LSQ: Low-bit quantization based on trainable Step_size
from ICLR2020
IBM Research
Abstract
Neural network has the advantages of low power consumption and easier storage when running inference with low accuracy, but at the expense of accuracy, so this article is dedicated to solving this problem. When the LSQ quantization scheme proposed in this paper is applied to different architectures, it has reached SOTA on the ImageNet data set. The weight and activation value are quantized to 2, 3, and 4 bits, and the accuracy of the full-precision model is reached when the quantization number is 3 bits. LSQ improves the configuration of the quantizer itself on the basis of the existing learning weight quantification; it is worth mentioning that a new gradient loss is introduced to estimate and scale the weight and activation value of each layer Quantize the step size so that it can be trained with other parameters in the network. This quantitative strategy can be set according to the different needs of a given system, and only the original code needs to be modified.
Section I Introduction
Deep learning has shined in some revolutionary technologies, such as image recognition, speech recognition, and autonomous driving. However, it is necessary to consider actual performance, throughput, energy efficiency, model compactness and other indicators while fully exploiting the potential of deep learning. Co-design of algorithms and hardware deployment is needed. At present, many scholars are committed to maintaining the high precision of the deep network while compressing the accuracy required by the weight and activation value as much as possible, thereby reducing the amount of calculation and the required memory of the model. The network designed according to this idea has been successfully applied to In some systems.
Quantization is to map high-precision weights and activation values to a set of discrete values composed of lower precision, usually 8bit or less. This article hopes to propose a separate quantification scheme for each layer to maximize the performance of the model. This is still an open question. At present, most network quantization uses a consistent quantization scheme, which mainly determines a single quantization step size parameter; then further considers non-uniform quantization mapping, which is more complicated. For example, Hubara et al. designed a mixed configuration quantizer, Rastegari et al. focused on using the characteristics of data distribution to complete the quantization mapping of data, and Cai et al. focused on how to minimize the quantization error during the training process.
Recently, people's attention is focused on how to optimize the error generated by quantization by using backpropagation stochastic gradient descent. Although the fixed quantization scheme mentioned above is simple, it cannot guarantee network performance; although the idea of minimizing quantization error can theoretically obtain the smallest quantization error, it may not be optimal.
It seems very attractive to optimize the mapping scheme of the quantizer by minimizing the loss function, because it directly optimizes the most critical/interesting part, but since the quantizer itself is not continuous, how to calculate the gradient is a big problem. The current approximate processing is already a very crude way, and the transition between different states has been ignored.
Therefore, this paper proposes an LSQ strategy for learning each layer of mapping in the deep network-Learned Step Size Quantization (step size learning strategy). There are two main highlights:
First, a simple method of approximating the quantization gradient is proposed. The quantization step size can be used as a parameter to optimize the quantizer at a finer-grained level;
Secondly, a simple and feasible heuristic algorithm is proposed, which can better balance the step size and the weight update range, which helps to improve the convergence of the model.
LSQ can be used for both weight and activation value quantization, and is compatible with existing back propagation and stochastic gradient descent. A variety of quantized network architectures have been tested on the ImageNet data set, and all have better accuracy than the original quantization scheme; even a landmark realization of the 3bit quantization network and the full-precision network to achieve the same accuracy.
Section II Methods
We assume that the network uses low-precision shaping numbers to complete the calculation of the convolutional layer and the fully connected layer during inference, which requires degree weights and activation values to quantify.
For the data v to be quantized, s is the step size parameter that needs to be learned-step size, Qp and Qn respectively represent two quantization levels, and the quantizer is responsible for calculating the result of v quantization vbar, vbar multiplied by the scaling factor s You will get v^.
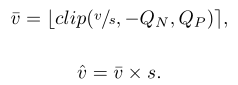
clip(z,r1,r2) returns the value z, if less than r1, shezhiweir1, if higher than r2, set to r2, [z] operation is responsible for rounding z to the nearest integer; for unsigned numbers, bbit quantization is used, Then the quantization range (Qn, Qp) = (0, 2^b-1),
for the number of symbols, the quantization range (Qn, Qp) = (2 b-1,2 b-1-1).
Therefore, when inferring, wbar and xbar can be used as inputs for low-precision integer multiplication operations, while the output of the convolutional layer and fully connected layer can be rescaled according to the step size, and high-precision scalar multiplication can be performed at a lower cost, even It can be combined with normalization operations such as BN. Fig1 shows the specific calculation process.
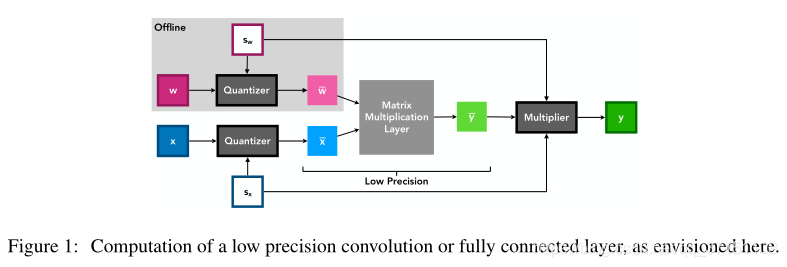
The Part A Step Size Gradient
Step size gradient is calculated as follows: An approximate estimate of the gradient is obtained through Benigo's STE algorithm (straight through estimator). The core idea of STE is that when our parameters are initialized, it is a continuous value like float. When we forward The original continuous parameters are mapped to {-1, 1} and brought into the network for calculation, so that the output of the network can be calculated. Then when backward, the original float parameters are directly updated, instead of the binary parameter update.
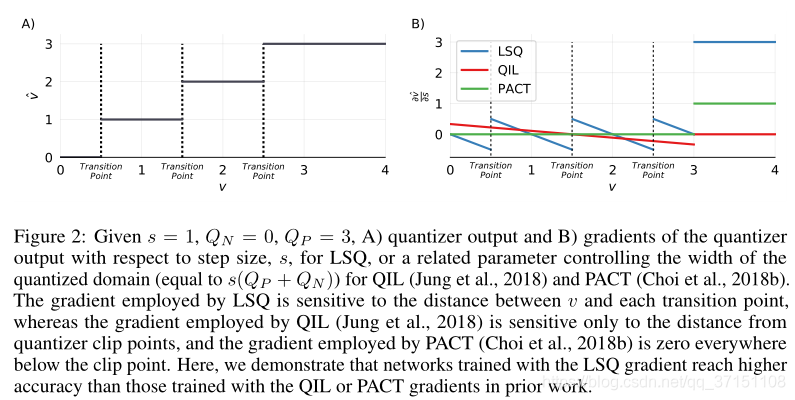
Taking Fig2 as an example, (A) is the conventional quantization (B) is the output of different quantization strategies of LSQ, QIL, and PACT. It can be seen that the gradient of LSQ is more sensitive to the surrounding transition points. In contrast, QIL is only related to the distance to the clip point, not to mention the gradient of constant 0 in PACT, so we have reason to think that the gradient training network obtained by LSQ calculation can achieve higher accuracy. Because in the QIL and PACT methods, the distance between v and the state transition point does not affect the gradient of the quantization parameter.
It can also be considered that the closer the given input data v is to the jump point, the more likely it is that the quantized bin will be changed due to the update of the network parameters, thereby causing a larger change in v^. Therefore, we naturally expect that ∂ˆv/∂s can increase as the distance from v to the jump point is closer, and we do see this trend in LSQ, which is more practical than using a fixed quantization scheme or STE approximate calculation. In this paper, the weight and activation value of each layer of the network has its own separate step size, represented by fp32, which is initialized to 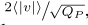
be calculated on the initial weight value or the first batch of activation values.

Part B Step Size Gradient Scale
Research has shown that the update of the weights of each layer in the network can make the training have better convergence when the update amplitude is approximately the same as the amplitude of the average parameter; as long as the appropriate learning rate is set It can be ensured that the update step is neither too large nor repeated jumps near the local minima, resulting in too long convergence time.
Therefore, this article also follows this rule because the step size is updated, so the following formula is adopted:
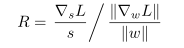
To calculate the proportion of adjustment. When the number of quantization bits is larger, the smaller step-size is used; when the number of quantization bits is smaller, the larger step-size is used. Therefore, it is necessary to multiply the gradient by a scaling factor g, and the calculation of the weight and the activation value g are respectively: where Nw represents the number of weights of a certain layer; Nf represents the number of features of a certain layer. Appendix Section A further explains that this helps to improve training accuracy.
Part C Training
LSQ optimizes the quantizer by assigning learnable parameters to the quantization step. In order to verify the effect of LSQ, this paper trains a BinaryConnect network. In BinaryConnect, the weight and activation value are binarized to reduce forward propagation and The requirement for multiplication in backpropagation, so the gradient calculation is as follows: For simplicity during training, v^ is also used as the input of matrix multiplication, which is equivalent to performing inference tasks. Later in this paper, the weights and activation values of the other layers except the first and last layers are quantized with 2, 3, 4, and 8 bits, and the other parameters are all 32-bit floating point numbers. All the quantitative networks participating in the comparison are initialized from a full-precision network. Training uses the cross-entropy loss function, momentum = 0.9, cosine attenuation, theoretically 8bit should be close to the full-precision network, so the 8bit network is only trained for 1 epoch, and other networks are trained for 90 epoch. Network frameworks include ResNet, VGG, and SqueezeNet. The input image is 256x256, cropped to 224x224 size, and the frame uses Pytorch.
Section III Results
Part A Weight Decay
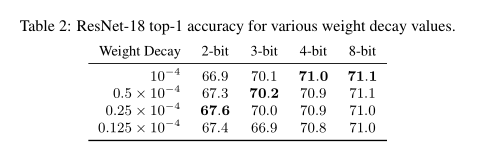
This article believes that reducing the accuracy of the model can reduce the strengths of overfitting, and it can also avoid the use of regularization in order to achieve good performance. For this reason, this article has carried out a parameter scan on the weight attenuation of different quantization bits in ResNet-18, from Table II. It can be seen that networks with lower quantization bits can achieve higher accuracy by setting smaller weight attenuation parameters. For example, when 3BIT quantization, the weight attenuation is halved, and when the weight is attenuated to 1/4 of the original for 2bit, the best is achieved. Accuracy.
Comparison of Part B and other quantization schemes
Table I shows the comparison of LSQ with other quantization schemes. For the sake of fairness, this article assumes that the weights and activation values of all convolutional and fully-connected layers in the model are quantized to a specific number of bits. Only the first and last layers maintain high precision. It can be found that LSQ quantization or even The accuracy is higher than full-precision, and the best accuracy is achieved regardless of the 2, 3, or 4bit quantization LSQ; in addition, it can be seen that the accuracy of ResNet-18 only dropped by 2.9 when the accuracy was 2bit, but the accuracy of SqueezeNet dropped. 14.0, one possible explanation is that SqueezeNet is designed to use as few parameters as possible to give full play to the performance of the model, resulting in some points that are very sensitive to accuracy.

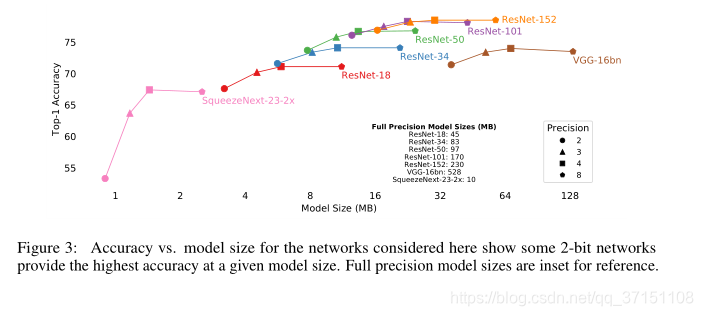
Part C Accuracy vs Model Size
For some applications that have restrictions on the model size, it is necessary to choose a model with better performance as much as possible on the premise of meeting the memory limit. Therefore, this article compares the top1 accuracy of models of different Model sizes, and it can be seen that ResNet is the best choice for scale and accuracy.
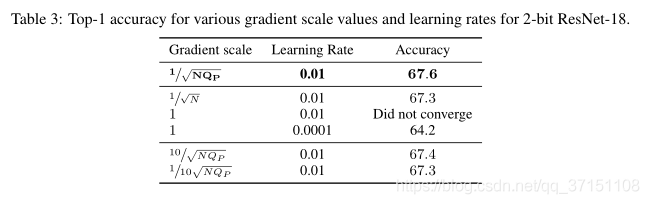
Part D Step Size Gradient Scale Impact
This article also analyzes the scaling index R, which is based on the average of 500 iterations in one epoch of ResNet-18; if not scaling, the calculated step size will be higher than the step size of each update of the weight. 2-3 orders of magnitude, by scaling the step size, this imbalance between step size and weight update is also largely eliminated. Table III shows the comparison results of 2bitResNet-18 scaling different scales. It can be seen that if the training is not scaled, the convergence cannot even be achieved; by adjusting the learning rate, the accuracy of the network convergence is also lower than the baseline by 3.4; this problem is achieved by scaling the gradient to 1. /√N can be solved, and the accuracy is only reduced by 0.3.
The role of Part E decay learning rate
This article uses cosine decay learning rate, which avoids setting the hyperparameters of learning rate decay, which is applicable in most frameworks without increasing training time. For example, 2bit ResNet18 uses LSQ to train 90 epochs to achieve an accuracy of 67.2. Although the accuracy is lower than the equivalent model by 0.4, it is still an average of 1.5 higher than other training methods.
Part F quantization error
Let’s explore whether LSQ is the smallest Quantization error, although this is not clearly indicated in the loss function. After analysis, it is found that LSQ does not actually minimize the quantization error, but directly seeks a better-precision quantization scheme, which also shows that simply using the optimizer to convert to the corresponding data distribution may not be the best quantization scheme.
Section IV Conclusions
The low-bit quantization scheme LSQ proposed in this paper surpasses the performance of other previous quantization schemes in many network frameworks. The core idea of LSQ is to learn the respective quantization step lengths of the weights and activation values of each layer, so as to ensure the best quantization of the network. Good performance, and the method itself only needs to add an additional parameter to each layer. Although the purpose of the proposed LSQ is to improve the accuracy of low-bit networks, it is still uncertain how quantized to 2bit is effective. It seems that there is still a certain gap with full-precision networks; but for some of the more popular frameworks, it has been proven to be used by appetite. For example, when the model is limited to 8M in size, the accuracy of using 2bit ResNet50 is better than that of 4bit ResNet-34.
The idea of low-bit quantification will continue to be explored, which can enhance the analogy between artificial neural networks and biological neural networks. For example, the synapses in biological neural networks can be represented by single-bit spikes; on the other hand, the number of bits in the model is reduced at the same time It can also maintain the accuracy of the model in terms of compressing the model and improving the throughput.