1. What is Elasticsearch
Elasticsearch is a distributed, open source search and analysis engine based on Lucene . It provides a full-text search engine with distributed multi-user capabilities, based on RESTful WEB interface. Elasticsearch is developed in Java and released as an open source under the terms of the Apache license. It is a popular enterprise search engine!
2. Docker install Elasticsearch
You can use the following command to quickly start Elasticsearch for development or testing:
1. Pull the mirror
docker pull elasticsearch:6.4.0
2. Run the setup container
docker run --name es -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d elasticsearch:6.4.0
# -d 表示在后台运行
# 也可以设置ES_JAVA_OPTS内存使用限制
3. Check if it is running
docker ps

You can see there is already
Then let's test whether we can connect to the input { server IP }: 9200 The above message appears, indicating success
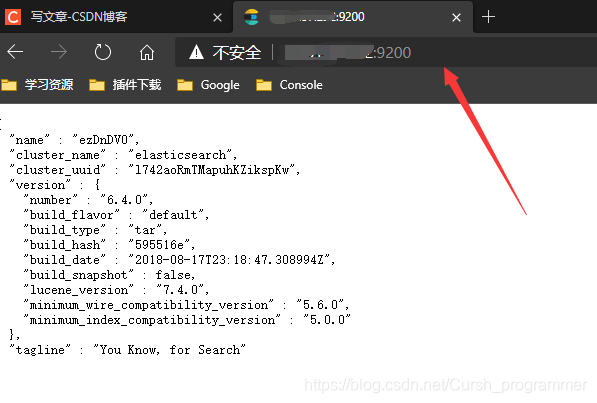
3. Docker installs the IK tokenizer
1. Enter the container
docker exec -it es /bin/bash
2. Download and install online
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
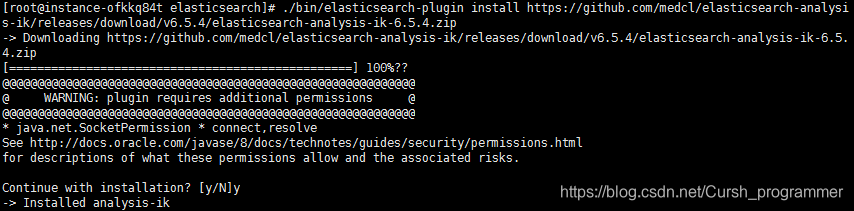
3. Enter the plugins folder to see the IK tokenizer
Ik is a Chinese word segmentation plugin. The Chinese word segmentation that comes with elasticSearch is very unprofessional, and ik supports Chinese word segmentation better.

4. Install the visualization plugin Kibana
It is recommended to use the same version of mirror 6.4.0 as elasticsearch (different may cause problems)
1. Download Kibana mirror
docker pull kibana:6.4.0
2. Edit the kibana.yml configuration file
The kibana.yml configuration file is placed in the **/data/elk/** directory of the host, and the content is as follows:
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://(你的服务器IP):9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
3. Kibana
docker run –name kibana -p 5601:5601 -v /data/elk/kibana.yml:/usr/share/kibana/config/kibana.yml --restart=always -d kibana:6.4.0
4. View the container startup status
docker ps

5. Dynamic kibana
Visit http://{server's IP}:5601 (startup may be slow, if it fails, wait a few seconds and then try to refresh)
5. ES use (basic query, aggregate query
1. Create an index library
The ES index library is a logical concept, which includes a word segmentation list and a document list. The same type of documents are stored in the same index library. It is equivalent to a table in MySQL, or equivalent to a collection in Mongodb.
About the term
index : Index (noun): ES is a search service based on Lucene, which searches for eligible index data from an index library.
Index (verb): The index library is empty when it is just created. The process of adding data to the index library is called indexing.
Two methods of creating an index library are introduced below. They work on the same principle, and both are the client sending commands to the ES service.
1) Use tools like postman or curl to create:
put http://localhost:9200/index library name
{
"settings":{
"index":{
"number_of_shards":1,
"number_of_replicas":0
}
}
}
number_of_shards: Set the number of shards. Usually multiple shards are set in the cluster, which means that an index library will be split into multiple shards to store different nodes, which improves the processing capacity and high availability of ES. The entry program uses a stand-alone environment , Here is set to 1.
number_of_replicas: Set the number of replicas. The setting of replicas is to improve the high reliability of ES, and the stand-alone environment is set to 0. The
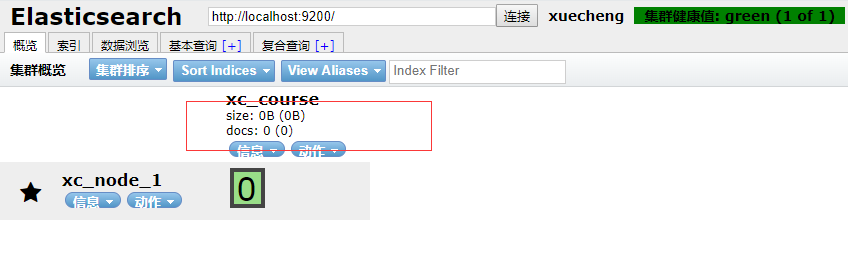
following is an example of creation, creating the xc_course index library, a total of 1 shard, 0 replicas:
-
Created with the head plugin
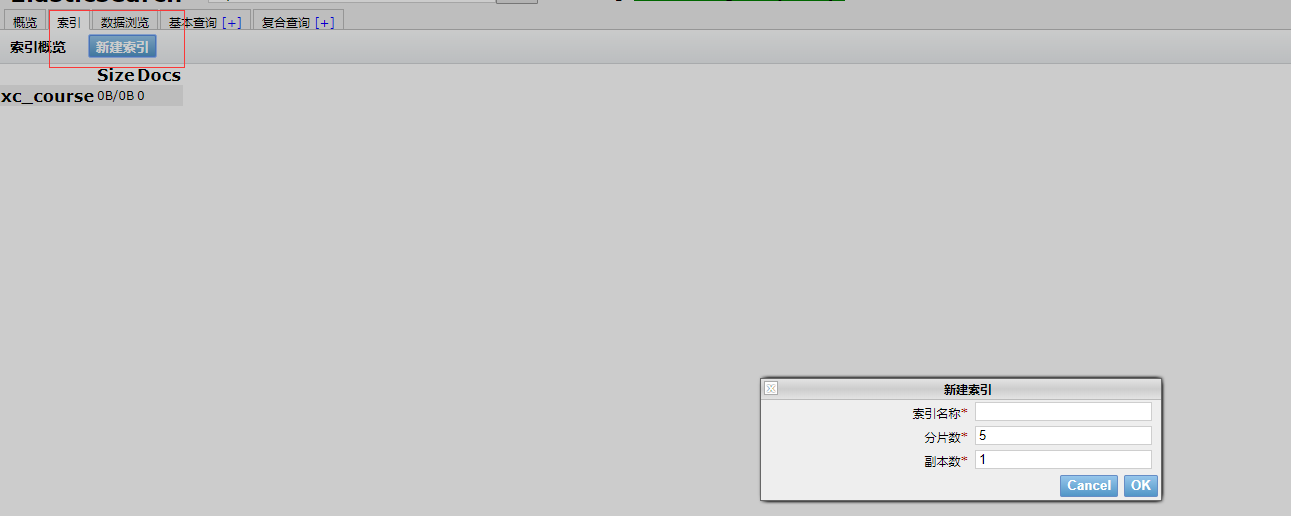
2 Create a mapping
2.1 Concept description
Each document in the index includes one or more fields. Creating a mapping is the process of creating a field in the index library. The following is an analogy between the concept of document and field and relational database:
Document (Document)----------------Row record
Field (Field)-------------------Columns
Note: 6.0 The previous version has the concept of type. Type is equivalent to a relational database table. ES officials will completely delete type in the ES9.0 version.
The index library mentioned above is equivalent to a database or a table in a relational database?
1. If it is equivalent to a database, it means that an index library can create many different types of documents, which is also allowed in ES.
2. If it is equivalent to a table, it means that an index library can only store documents of the same type. ES officially recommends that only documents of the same type be stored in an index library.
2.2 Create a mapping
We want to store the information in ES. Here we create the mapping of the information. First, let's start with a simple mapping, as follows:
send: post http://localhost:9200/index library name/type name/_mapping to
create a mapping of type xc_course , Including three fields: name, description, studymondel.
Because the ES6.0 version has not completely deleted the type, so the type has no special meaning for the time being.
Post request: http://localhost:9200/xc_course/doc/_mapping
means: create a mapping under the doc type under the xc_course index library. doc is the type name, which can be customized. In ES6.0, the concept of type should be weakened and give it a name with no specific business meaning.
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
The mapping is created successfully, check the head interface:
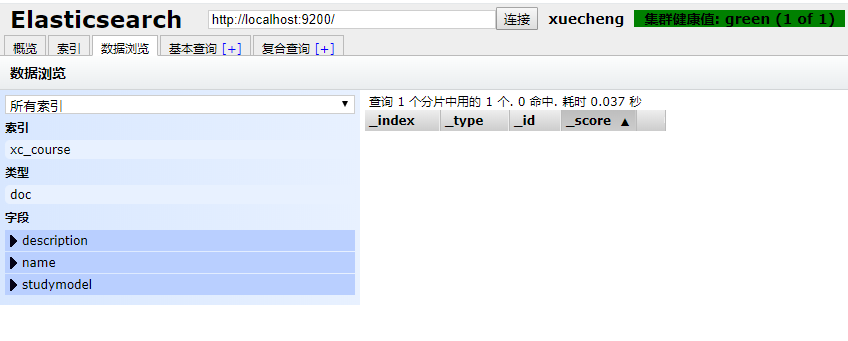
image.png
3. Create a document
Documents in ES are equivalent to records in MySQL database tables.
Send: put or Post http://localhost:9200/xc_course/doc/id value
(If you do not specify the id value, ES will automatically generate the ID)
http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
{
"name":"Bootstrap开发框架",
"description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"studymodel":"201001"
}
Use postman to test:
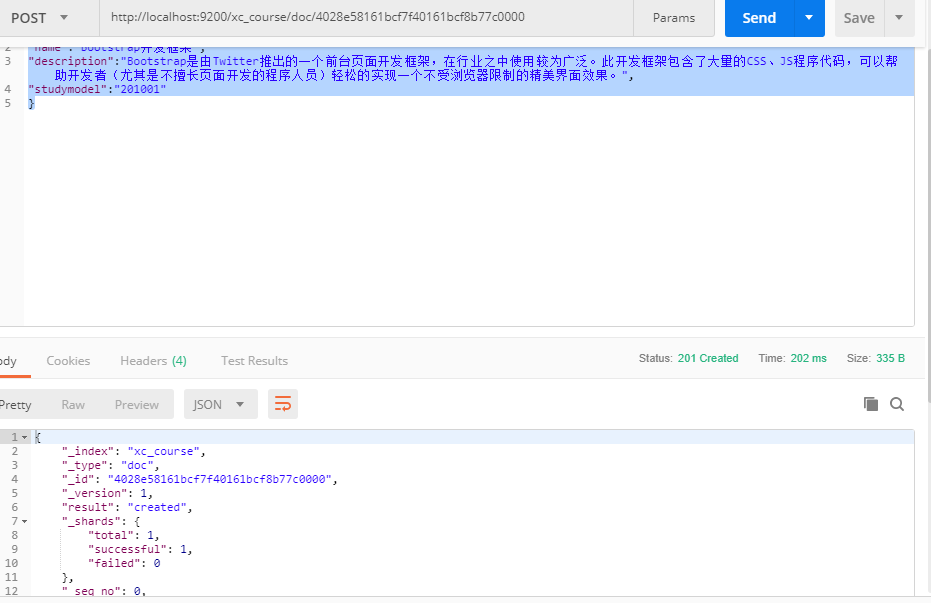
Query data through head:

4 Search for documents
1. Query the document according to the course id
Send: get http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
Use postman to test:
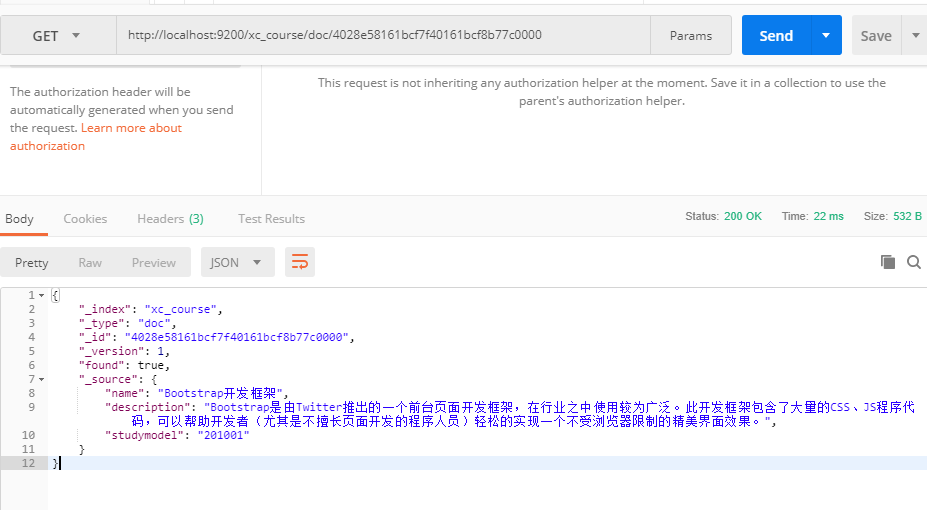
2. Query all records and
send get http://localhost:9200/xc_course/doc/_search
3. Query the records that include spring keyword in their name and
send: get http://localhost:9200/xc_course/doc/_search?q =name:bootstrap
4. Query the record whose learning mode is 201001 and
send get http://localhost:9200/xc_course/doc/_search?q=studymodel:201001
4.1 Analysis of query results
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "xc_course",
"_type": "doc",
"_id": "4028e58161bcf7f40161bcf8b77c0000",
"_score": 1,
"_source": {
"name": "Bootstrap开发框架",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"studymodel": "201001"
}
}
]
}
}
took: The time spent in this operation, in milliseconds.
timed_out: Whether the request has timed out
_shards: Indicate which shards were searched for this operation
hits: The record hits in the search
hits.total: The total number of documents that meet the conditions hits.hits: The first N documents with higher matching degree
hits.max_score: Document Match score, here is the highest score
_score: Each document has a matching score, sorted in descending order.
_source: shows the original content of the document.
5 Mapping type
1. Mapping maintenance method
1. Query the mapping of all indexes:
GET: http://localhost:9200/_mapping
2. Create a mapping
post request: http://localhost:9200/xc_course/doc/_mapping
An example:
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
3. Update the mapping.
New fields can be added after the mapping is created successfully, and the existing fields cannot be updated.
4. Delete the mapping Delete the mapping
by deleting the index.
2. Common mapping types
2.1 text text field
String includes two types: text and keyword:
1. text
1) The analyzer
specifies the tokenizer through the analyzer attribute.
The field type of the name specified below is text, and the ik_max_word word segmentation mode of the ik tokenizer is used.
"name": {
"type": "text",
"analyzer":"ik_max_word"
}
The analyzer specified above means that ik_max_word is used in both indexing and search. If you want to define the word segmenter used in search separately, you can use the search_analyzer attribute.
The suggestion for ik tokenizer is to use ik_max_word for fine-grained word segmentation of search content when indexing, and use ik_smart for search to improve search accuracy
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}
2) index
specifies whether to index through the index attribute.
The default is index=true, that is, to be indexed, and only indexing can be searched from the index library.
However, there are some contents that do not need to be indexed. For example, the product picture address is only used to display pictures and not search pictures. In this case, index can be set
to false.
Delete the index, re-create the mapping, set the index of the pic to false, and try to search based on the pic, but no data is found
pic": {
"type": "text",
"index":false
}
3)
Whether the store is stored outside the source. After each document is indexed, a copy of the original document will be saved in the "_source". Generally, there is no need to set store to true because there is already a copy in _source The original document.
2.2 keyword field
The text field introduced above requires a word segmenter when mapping. The keyword field is a keyword field. Generally, the search keyword is based on the overall search. Therefore, when creating the index of the keyword field, word segmentation is not performed, such as: zip code, mobile phone number, ID card etc. The keyword field is usually used for filtering, sorting, aggregation, etc.
2.3 date date type
There is no need to set a tokenizer for the date type.
Usually date type fields are used for sorting.
1)
Format sets the date format through format.
Example: The
following settings allow the date field to store three formats: year, month, day, hour, minute, second, year, month, day, and millisecond.
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
}
}
}
2.4 Numerical type
Below are the numerical types supported by ES.
1. Try to choose a type with a small range to improve search efficiency.
2. For floating-point numbers, try to use a scale factor, such as a price field with a unit of yuan. We will set the scale factor to 100. This will be in ES Stored by points, the mapping is as follows:
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
Since the scale factor is 100, if the price we enter is 23.45, the ES will multiply 23.45 by 100 and store it in ES.
If the entered price is 23.456, ES will multiply 23.456 by 100 and then take a number close to the original value to get 2346.
The advantage of using a scale factor is that integer types are easier to compress than floating point types, saving disk space.