The text and pictures in this article are from the Internet and are for learning and communication purposes only. They do not have any commercial use. If you have any questions, please contact us for processing.
The following article is from Code Zhuji, author Liu Yaxi
Python crawler, data analysis, website development and other case tutorial videos are free to watch online
https://www.xin3721.com/eschool/pythonxin3721/
Presumably most of the friends have already hated Baidu search's advertising recommendation mechanism, but even if it involves a little commercial content search, the results of the vb.net tutorials
are almost all advertisements. In fact, in addition to Google search, there is also a niche search engine, the effect is not much worse than Baidu, the key is that there are almost no ads in the search results, he is Microsoft's son, Bing Search.
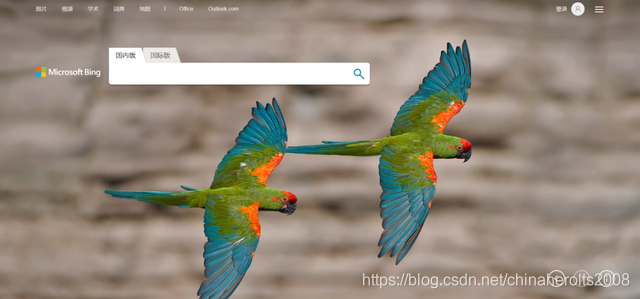
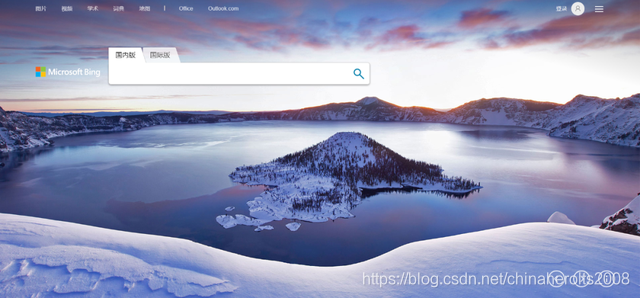
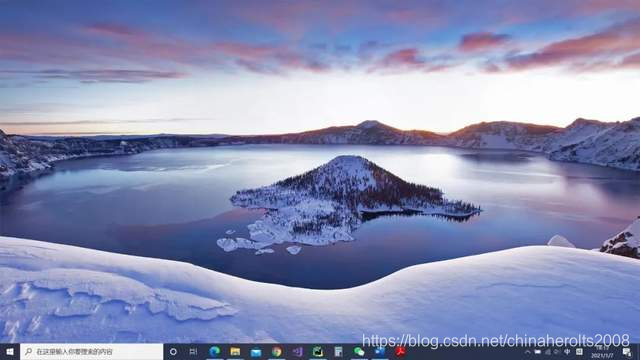
Every time we open Bing search, we will see a beautiful background image, and it is updated every day. Before, Microsoft also provided the download address of each picture, but it was cancelled later. But if we can get these background pictures and set them as computer wallpapers in c# tutorial , wouldn’t it be a very interesting thing, then how can we get these photos? Today I will teach you to write a Python script to capture the necessary The background image that should be searched.
First, we install the IDE, here I choose the most popular Python PyCharm, you can download it on the official website:
https://www.jetbrains.com/pycharm/download/#section=windows
The installation method is very simple, just go to the next step.
After the installation is complete, open the IDE, we create a Python project
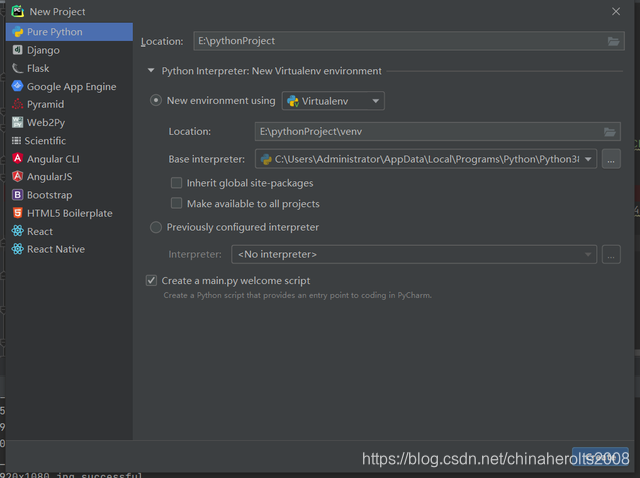
After completion, we need to install several libraries in advance for us to write code later, namely:
request
BeautifulSoup4
lxml
Installation is simple, we click on the upper left corner of the compiler python based tutorial in File-> Settings dialog box:

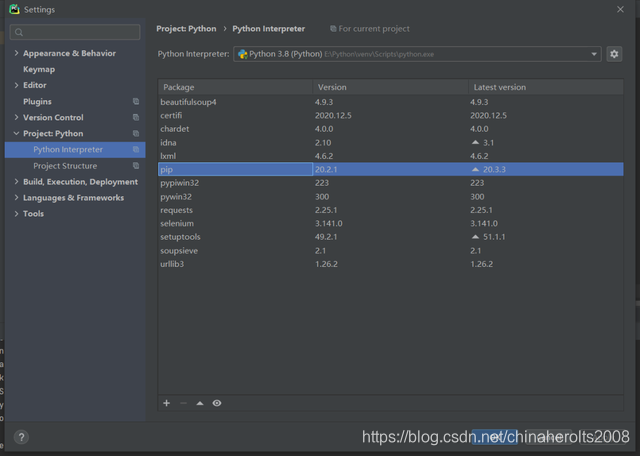
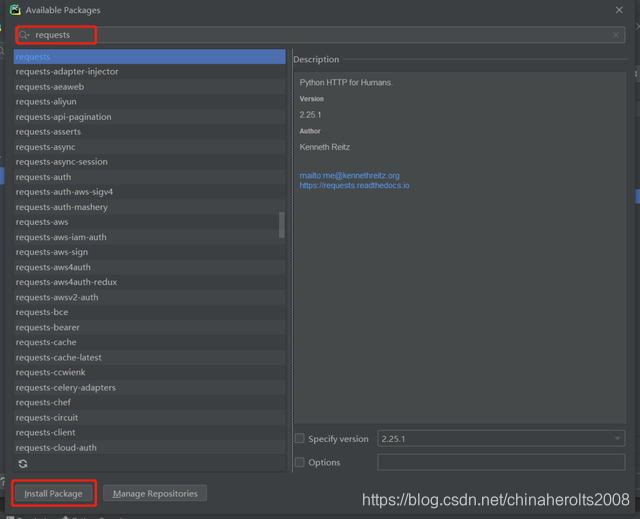
We double-click pip in the above figure, search for the three library names listed above in the pop-up dialog box, and then click InstallPackage in the lower left corner to complete the installation:
After finishing, we start to write code:
First, we introduce four package codes we need:
if __name__=='__main__':
for i in range(8):
url = 'https://cn.bing.com/HPImageArchive.aspx?idx={}&n=1'.format(i)
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
text = soup.find(name='url').string
img_url = 'https://cn.bing.com' + text
img_name = re.match('^/th\?id=(.*?)&', text).group(1)
download(img_url, '填你自己想保存的文件路径c:/..', img_name)
Then we define a get_page function to get the content of the web page requested by the request, but in order to pretend to be a browser to visit, we need to change the User-Agent field here:
def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200: #响应状态码表示服务器对请求的响应结果。200代表服务器响应成功,403代表禁止访问,404代表页面未找到
return response.text
Let's define a function download to download pictures. The parameters passed in include the url path of the picture, the folder path you defined yourself, and the name of the picture:
def download(url, path, fname):
response = requests.get(url)
if response:
with open(os.path.join(path, fname), 'wb') as f:
f.write(response.content)
print('successful: {} .'.format(fname))
else:
print('faild: {}.'.format(fname))
Okay, after the above two main functions are defined, we will define the main function to call them constantly. Note that the path of the download function should be filled in with your own folder path. Since Bing officially saves only eight original images, we simply and rudely loop only 8 times. The code is as follows:
if __name__=='__main__':
for i in range(8):
url = 'https://cn.bing.com/HPImageArchive.aspx?idx={}&n=1'.format(i)
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
text = soup.find(name='url').string
img_url = 'https://cn.bing.com' + text
img_name = re.match('^/th\?id=(.*?)&', text).group(1)
download(img_url, '填你自己想保存的文件路径c:/..', img_name)
Well, the above is the complete code content, let's try to run it once:
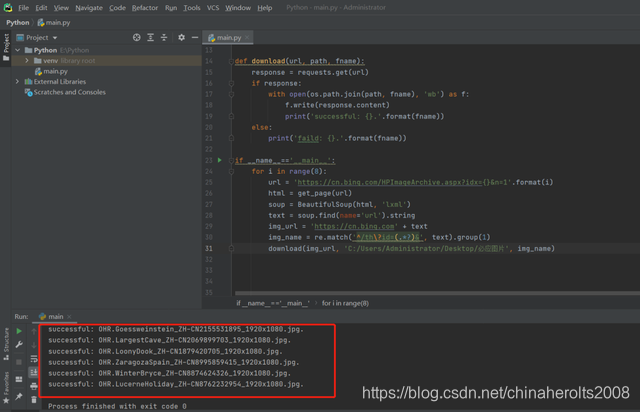
The result is no problem at all. The pictures in the folder are also saved:

Open one at will, it is very beautiful:

Have you found that the picture is very beautiful? Just find one and set it as a computer desktop to see the effect: