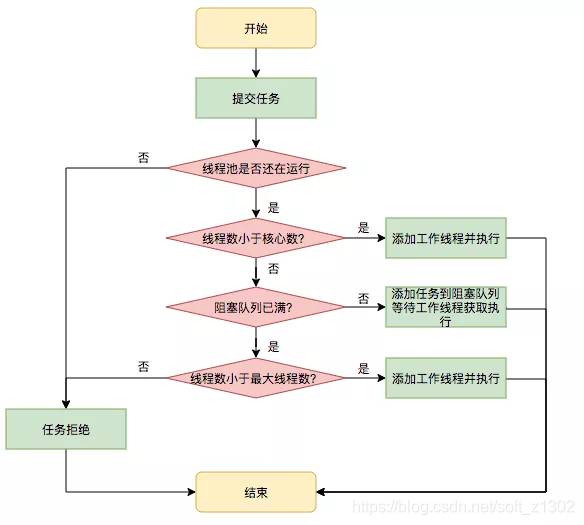
Thread pool blocking queue BlockingQueue
The common waiting queues that come with JDK are LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue (in addition, it is mentioned that the length of the queue can be changed dynamically, for example, the capacity of LinkedBlockingQueue is set to volatile)
- LinkedBlockingQueue is a linked list node storage, FIFO model, and of course the linked list type storage is unlimited. Generally, when this is set, the maximum number of threads is basically invalid, because the length will never exceed, unless an OOM exception occurs, it is recommended under the condition of high concurrency with a large number of waiting threads Use this blocking queue.
- ArrayBlockingQueue specifies the length of the waiting queue. This point is to set the data queue more accurately to realize the waiting queue.
- SynchronousQueue has no cache waiting queue, and the queue is always 0. This operation is generally an unbounded operation and makes full use of the CPU usage. For example, Executors#newCachedThreadPool is implemented in the second method.
Thread pool factory ThreadFactory
Commonly used open source project thread pool factories include CustomizableThreadFactory, ThreadFactoryBuilder, BasicThreadFactory. The factory method mainly sets thread priority and thread name and other thread attributes. I won't explain it in detail here. The main simple practical examples are as follows:
ublic class ThreadFactoryTest implements ThreadFactory {
private final AtomicInteger threadCount = new AtomicInteger(0);
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>(), new ThreadFactoryTest());
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
}
/**
* @param r 传入的线程
**/
@Override
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setPriority(2);
th.setName("设置线程名前缀" + this.threadCount.incrementAndGet());
return th;
}
}
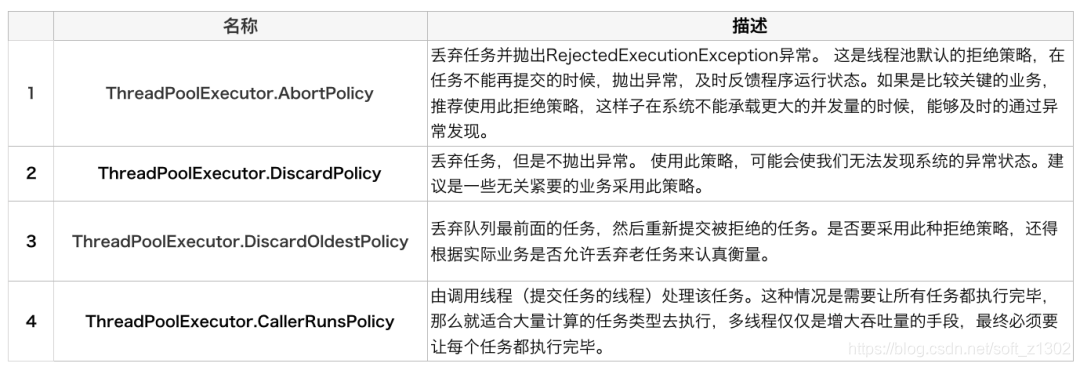
Thread pool rejection strategy RejectedExecutionHandler
Common JDK rejection policies AbortPolicy abort policy, execute run when CallerRunsPolicy exceeds, discard when DiscardPolicy exceeds, and DiscardOldestPolicy discards the last one in the queue.
Several implementation methods of JDK Executors thread pool
Executors are tools (generally they are tools after s, such as Arrays, Systems, Collections, Objects, etc.), nonsense, Executors create threads with newFixedThreadPool, newCachedThreadPool (ThreadPoolExecutor main source code analysis) , newScheduledThreadPool, newSingleThreadExecutor, newSingleThreadScheduled .
Simple analysis of creation type
newCachedThreadPool
newCachedThreadPool provides two construction methods to achieve, one is to construct Executors#newCachedThreadPool(); without parameters, and the other to construct Executors#newCachedThreadPool(ThreadFactory threadFactory) with parameters.
Advantages: The number of core threads is set to 0, which means that when the CPU is idle, threads enter immediately Enter the execution state, the waiting queue is an unbounded synchronous waiting queue SynchronousQueue, which is fully utilized in the case of multiple CPUs. In fact, combining the above two factors shows that the maximum thread number setting is equivalent to invalid, so make full use of the characteristics of multi-core CPUs.
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Disadvantages: high concurrency causes the CPU to occupy 100%, other thread tasks cannot be processed, and the long-term high pressure of the CPU will heat up and cause high temperatures. Our system recommends that the CPU usage should not exceed 80%, and the normal usage should not exceed 60%. Let's introduce two of the execution methods and additional source code analysis
newFixedThreadPool (additional source code analysis)
Executors#newFixedThreadPool fixed-size thread pool, that is, set the number of core threads to be the same as the maximum number of threads. The waiting queue is an unbounded linear waiting queue. An advantage here is to make full use of thread reuse. As for why, of course, it is to interpret the source code testimony:
AbstractExecutorService#submit method creates the task FutureTask and calls ThreadPoolExecutor#execute:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null); // 新建future任务
execute(ftask);
return ftask;
}
Next, we will focus on analyzing the execution method in ThreadPoolExecutor#executor, which is divided into three steps ( a point mentioned here, the number of threads and the state are passed through the 32-bit CTL of AtomicInteger, the high three bits are state preservation, and the low 29 is the maximum number of thread pools ):
int c = ctl.get();/* 获取主线程状态控制29位变量 */
if (workerCountOf(c) < corePoolSize) { /* 前29位作为统计线程数,判断worker是否大于核心线程数 */
if (addWorker(command, true)) /* 添加worker工作线程,若新建成功则执行线程,并返回true */
return;
c = ctl.get(); /* 再次检测当前线程地位29 */
}
if (isRunning(c) && workQueue.offer(command)) { // worker无法获取和创建,插入等待队列
int recheck = ctl.get(); // 再次检测线程池worker大小
if (! isRunning(recheck) && remove(command)) // 若线程池不可运行状态,且移除当前线程成功,则拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0) // 若当前没有线程worker,即核心线程为0,则立即执行队列
addWorker(null, false);
}
else if (!addWorker(command, false)) // 队列已经满了,则直接添加非核心线程并运行
reject(command); // 运行或者创建非核心线程失败,则拒绝策略
From the above analysis, it can be seen that the state of the thread pool is saved in the upper three bits, and the lower 29 bits save the number of running threads.
Next, focus on worker and task
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
// ……………… 省略部分代码
for (;;) {
// ……………… 省略部分代码
// 这里判断最大worker数,查看是核心线程还是最大线程,若超出范围直接返回创建worker失败
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c)) // 创建worker前检测后并增加运行线程数
break retry;
}
}
// …………
Worker w = null;
try {
// 新建worker,同时调用ThreadFactory的newThread进而线程池的参数,比如参数名称等
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock; // 获取线程池锁
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 判断是否有效范围内
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 创建worker成功后直接调用线程的start方法执行线程,并且返回成功,调用worker启动后将会执行run方法。
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
After code analysis, workers are ultimately responsible for scheduling tasks. When the number of threads is greater than the number of core threads, the thread passed in by the worker is empty, and the tasks to be executed are placed in the workQueue of the queue ( ie new Worker->start worker -> runWork -> getTask -> runTask ), the truth lies in our runWorker method as follows. There is a " submission priority concept ", the core thread task is executed first!= null and then getTask() is executed, which means that the thread with the queue overflow is actually executed first. Because the above code execute explains the overflow queue directly addworker directly has priority over the addition of the queue.
/*
worker启动时,委托给主线程的runWorker
*/
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
// ………省略部分代码
// 获取当前任务,当时非核心时且添加进队列时为null,需要从队列中获取
Runnable task = w.firstTask;
// …………
/* 当任务为空,且队列也不为空是,不执行 */
while (task != null || (task = getTask()) != null) {
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null; //这个地方非常关键,执行完后队列中查找。
w.completedTasks++;
w.unlock();
}
}
Thread pool parameter setting scheme
The two factors we generally consider are CPU and IO. The general parameter settings are for CPU-intensive and IO-intensive, but it must be analyzed in combination with actual business scenarios, such as business time-consuming, tps and other factors to allocate core threads reasonably It’s best to dynamically set the parameters (JDK supports dynamic adjustment of the number of core threads, the maximum number of threads and the length of the waiting queue, combined with the dynamic update of the apollo configuration center, such as the Meituan technical team ).
CPU-intensive , The number of core threads is set to the effective number of CPUs +1, and the maximum number of threads is set to 2×the effective number of CPUs +1, which may cause some suspended animation.
The IO-intensive type means that the number of core threads is 2 × the effective number of CPUs , and the maximum number of threads is 25 × the effective number of CPUs , as follows
Dynamically set parameters
Dynamically setting the size of the thread pool is conducive to handling peak issues and tuning thread pool data. The method adopted is ThreadPoolExecutor#setCorePoolSize to dynamically set the number of core threads. InterruptIdleWorkers can clear idle workers in order to occupy resources, as shown in the following code:
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize; // 设置的核心线程数和原来的差值
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize) // 工作worker是否大于设置的核心线程数,如果大于则当worker空余时清空。
interruptIdleWorkers(); // 这方法其实很重要,我们可以用来设置回收没有使用的核心线程数,
else if (delta > 0) { // 若设置线程数大于原有线程数,则看队列是否有等待线程,如果有则直接循环创建worker并执行task任务,知道worker大于最大线程数或者队列已空
// We don't really know how many new threads are "needed".
// As a heuristic, prestart enough new workers (up to new
// core size) to handle the current number of tasks in
// queue, but stop if queue becomes empty while doing so.
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
Summary & reflection
1. addWorker(Runnable firstTask, boolean core) Create a new worker. When the parameter firstTask of this method is empty, the function of preheating is similar to spring lazy loading.
2. setCorePoolSize dynamically sets the number of core threads
3. setMaximumPoolSize dynamically sets the maximum number of threads
4, CPU-intensive and IO-intensive
5, runWorker worker execution tasks
6, interruptIdleWorkers destroy idle core threads
7, Executors create thread methods newFixedThreadPool, newCachedThreadPool, newScheduledThreadPool, newSingleThreadExecutor
8, execute and submit execution priority and submission priority, and two The difference is that there are return values and so on.
9. Several ways to create threads: Thread, runnable, Callable, and future, and the status of the threads, the use of JVM stack debugging
10. Common blocking threads LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue
11. Common thread factories CustomizableThreadFactory, ThreadFactoryBuilder, BasicThreadFactory and purpose
12. Several common implementation classes of RejectedExceptionHandler AbortPolicy, CallerRunsPolicy, DiscardPolicy, DiscardOldestPolicy
13. How to dynamically set the number of core threads and the maximum number of threads and the blocking queue
14. What is the meaning of ThreadGroup and securityManager?
15. Follow-up addition..................
Spring boot uses thread pool
The production here is simple and practical, and the detailed use must be combined with the actual scene:
@SpringBootTest
@EnableAsync
class PoolApplicationTests {
@Autowired
private PoolService poolService;
@Test
void contextLoads() {
poolService.say1();
poolService.say2();
}
}
@Service
public class PoolService {
@Value("${spring.pool.core.size:5}")
private int coreSize;
@Value("${spring.pool.max.size:10}")
private int maxNumSize;
/**
* 自定义线程池
*
* @return
*/
@Bean("executor")
public Executor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(coreSize);
executor.setMaxPoolSize(maxNumSize);
executor.setQueueCapacity(20);
executor.initialize();
return executor;
}
/**
* 在目标线程池执行任务
*/
@Async(value = "executor")
public void say1() {
System.out.println(Thread.currentThread().getName());
}
@Async(value = "executor")
public void say2() {
System.out.println(Thread.currentThread().getName());
}
}
Reference
[1] JDK 1.8 source code
[2] Meituan technical team (partial picture quotes and knowledge points)
[3] Thread and process Baidu Encyclopedia