Following the previous article, I will take you to brush the binary tree (Phase 1) and brush the binary tree (Phase 2) . This article will continue to brush the binary tree.
Judging from the reading volume of the first two articles, everyone can still learn frame thinking through the binary tree . However, many readers still have some questions, such as how to judge whether we should use the pre-order, middle-order or post-order traversal framework ?
So this article will focus on this problem, not to be too greedy, I will break it apart and just talk about one topic. Still the same sentence, according to the meaning of the question, think about what a binary tree node needs to do, and what traversal order is used will be clear .
Look at the question, this is the 652nd question "Find duplicate subtrees":

The function signature is as follows:
List<TreeNode> findDuplicateSubtrees(TreeNode root);
Let me briefly explain the topic. The input is the root node of a binary tree, rootand the return is a list containing several binary tree nodes. The subtrees corresponding to these nodes are duplicated in the original binary tree.
It's more convoluted. For example, enter the following binary tree:
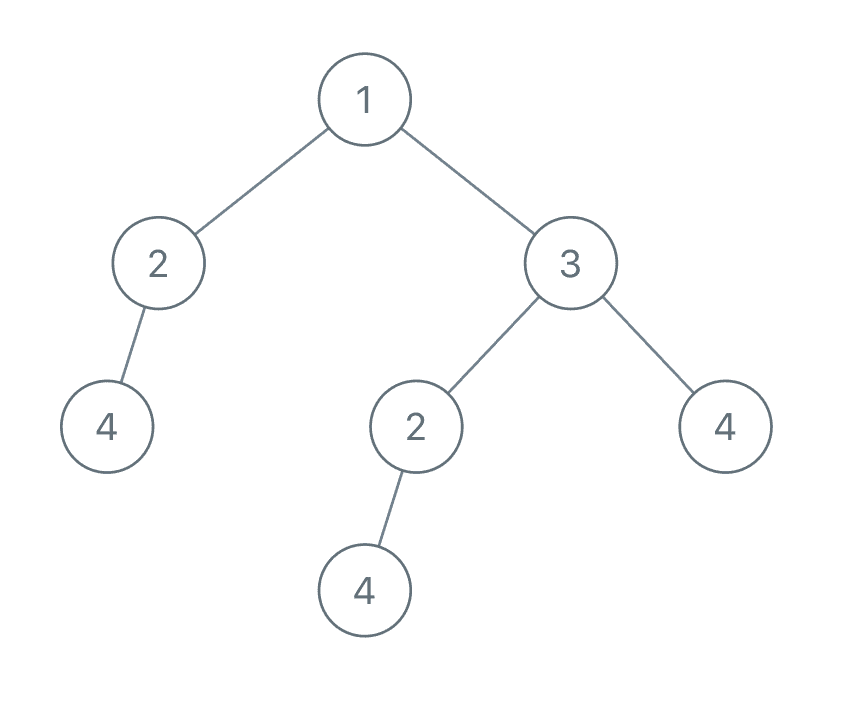
First, node 4 itself can be used as a subtree, and there are multiple nodes 4 in the binary tree:
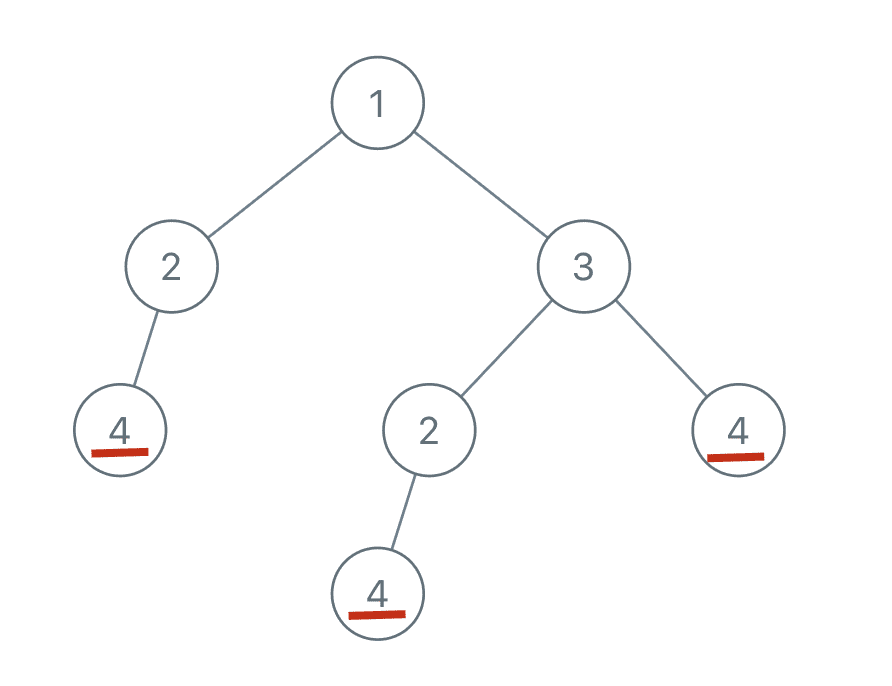
Similarly, there are two repeated subtrees rooted at 2:
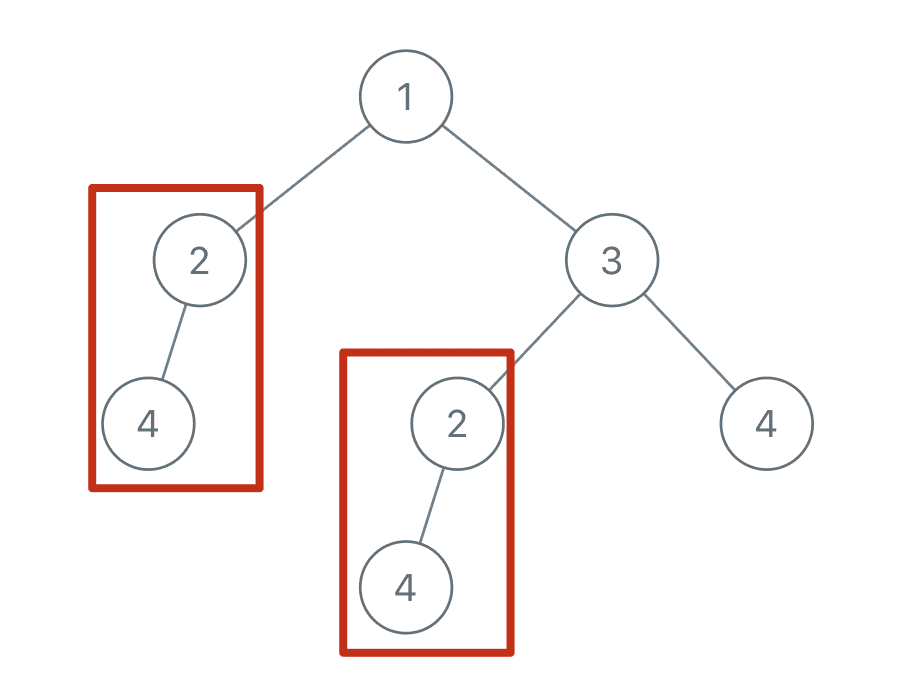
Then, List there should be two of the returned ones TreeNode, the values are 4 and 2 respectively (it doesn't matter which node it is).
PS: I have written more than 100 original articles carefully , and I have hand-in-hand brushed with 200 buckle questions, all of which are published in labuladong's algorithm cheat sheet , which is continuously updated . It is recommended to collect, brush the questions in the order of my articles , master various algorithm routines, and then cast them into the sea of questions.
How to do this question? It's still an old routine, first think about what it should do for a certain node .
For example, if you stand on this node 2 in the graph:
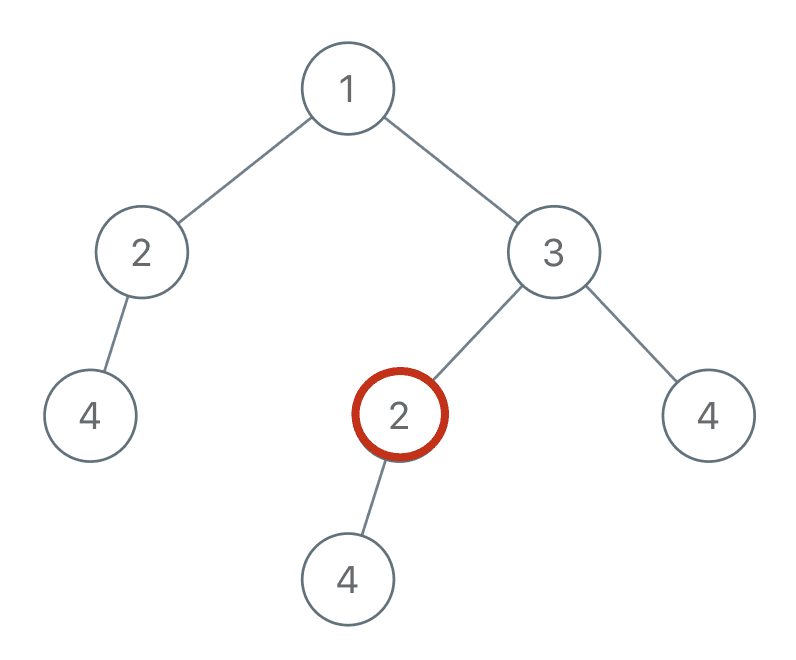
If you want to know if the subtree rooted at you is a duplicate and should be added to the result list, what information do you need to know?
You need to know the following two things :
1. What does this binary tree (subtree) with me as the root look like ?
2. What does the subtree rooted at other nodes look like ?
This is called knowing myself and the enemy. I have to know what I look like and what others look like before I know if anyone repeats it with me, right?
Okay, let's look at them one by one, and think first, how can I know what a binary tree rooted at myself looks like ?
In fact, seeing this problem, you can judge that this problem should be solved using the "post-order traversal" framework:
void traverse(TreeNode root) {
traverse(root.left);
traverse(root.right);
/* The location of the solution code */
}
why? It's very simple. I want to know what the subtrees rooted at me look like. Do I have to know what my left and right subtrees look like, and add myself to form the whole subtree?
If you still can't get around, let me give a very simple example: calculate how many nodes a binary tree has. This code should be written:
int count(TreeNode root) {
if (root == null) {
return 0;
}
// First calculate how many nodes there are in the left and right subtrees
int left = count(root.left);
int right = count(root.right);
/* Post-order traversal code position */
// Add yourself to the number of nodes in the entire binary tree
int res = left + right + 1;
return res;
}
Isn't this the standard post-order traversal framework? It is essentially the same as ours, right?
Now that it is clear to use post-order traversal, how should we describe the appearance of a binary tree? We have actually written about the serialization and deserialization of binary trees in the previous article . The pre/middle/post traversal results of the binary tree can describe the structure of the binary tree.
Therefore, we can serialize the binary tree by concatenating strings. Look at the code:
String traverse(TreeNode root) {
// For an empty node, it can be represented by a special character
if (root == null) {
return "#";
}
// Serialize the left and right subtrees into strings
String left = traverse(root.left);
String right = traverse(root.right);
/* Post-order traversal code position */
// Add yourself to the left and right subtrees, which is the result of binary tree serialization with itself as the root
String subTree = left + "," + right + "," + root.val;
return subTree;
}
We use non-digital special characters to # represent the null pointer, and use characters to , separate each binary tree node value, which belongs to the routine of serializing a binary tree, not much to say.
Note that we subTree are splicing strings in the order of left subtree, right subtree, and root node, which is the post-order traversal order. You can completely concatenate strings in the pre-order or middle-order order, because here is just to describe what a binary tree looks like, the order is not important.
PS: I have written more than 100 original articles carefully , and I have hand-in-hand brushed with 200 buckle questions, all of which are published in labuladong's algorithm cheat sheet , which is continuously updated . It is recommended to collect, brush the questions in the order of my articles , master various algorithm routines, and then cast them into the sea of questions.
In this way, our first problem is solved. For each node, the subTree variable in the recursive function can describe the binary tree rooted at that node .
Now we solve the second problem. I know what I look like. How do I know what others look like ? So I can know if there are other subtrees that repeat with me, right.
This is very simple. We use an external data structure to let each node store the serialized result of its own subtree. In this way, for each node, can't we know if there is any other node's subtree duplicated by itself? ?
The preliminary idea can use the HashSet record subtree, the code is as follows:
// record all subtrees
HashSet<String> memo = new HashSet<>();
// Record the root node of the repeated subtree
LinkedList<TreeNode> res = new LinkedList<>();
String traverse(TreeNode root) {
if (root == null) {
return "#";
}
String left = traverse(root.left);
String right = traverse(root.right);
String subTree = left + "," + right+ "," + root.val;
if (memo.contains(subTree)) {
// Someone repeats with me and adds himself to the result list
res.add(root);
} else {
// No one will repeat with me for now, add yourself to the collection
memo.add(subTree);
}
return subTree;
}
But then, that there is a problem, if more than trees duplicate subtrees appear, the result set res is bound duplication, and questions asked do not want to duplicate.
To solve this problem, you can HashSet upgrade to HashMapan additional record of the number of occurrences of each subtree:
// Record all subtrees and the number of occurrences
HashMap<String, Integer> memo = new HashMap<>();
// Record the root node of the repeated subtree
LinkedList<TreeNode> res = new LinkedList<>();
/* Main function */
List<TreeNode> findDuplicateSubtrees(TreeNode root) {
traverse(root);
return res;
}
/* Auxiliary function */
String traverse(TreeNode root) {
if (root == null) {
return "#";
}
String left = traverse(root.left);
String right = traverse(root.right);
String subTree = left + "," + right+ "," + root.val;
int freq = memo.getOrDefault(subTree, 0);
// Repeated multiple times will only be added to the result set once
if (freq == 1) {
res.add(root);
}
// Add one to the number of occurrences corresponding to the subtree
memo.put(subTree, freq + 1);
return subTree;
}
In this way, this problem is completely solved. The problem itself is not difficult, but the disassembly of the idea is still quite enlightening, right?
_____________