Preface
Recently, I am working on a crawler project, crawling Weibo comments, the project has been tested, and now I will briefly summarize.
Project structure
Because of the company's architecture system, Python cannot directly connect to redis. You need to write a Java project to connect to the database. So the whole project contains 6 parts: python (crawler), python (cookie generator), python (sentiment analysis, the library used by snownlp), java (server: used to connect es, redis, mysql), java (show Terminal, used to display comments, statistical display, etc.), java (backstage management, configuration of accounts, keywords, URLs, etc.)
reptile
There are three difficulties in crawling Weibo:
- When logging in, the website has a lot of anti-picking strategies, such as entering a verification code, etc. The verification code tool we use is Cloud Code
- Crawling data is divided into full crawling and incremental crawling. When an exception is encountered during the crawling process, how to restore to the state before the exception occurred
- For the communication problem with java, we chose nio at first, but later decided to switch to http because we are more familiar with this protocol and the code looks clearer and easier to understand
1. Login : In the first version, we wrote the login and the crawler together. After login, a cookie will be generated, and the cookie will be saved locally. The cookie will be used next time to log in. If it fails, log in from the login page again, and The account information is written in the project configuration file, it is not easy to modify, and the same account is used every time, which is easy to be identified by Weibo
Optimization plan : Java maintains a cookie pool. For ease of understanding, I drew a schematic diagram of the cookie pool
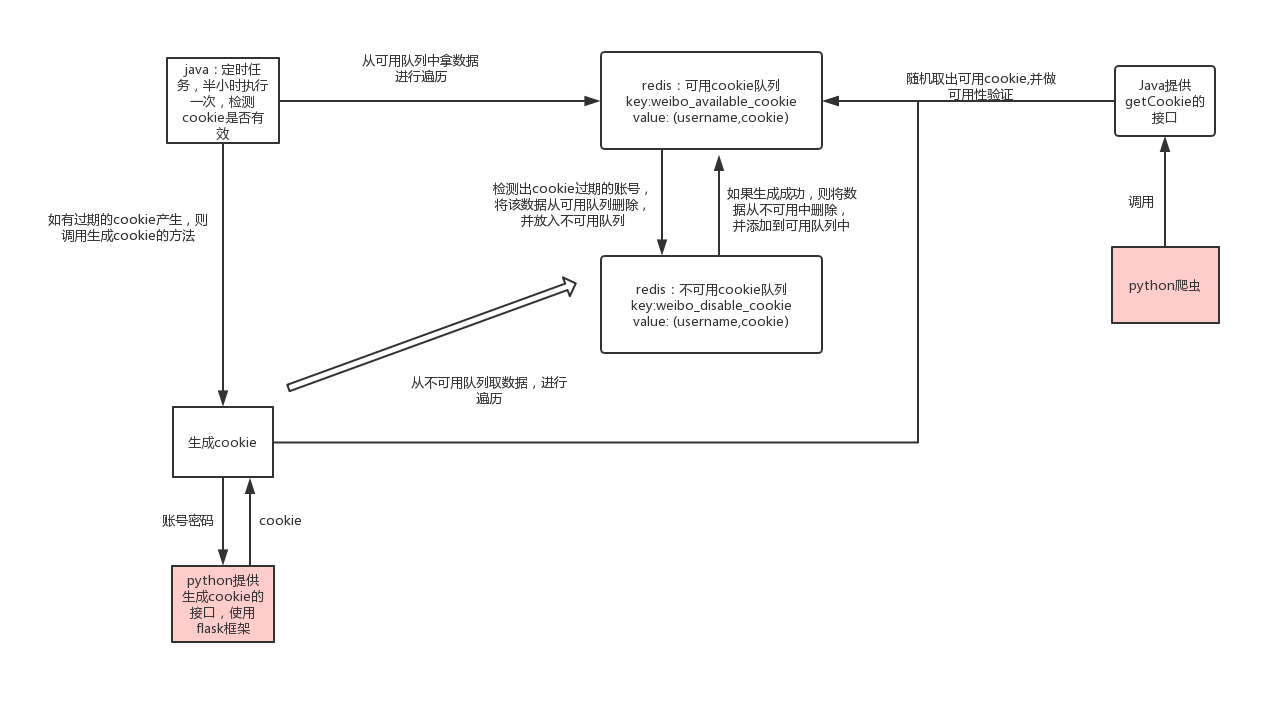
The general idea is this, some of the small details, such as how often the test is performed, and the time between each account generation, need to be adjusted according to how many accounts there are
In this way, we split the function of logging into this part from the original crawler, and the function of the crawler is more unique.
Second, the crawler status record problem, store the number of pages of each keyword in the database, in the crawling process, first traverse the keyword, and then obtain the page number of the keyword from the database, and start crawling from this page If there is an exception, update the keywords in the library and record the number of pages where the exception occurred, so that each time even if the exception exits, it can be restored to the previous state.
The crawl frequency I set is to crawl all keywords every half an hour, but it is incremental crawling, only the data of the first two pages is crawled; all keywords are crawled in the evening
There is another issue that needs attention in the crawling process, that is, how to update Weibo comments. The strategy we think is that when crawling a topic for the first time, store the key information such as the topic id and url in mysql, and then if you download If you climb to this Weibo again, skip it. The task of updating the comment is another crawler doing it. This crawler will take out topic data from mysql and traverse. If the number of comments changes, then crawl the comments, if there is no change, skip
to sum up
This article briefly introduces the design ideas of the public opinion system. The specific code involves some information of the company and is not convenient to post, but there are many open source codes on github, you can refer to