Usually used in judgment sentences to check whether a string meets a certain format
A regular expression is a common character and metacharacters composition
Common characters include uppercase and lowercase letters, numbers, punctuation marks and some other symbols
Metacharacters refer to special characters with special meaning in regular expressions. They can be used to specify the appearance mode of its leading character (that is, the character before the metacharacter) in the target object
Basic regular expression common metacharacters
Supported tools: grep, egrep, sed, awk
Common metacharacters
Explanation
\
Escape characters, used to cancel the meaning of special symbols, for example: \!, \n, \$, etc.
^
The starting position of the matching string, for example: ^a, ^the, ^#, ^[az]
$
End of the string matching position, for example: Word Katex the parse error: After the Expected Group '^' position AT 2:, ^ matches the null line
.
Match any one character except \n, for example: go.d, g...d
*
Match the preceding sub-expression 0 or more times, for example: goo*d, go.*d
[list]
Match a character in the list, for example: go [ola]d, [abc], [az], [a-z0-9], [0-9] match any digit
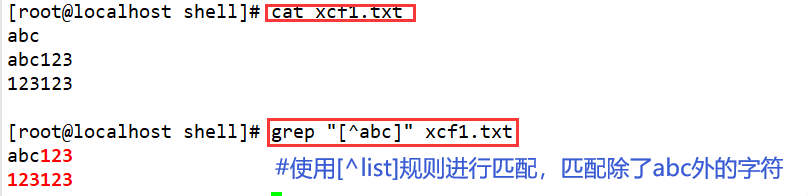
[^list]
Match any non-list character-for example: [^0-9], [^A-20-9], [^az], match any non-lowercase letter
{n}
Example: go{2}d,'[0-9]{2}' matches two digits' matches two digits
{n,}
Match the preceding sub-expression no less than n times, for example: go{2,)d,'[0-9]{2,}, match two or more digits
{n,m}
Match the preceding sub-expression n to m times, for example: go{2,3}d,'[0-9]{2,3} matches two to three digits
note
Egrep, awk use {n}, {n,}, {n,m} when matching, without adding "\" before "{}"
Extended regular expression metacharacters
Supported tools: egerp, awk
Metacharacter
Explanation
+
Match the previous sub-expression more than once, for example: go+d, will match at least one o, such as god, good, goood, etc.
?
Match the previous sub-expression 0 or 1 times, for example: go?d, will match gd or god
()
The string in the brackets as a whole, for example: g(oo) +d, will match. Overall more than 1 time, such as good, gooood, etc.
|
Match the string of words in an or manner, for example: g(oo|la)d, will match good or glad