DataNode working mechanism
NameNode & DataNode working mechanism
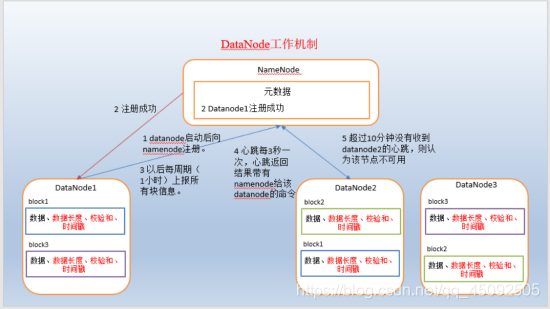 1) A data block is stored on the disk as a file on the datanode, including two files, one is the data itself, and the other is the metadata including the length of the data block, the checksum of the block data, and the timestamp.
1) A data block is stored on the disk as a file on the datanode, including two files, one is the data itself, and the other is the metadata including the length of the data block, the checksum of the block data, and the timestamp.
2) After the DataNode is started, register with the namenode, and after passing, report all block information to the namenode periodically (1 hour).
3) The heartbeat is every 3 seconds, and the heartbeat returns the result with the command given by the namenode to the datanode, such as copying block data to another machine, or deleting a data block. If the heartbeat of a datanode is not received for more than 10 minutes, the node is considered unavailable.
4) Some machines can be safely added and exited during cluster operation
Data integrity
1) When the DataNode reads the block, it will calculate the checksum checksum
2) If the calculated checksum is different from the value when the block was created, the block has been damaged.
3) The client reads the blocks on other DataNodes.
4) Datanode periodically verifies the checksum checksum after its file is created
Parameter setting for offline time limit
The death of the datanode process or the network failure causes the datanode to be unable to communicate with the namenode. The namenode will not immediately judge the node as dead. It will take a period of time, which is temporarily called the timeout period. The default timeout period of HDFS is 10 minutes + 30 seconds. If the timeout period is defined as timeout, the calculation formula for the timeout period is:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
And the default dfs.namenode.heartbeat.recheck-interval size is 5 minutes, and dfs.heartbeat.interval is 3 seconds by default.
It should be noted that the unit of heartbeat.recheck.interval in the hdfs-site.xml configuration file is milliseconds, and the unit of dfs.heartbeat.interval is seconds.
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
DataNode directory structure
Unlike the namenode, the storage directory of the datanode is automatically created at the initial stage and does not require additional formatting.
- Check the version number in the directory /opt/module/hadoop-2.8.4/data/dfs/data/current
[dingshiqi@bigdata111 current]$ cat VERSION
storageID=DS-1b998a1d-71a3-43d5-82dc-c0ff3294921b
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
datanodeUuid=970b2daf-63b8-4e17-a514-d81741392165
storageType=DATA_NODE
layoutVersion=-56
-
Specific explanation
(1) storageID: storage id number
(2) clusterID cluster id, globally unique
(3) The cTime attribute marks the creation time of the datanode storage system. For the newly formatted storage system, this attribute is 0; but after the file system is upgraded, the value will be updated to the new timestamp.
(4) datanodeUuid: unique identification code of datanode
(5) storageType: storage type
(6) layoutVersion is a negative integer. This version number is usually updated only when new features are added to HDFS.
-
Check the version number of the data block in the /opt/module/hadoop-2.8.4/data/dfs/data/current/BP-97847618-192.168.10.102-1493726072779/current directory
[dingshiqi@bigdata111 current]$ cat VERSION
#Mon May 08 16:30:19 CST 2017
namespaceID=1933630176
cTime=0
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-56
Specific explanation
1)namespaceID:是datanode首次访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可用这个属性来区分不同datanode。
(2)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(3)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的
BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(4)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
DataNode multi-directory configuration
The datanode can also be configured into multiple directories, and the data stored in each directory is different. That is: the data is not a copy.
The specific configuration is as follows:
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${
hadoop.tmp.dir}/dfs/data1,file:///${
hadoop.tmp.dir}/dfs/data2</value>
</property>
HDFS other features
Data copy between clusters
- scp realizes file copy between two remote hosts
- scp -r hello.txt root@bigdata111:/user/itstar/hello.txt // 推 push
scp -r root@bigdata112:/user/itstar/hello.txt hello.txt // 拉 pull
scp -r root@bigdata112:/opt/module/hadoop-2.8.4/LICENSE.txt root@bigdata113:/opt/module/hadoop-2.8.4/LICENSE.txt
//是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
Use discp command to realize recursive data replication between two hadoop clusters (note: no need to set other, write IP directly)
bin/hadoop distcp hdfs://192.168.1.51:9000/LICENSE.txt hdfs://192.168.1.111:9000/HAHA
Hadoop (not suitable for storing small files) archive
-
Theory overview
Each file is stored in blocks, and the metadata of each block is stored in the memory of the namenode, so hadoop is very inefficient to store small files. Because a large number of small files will use up most of the memory in the namenode. But note that the disk capacity required to store small files will not increase compared to the disk space required to store the original content of these files. For example, a 1MB file is stored in blocks of 128MB, using 1MB of disk space instead of 128MB.
Hadoop archive files or HAR files are a more efficient file archiving tool. It stores files in HDFS blocks, which allows transparent access to files while reducing the memory usage of the namenode. Specifically, Hadoop archive files can be used as input to MapReduce.
https://www.cnblogs.com/staryea/p/8603112.html
-
Case practice
-
Need to start the yarn process
start-yarn.sh -
Archive file
Filed into a folder called xxx.har, there are corresponding data files under this folder. The Xx.har directory is a whole, and the directory can be regarded as an archive file.
 -Usage: hadoop archive -archiveName archive name -p parent directory [-r <replication factor>] original path (can be multiple) destination path
-Usage: hadoop archive -archiveName archive name -p parent directory [-r <replication factor>] original path (can be multiple) destination path
bin/ hadoop archive -archiveName foo.har -p /Andy -r 3 a b c / -
-
View archive
hadoop fs -lsr /user/my/myhar.har hadoop fs -lsr har:///myhar.har - - Solutions archive
- - Solutions archive取消存档:hadoop fs -cp har:/// user/my/myhar.har /* /user/itstar 并行解压缩:hadoop distcp har:/foo.har /001
Snapshot management
The snapshot is equivalent to a backup of the directory. It will not copy all files at once, but point to the same file. When writing occurs, a new file will be generated.
-
Basic grammar
hdfs dfsadmin -allowSnapshot 路径 (功能描述:开启指定目录的快照功能) hdfs dfsadmin -disallowSnapshot 路径 (功能描述:禁用指定目录的快照功能,默认是禁用) hdfs dfs -createSnapshot 路径 (功能描述:对目录创建快照) hdfs dfs -createSnapshot 路径 名称 (功能描述:指定名称创建快照) hdfs dfs -renameSnapshot 路径 旧名称 新名称 (功能描述:重命名快照) hdfs lsSnapshottableDir (功能描述:列出当前用户所有已快照目录) hdfs snapshotDiff 路径1 路径2 (功能描述:比较两个快照目录的不同之处) hdfs dfs -deleteSnapshot <path> <snapshotName> (功能描述:删除快照) -
Case practice
(1)开启/禁用指定目录的快照功能 hdfs dfsadmin -allowSnapshot /user/itstar/data hdfs dfsadmin -disallowSnapshot /user/itstar/data (2)对目录创建快照 hdfs dfs -createSnapshot /user/itstar/data // 对目录创建快照 用相同数据块 hdfs dfs -lsr /user/itstar/data/.snapshot/ (3)指定名称创建快照 hdfs dfs -createSnapshot /user/itstar/data miao170508 (4)重命名快照(注:快照是只读的,无法修改名) 快照的目录 老快照的名字 新快照的名字 hdfs dfs -renameSnapshot /Andy/ andy bndy 注:路径只是你创建得名字/Andy,不要带后边得/Andy/.snapshot/,不然会出现 renameSnapshot: Modification on a read-only snapshot is disallowed (5)列出当前用户所有可快照目录 hdfs lsSnapshottableDir (6)比较两个快照目录的不同之处 快照的名字 之前的快照名字 新快照的名字 hdfs snapshotDiff /user/itstar/data/ plus plus1 (7)恢复快照 1.自定义创建一个快照名:hdfs dfs -createSnapshot /HAHA1 miaomiao 2.展示原文件包含内容:Hadoop fs -ls /HAHA1 3.里面有五个文件、删除其中1~2个 4.回复快照:hdfs dfs -cp /HAHA1/.snapshot/miaomiao1 /miaomiao (8)删除快照 hdfs dfs -deleteSnapshot /001名字
Recycle bin
-
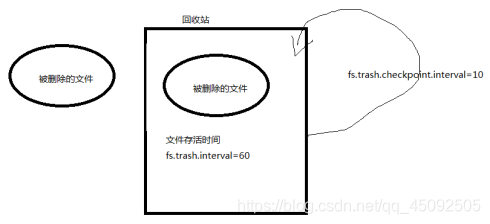
Default recycle bin
The default value fs.trash.interval=0, 0 means the recycle bin is disabled, and the survival time of deleted files can be set.
The default value is fs.trash.checkpoint.interval=0, the interval of checking the recycle bin.
Request fs.trash.checkpoint.interval<=fs.trash.interval.
 -Enable recycle bin
-Enable recycle binModify core-site.xml and configure the garbage collection time to 1 minute.
<property> <name>fs.trash.interval</name> <value>1</value> </property> -
View the recycle bin
Recycled in the cluster; path: /user/itstar/.Trash/...
-
Modify the user name for accessing the garbage collection bin
Enter the user name of the garbage collection station, the default is dr.who, modify it to the itstar user
#core-site.xml <property> <name>hadoop.http.staticuser.user</name> <value>itstar</value> </property> -
Files deleted by the program will not go through the recycle bin, and need to call moveToTrash() to enter the recycle bin
Trash trash = New Trash(conf); trash.moveToTrash(path); -
Restore Recycle Bin Data
hadoop fs -mv /user/itstar/.Trash/Current/user/itstar/input /user/itstar/input -
Empty the recycle bin
hdfs dfs -expunge