Write in front
We finished reading the data last week ( Python data analysis actual combat: getting data ), the next step is to clean the data, first of all, the processing of missing values. Missing values are null values, find them first before processing.
View missing values
You can use the isnull method to view the null value, and the result is a Boolean value.
# 查看缺失值
df_list.isnull()
result:
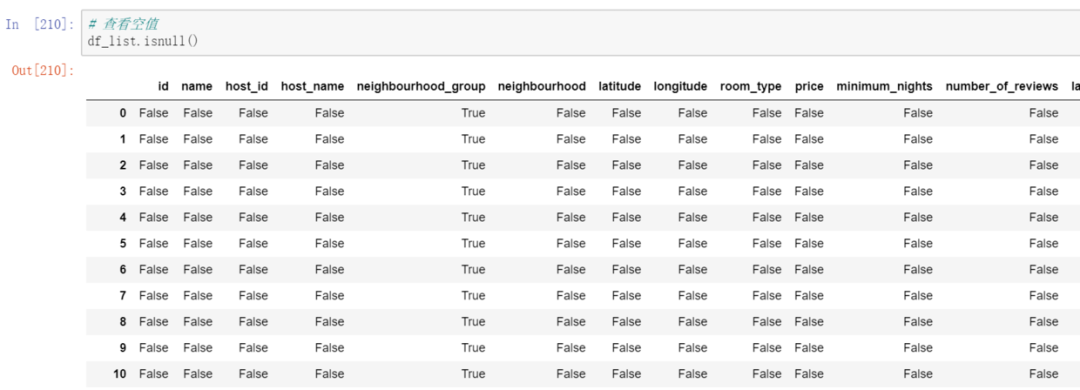
For a small data set, you can look like this, but for a large data set, it doesn’t seem to make much sense to look at the null value. It’s okay. There are other methods, you can use the info method.
# 查看空值
df_list.info()
result:
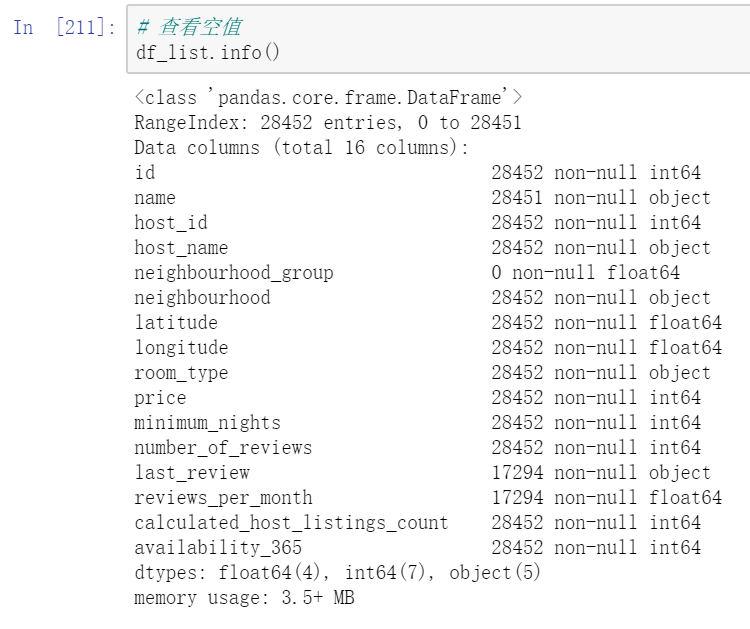
The info method can see the data type of the field and how many non-null values are under each field. You can see that the neighborhood_group field is all empty, which is consistent with the result displayed by the Boolean value.
In fact, there is another method, which is simpler:
# 查看空值
df_list.isnull().sum()
Summing the boolean values of isnull, it is obvious that the id column has no null value, and the name column has a null value. The result:
You can also view the null value for a single column, and view the null value for the name column
# 对单独一列查看空值
df_list["name"].isnull().sum()
The result is 1, indicating that the name column has a null value:
Treatment of missing values
What to do after finding the missing value? Delete or fill.
Remove missing values
Using the dropna method, the default is to delete all rows as long as there is a missing value in a row
# 删除缺失值
df_list.dropna()
The result is that all the data in this data set is deleted, because the neighborhood_group field is all empty. According to dropna's urine, if one is empty, the entire row will be deleted, and the following result is obtained:
Of course, you can also pass in the how="all" parameter to this method , and delete it only when the entire row is empty.
# 整行都为空才删除
df_list.dropna(how = "all")
The result is that none of them are deleted, because there is no record in this data set with all fields empty:
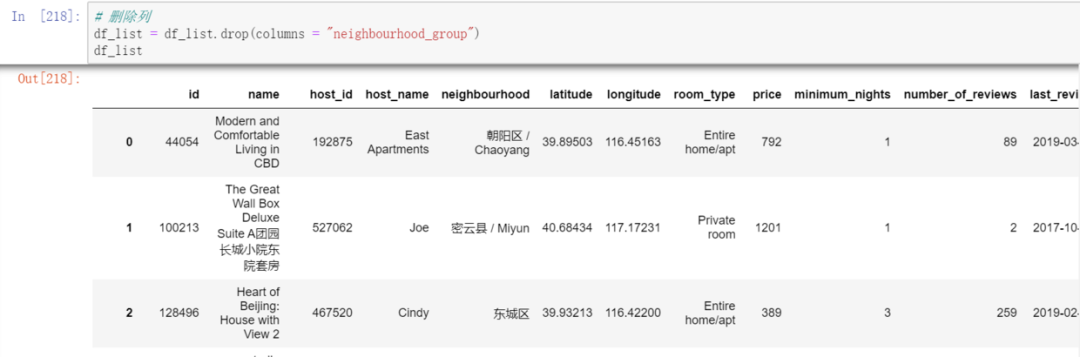
But there is a column with empty data, delete the column neighborhood_group, do you remember how to delete the column?
# 删除列
df_list = df_list.drop(columns = "neighbourhood_group")
df_list
result:
The name column also has a null value, find out and take a look
# 定位到name列的空值
df_list[df_list["name"].isnull()]
The results are as follows, this line should be deleted.

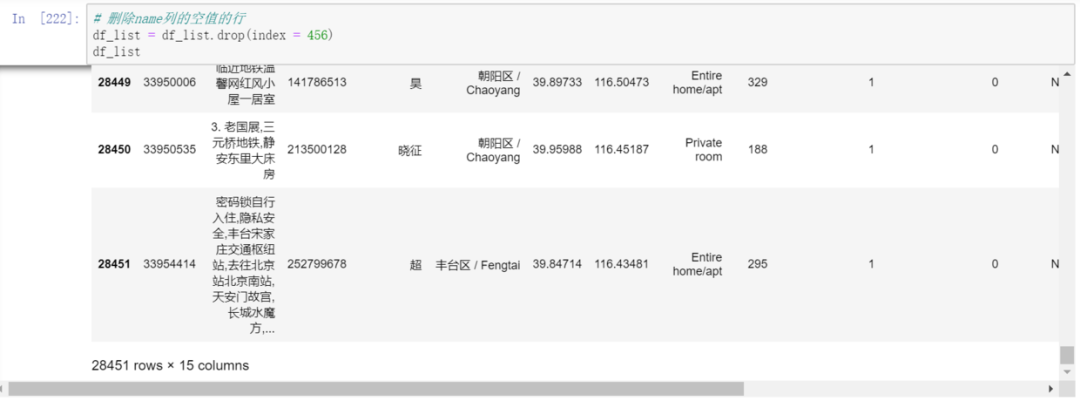
Use the drop method to delete rows. Just locate the row to be deleted. The row index is 456
# 删除name列的空值的行
df_list = df_list.drop(index = 456)
df_list
As a result, you can see that it has become 28451 lines, which has been 28452 lines before.
Missing value fill
Of course, in addition to deleting missing values, you can also fill in, you can fill in with 0, or you can fill in with the mean and mode. Use fillna method to fill missing values.
The last_review and reviews_per_month columns also have missing values. We use the mode to fill in the missing values in the last_review column, and use the mean to fill in the missing values in the reviews_per_month column.
# 缺失值填充
df_list.fillna({"last_review":df_list.last_review.mode(),
"reviews_per_month":df_list.reviews_per_month.mean()})
result

Here is just an example. Missing values can also be filled in this way. In this case, it is not recommended to fill in the two columns. Leave them empty. The next section deals with duplicate values and outliers.