Original Song Baohua Linux Reading Field2019-12-23
Preface
There are more than tens of millions of articles on the read and write process of BIO and block devices on the Internet, but it is hard to find articles that can make you thoroughly understand and understand.
I used to cross the mountains and the sea and cross the sea of people
I once asked the whole world and never got the answer
This article uses the simplest read(fd, buf, 4096) code to analyze its magnificent life in the entire Linux system from the beginning to the end. The code involved in this article is as follows:
#include <unistd.h>
#include <fcntl.h>
main()
{
int fd;
char buf[4096];
sleep(30); //run ./funtion.sh to trace vfs_read of this process
fd = open("file", O_RDONLY);
read(fd, buf, 4096);
read(fd, buf, 4096);
}The writing purpose of this article is: never pretend to be forced, it must be simple, simple, and simple!
This article is suitable for readers who have read a lot of messy block materials, but haven't gotten the context;
This article is not suitable for: readers who do not know what the block subsystem is, and readers who know exactly what the block subsystem is
Page cache and pre-reading
In Linux, the memory acts as the page cache of the hard disk. Therefore, every time you read, it will first check whether the data of the hard disk file you read is hit by the memory. If there is no hit, it will go to the hard disk; if it has been hit, then Read it directly from the memory. If it is writing, if the application is written in non-SYNC mode, the written data will only enter the memory, and then the kernel will help writeback into the hard disk at the appropriate time. 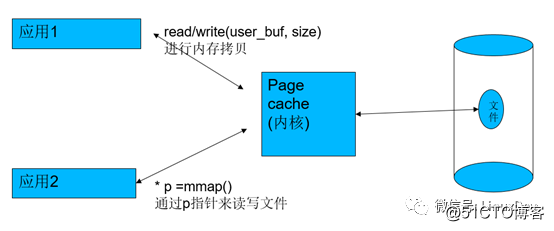
There are two lines of read(fd, buf, 4096) in the code. When the first line of read(fd, buf, 4096) occurs, obviously the data in the "file" file is not in the memory. At this time, a real hard disk read must be performed , App only wants to read 4096 bytes (one page), but the kernel will not just read one page, but read more, read ahead, and read first what users don’t read now, because the kernel suspects that you read one page , And then read continuously, suspecting that you want to read later. Rather than waiting for you to send instructions, it is better to chop and play in advance (the storage medium performs a large block read faster than multiple small block reads). At this time, it will perform pre-reading, such as reading 4 pages directly, so that when you continue to read second When there are 4 pages of hard disk data, it actually hits directly.
So the code path is now: 
when you execute the first read(fd, buf, 4096), 0~16KB of the "file" file is entered into the pagecache, and the kernel will mark the second page with a PageReadahead tag, meaning That is, if the app continues to read the second page, it can predict that the app is doing sequential reading, so that when the app reads the second page, the kernel can further asynchronous pre-reading.
Before the first read (fd, buf, 4096), the page cache hits (none hits): After the 
first read (fd, buf, 4096), the page cache hits: 
we hit the second one immediately read(fd, buf, 4096), it needs to read the contents of page 2 of the hard disk file. At this time, page 2 is hit by the page cache. This time, because page 2 has the PageReadahead mark, the kernel thinks that the app is When reading files sequentially, the kernel will perform more aggressive asynchronous pre-reading, such as reading the 16th KB~48KB of the file.
So the code path of the second read(fd,buf, 4096) is now: before the 
second read(fd,buf, 4096), the page cache hit situation: after the 
second read(fd,buf, 4096), page Cache hit situation:
Memory to hard disk conversion
As we mentioned earlier, the first read(fd, buf, 4096) becomes the reading of 16KB data in the hard disk to 4 pages of memory (corresponding to the 0~16KB of the file data in the hard disk). But we still don’t know where the 0~16KB of the file data in the hard disk is located on the hard disk? We must convert the pages of the memory to the actual location in the hard disk to be read.
In Linux, the data structure used to describe the mapping relationship between the actual operation location in the hard disk and the page cache page is bio. I believe you have seen bio 10,000 times, but it just doesn't match the real case.
The definition of bio is as follows (include/linux/blk_types.h):
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
…
struct bvec_iter bi_iter;
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
…
bio_end_io_t *bi_end_io;
void *bi_private;
unsigned short bi_vcnt; /* how many bio_vec's */
atomic_t bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
…
};It is a data structure that describes the corresponding relationship between the position in the hard disk and the page cache page. Each bio corresponds to a continuous position in the hard disk. The continuous position in each hard disk may correspond to multiple pages in the page cache, or one Page, so there will be a bio_vec *bi_io_vec table in it.
We now assume 2 situations
The first case is that the 0~16KB data to be read by page_cache_sync_readahead() is arranged in sequence in the hard disk (whether it is arranged in order, check the file system, such as ext3, ext4), Linux will read 4 pages this time, Allocating 1 bio is enough, and let this bio allocate 4 bi_io_vec, pointing to 4 different memory pages: 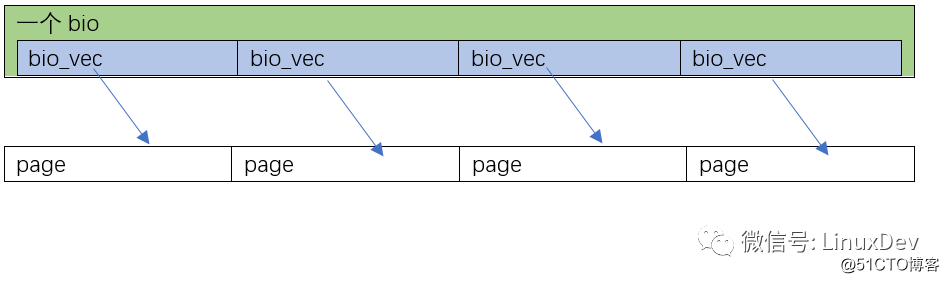
the second case is the 0~16KB data to be read by page_cache_sync_readahead(), which happens to be completely discontinuous in the hard disk The 4 blocks (whether they are arranged in order, check the file system, such as ext3, ext4), Linux will allocate 4 bios for this 4-page reading, and let each of these 4 bios allocate 1 bi_io_vec, pointing to 4 different memory pages: 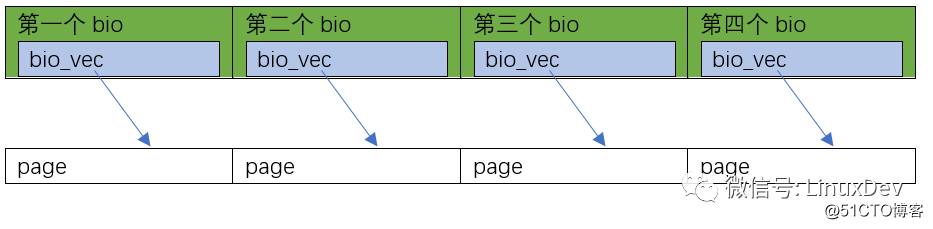
Of course, you can also have the third situation, such as 0~8KB continuous in the hard disk, 8~16KB discontinuous, it can be like this: 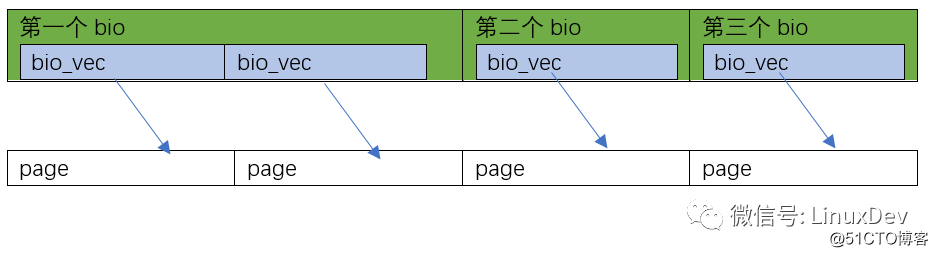
other situations please similar reasoning... to complete this work The epic code is mpage_readpages(). 
mpage_readpages() will indirectly call ext4_get_block() to really figure out the position of 0~16KB of data in the hard disk, and based on this information, convert one bio.
Three in and three out of bio and request
Life, in the end, is as simple as life and death. But because of the ups and downs of fate and the warmth of the world, the simple process has become ups and downs and complicated. Xiaoping made three ups and downs and finally established an immortal feat. Mandela was inhumanely treated and served decades in prison and eventually became a recognized leader in the world. The road to freedom will not be smooth, struggle is life. Fighting against the sky is endless joy; fighting against the earth is endless joy; fighting Linux is endless pain!
After the bio was produced, to the final completion, it also experienced a three-in-three-out queue. The hardships and pains of this process made people want to stop.
The three steps are:
1. Gathering in place
Convert bio to request, put the request into the plug queue local to the process; after accumulating multiple requests, release the flood.
2. Elevator sorting
The request of the local plug queue of the process enters the elevator, merges and sorts again, executes QoS queuing, and then distributes to the block device driver according to the QoS result. There can be various queues for the internal realization of the elevator.
3. Distribution execution
The requests distributed by the elevator are taken out one by one by the request_fn() of the device driver, and the real hardware read and write commands are sent to the hard disk. This dispatched queue is generally the request_queue we see in the block device driver.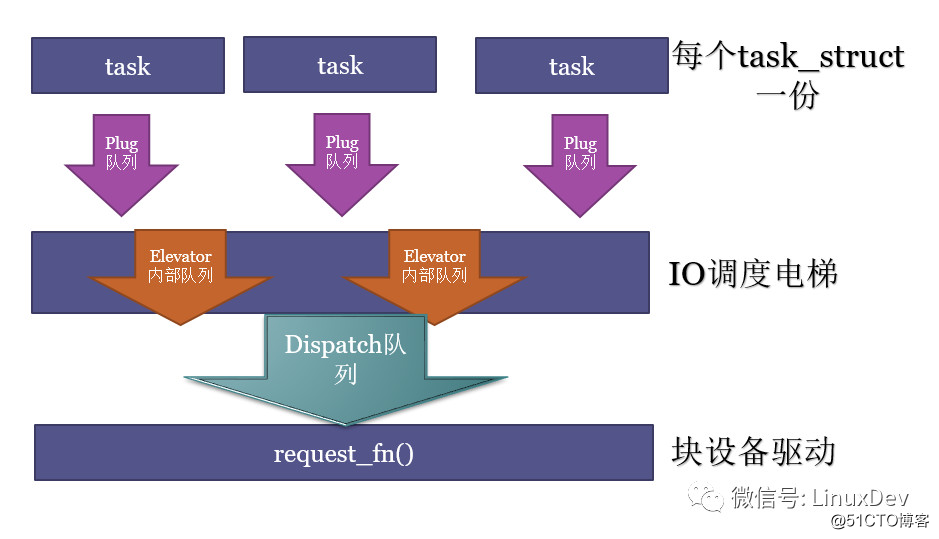
Below we present one by one, these three in and three out.
Gathering in place
In Linux, each task_struct (corresponding to a process, or lightweight process-thread), there will be a plug list. What is plug? Similar to Gezhouba and Three Gorges, the water is stored first. When the app needs to send multiple bio requests, it is better to gather momentum first instead of sending them to the final hard disk one by one.
This is similar to how you now have 10 teachers, and all these 10 teachers accept student registration when the school starts. Then there is a large student queue. If each teacher visits the unique student queue when a student signs up, then the operation of this queue will become an important lock bottleneck: 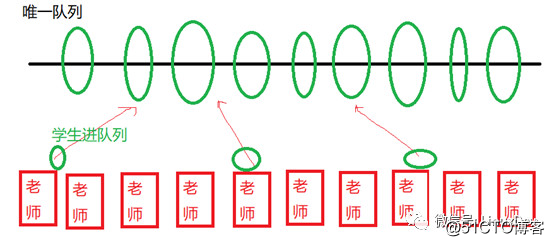
if we change the method, let each When the teacher has students registering, the students who register every day hang on the teacher’s own queue. After a lot of students hang on the teacher’s queue, the flood will be released a day later and hang on to the final student queue to avoid this problem. It is good to control the timing when the queue is merged into a large queue.
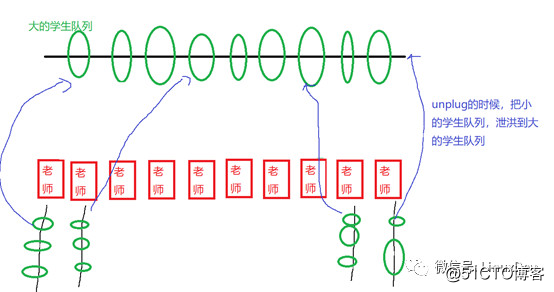
You will find that the code path is like this: The 
read_pages() function first pulls the gate up, then initiates a series of bios, and then releases the flood through the call of blk_finish_plug(). 
In the process of gaining momentum, an important task is to be completed, which is to make request. This epic-level function to complete the "request" is generally void blk_queue_bio(struct request_queue q, struct bio bio), located in block/blk-core.c.
It will try to merge bio into a request in the local plug list of a process. If it cannot be merged, it will create a new request. The request contains a bio list, and the hard disk location corresponding to the bio in this list is finally stored continuously on the hard disk.
Below we assume that the storage location of 0~16KB of "file" on the hard disk is: 
According to the example we gave in the section "Memory to hard disk conversion", this belongs to the "case 2" which is completely discontinuous in the hard disk, so this 4 pieces of data will be converted into 4 bio by epic mpage_readpages(). 
When they enter the local plug list of the process, since the plug list is empty at the beginning, 100 obviously cannot be merged with someone, thus forming a new request0.
Bio1 cannot be merged into request0, so it gets a new request1.
Bio2 can be merged into request1, so Bio1 merges into request1.
Bio3 corresponds to 200 blocks of the hard disk and cannot be combined, so a new request2 is obtained.
Now the requests on the local plug list of the process are arranged as follows:
When flooding, the request of the local plug list of the process will be added to the elevator queue by calling the elevator_add_req_fn() callback function of the elevator scheduling algorithm.
Elevator sorting
When the request in the local plug list of each process is flooded, and it enters in an overwhelming manner, it is not the final device driver (which will not be directly shot to death on the beach), but an elevator queuing algorithm to queue again . This elevator dispatch has three purposes:
- Further merge request
- Make request access to the hard disk sequential
- Perform QoS
The internal implementation of the elevator can be very flexible, but the entrance is elevator_add_req_fn() and the exit is elevator_dispatch_fn().
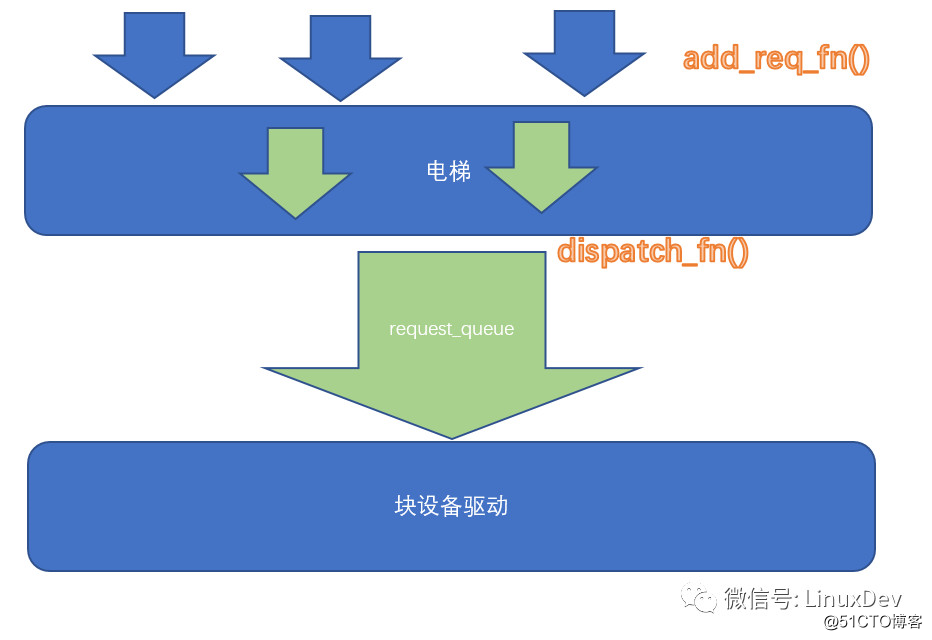
Both merging and sorting are easy to understand. Below we focus on QoS (Quality of Service). Imagine the broadband in your home, there are Thunder, there are online movies, and the organic top box is used to watch TV.
When you only use Thunder to download movies, of course you can download movies at full speed, but when you are still watching TV and watching movies online, at this time, you may limit the current of Thunder to ensure the service quality of related TV box movies.
The same logic is also executed in elevator scheduling, such as the CFQ scheduling algorithm, which can adjust the priority of different processes when accessing the hard disk according to the ionice of the process. For example, the following two dds with different priorities
# ionice-c 2 -n 0 cat /dev/sda > /dev/null&
# ionice -c 2 -n 7 cat /dev/sda >/dev/null&The final access speed of the hard disk is different, one is 371M, and the other is only 72M. 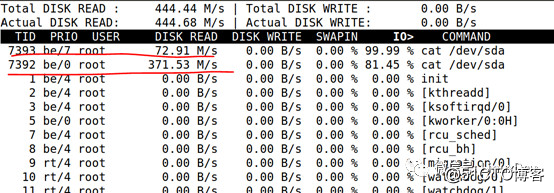
So when the flood discharge begins, the rivers are full of bitterness, and hundreds of rivers are fighting for the flow. Who can hit the water in the middle of the stream, and the waves will stop the boat? QoS is a story about the success of everything .
Currently commonly used IO elevator scheduling algorithms are: cfq, noop, deadline. The detailed differences are not the focus of this article. It is recommended to read "Liu Zhengyuan: Linux General Block Layer DeadLine IO Scheduler" to start with understanding the implementation of deadlines.
Distribution execution
When it comes to the last time to cross the gap, the device driver's request_fn() calls the elevator_dispatch_fn() of the elevator scheduling algorithm to take out the QoS sorted request and send the command to the final storage device to perform I/O actions.
static void xxx_request_fn(struct request_queue *q)
{
struct request *req;
struct bio *bio;
while ((req = blk_peek_request(q)) != NULL) {
struct xxx_disk_dev *dev = req->rq_disk->private_data;
if (req->cmd_type != REQ_TYPE_FS) {
printk (KERN_NOTICE "Skip non-fs request\n");
blk_start_request(req);
__blk_end_request_all(req, -EIO);
continue;
}
blk_start_request(req);
__rq_for_each_bio(bio, req)
xxx_xfer_bio(dev, bio);
}
}request_fn() just dispatches read and write events and commands, and the final completion is generally in another context, not the process of initiating IO. After the request processing is completed, the context that detects the completion of the IO will notify the process waiting for the completion of the IO request in the form of blk_end_request(). The code sequence of the process that actively initiates IO is generally:
- submit_bio()
- io_schedule(), give up the CPU.
blk_end_request() generally wakes up processes that gave up the CPU after io_schedule(). The waiting time of io_schedule() will be calculated into the iowait time of the process. For details, see: "Zhu Hui (tea): Linux Kernel iowait time code principle".
Catch all processes with Ftrace
All processes involved in this article can be traced with ftrace. In this way, you can learn more and deeper details.
char buf[4096];
sleep(30); //run ./funtion.sh to trace vfs_read of this process
fd = open("file", O_RDONLY);
read(fd, buf, 4096);In the middle of the above code, I deliberately left a delay of 30 seconds. During this delay, you can start the following script to trace the function graph of the entire process. After the capture process starts to vfs_read() The call stack:
#!/bin/bash
debugfs=/sys/kernel/debug
echo nop > $debugfs/tracing/current_tracer
echo 0 > $debugfs/tracing/tracing_on
echo `pidof read` > $debugfs/tracing/set_ftrace_pid
echo function_graph > $debugfs/tracing/current_tracer
echo vfs_read > $debugfs/tracing/set_graph_function
echo 1 > $debugfs/tracing/tracing_onThe author also used the result of ftrace, opened it with vim, and analyzed it sentence by sentence. For the detailed method used by ftrace, you can read "Song Baohua: A Complete Case About Ftrace".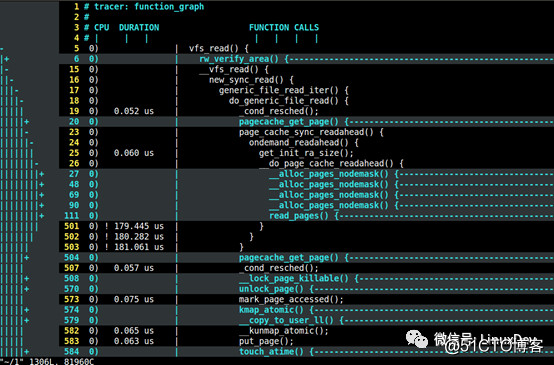
Final words
This article describes the trunk, many details and code branches are not involved, because too many branches are described in this article, which will make readers unable to grasp the trunk. Many branches have not been introduced, such as unplug flooding. In addition to the artificial blk_finish_plug() flooding, automatic flooding also occurs when the plug queue is full, and when the process sleeps schedule(). In addition, with regard to writing, the following three-in and three-out process is basically similar to reading, but writing has a page cache stacking and writeback startup mechanism, which is not available in read.
(Finish)