In the last lesson, we learned about the basic principles of website login verification and simulated login. There are two main implementations of website login verification, one is login verification based on Session + Cookies, and the other is login verification based on JWT. In this lesson, we will use two examples to explain the analysis and verification of these two login verifications. Simulate the login process.
Ready to work
Before starting this lesson, please make sure that you have made the following preparations:
- Installed Python (preferably version 3.6 and above) and can successfully run Python programs;
- Installed the requests request library and learned its basic usage;
- I installed the Selenium library and learned its basic usage.
Below we take two cases as examples to explain the implementation of simulated login respectively.
Case Introduction
There are two websites that require login to crawl. The links are https://login2.scrape.cuiqingcai.com/ and https://login3.scrape.cuiqingcai.com/ . The former is a website based on Session + Cookies authentication. The latter is a website based on JWT certification.
First look at the first website. After opening, you will see the page as shown in the figure.

It jumps directly to the login page, where the username and password are both admin, and we log in after entering it.
After successfully logging in, we see the display page of the familiar movie website, as shown in the figure.

This website is developed based on the traditional MVC model, so it is also more suitable for Session + Cookies authentication.
After the second website is opened, it will also jump to the login page, as shown in the figure.
The user name and password are the same, enter admin to log in.
After logging in, it will jump to the home page, displaying some book information, as shown in the figure.

This page is a separated front-end and back-end page. Data loading is obtained through Ajax request back-end API interface. The login verification is based on JWT. At the same time, each back-end API will verify whether the JWT is valid, and if it is invalid No data will be returned.
Case number one
Next, we will analyze these two cases and implement simulated login.
For case 1, if we want to simulate login, we need to analyze what happened in the login process. First, we open https://login2.scrape.cuiqingcai.com/ , and then perform the login operation to see what happened during the login process Request as shown.

Here we can see that the moment he logged in, he initiated a POST request, the target URL is https://login2.scrape.cuiqingcai.com/login , and the login data was submitted through form submission, including two fields username and password , The status code returned is 302, the location field of the Response Headers is the root page, and the Response Headers also contains the set-cookie information and sets the Session ID.
From this we can find that to achieve simulated login, we only need to simulate this request. After the login is completed, get the Cookies set by Response, save the Cookies, and subsequent requests can be accessed normally with Cookies.
OK, then let's implement it in code next.
Requests By default, each request is independent and does not interfere with each other. For example, we first call the post method to simulate login, and then call the get method to request the main page. In fact, these are two completely independent requests. Cookies obtained by the first request cannot be passed to the second request, so the conventional sequential call cannot have the effect of simulating login.
Let's first look at an invalid code:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, data={
'username': USERNAME,
'password': PASSWORD
})
response_index = requests.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
Here we first define a few basic URLs, usernames, and passwords, and then use requests to request the login URL to simulate login, and then request the home page to get the page content, but can we get the data normally?
Since requests can automatically handle redirection, we finally print out the URL of the Response. If the result is INDEX_URL, it proves that the simulated login is successful and the content of the homepage is successfully crawled. If it jumps back to the login page, then the simulated login failed.
Let's verify by the results, the results are as follows:
Response Status 200
Response URL https://login2.scrape.cuiqingcai.com/login?next=/page/1
It can be seen here that the final page URL is the URL of the login page. In addition, the source code of the page can also be verified by the text attribute of the response. The source code content is the source code content of the login page. Because of the large content, it will not be output here. Compare it.
In short, this phenomenon shows that we did not successfully complete the simulated login. This is because requests directly call post, get and other methods. Each request is an independent request, which is equivalent to opening a new browser to open these links. The session corresponding to this request is not the same, so here we simulate the login of the first Session, and this does not affect the state of the second Session, so the simulated login is invalid.
So how can we achieve the correct simulated login?
We know that the Session ID information is stored in Cookies. We have just observed that there is a set-cookie field in the Response Headers after a successful login. In fact, this is to make the browser generate Cookies.
Cookies contain Session ID information, so as long as subsequent requests carry these Cookies, the server can find the corresponding Session through the Session ID information in Cookies, so the server will use the same Session for these two requests. And because we have completed the simulated login for the first time, after the first simulated login is successful, the user's login information is recorded in the Session. When the second time is accessed, since it is the same Session, the server can know the current user If it is the login status, you can return the correct result instead of jumping to the login page.
Therefore, the key here is the delivery of cookies for two requests. So here we can save the cookies after the first simulated login, and add this cookie in the second request, so the code can be rewritten as follows:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, data={
'username': USERNAME,
'password': PASSWORD
}, allow_redirects=False)
cookies = response_login.cookies
print('Cookies', cookies)
response_index = requests.get(INDEX_URL, cookies=cookies)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
Since requests can automatically handle redirection, we need to add the allow_redirects parameter to simulate the login process and set it to False to prevent it from automatically processing redirection. Here, the response returned after login is assigned to response_login, so by calling response_login cookies The cookies information of the website can be obtained. Here, requests automatically help us parse the set-cookie field of Response Headers and set Cookies, so we don’t need to manually parse the content of Response Headers. You can get it directly by using the cookies property of the response_login object. Cookies.
Ok, next we use the get method of requests again to request the INDEX_URL of the website, but this is different from before. The get method adds a parameter cookie. This is the cookies obtained after the first simulation login, so the second request is It is possible to carry the cookies information obtained by the first simulated login. At this time, the website will find the same Session according to the Session ID information in the Cookies, verify that it is already logged in, and then return the correct result.
Here we still output the final URL. If it is INDEX_URL, it means the simulated login is successful and valid data is obtained, otherwise it means the simulated login failed.
We look at the results of the operation:
Cookies <RequestsCookieJar[<Cookie sessionid=psnu8ij69f0ltecd5wasccyzc6ud41tc for login2.scrape.cuiqingcai.com/>]>
Response Status 200
Response URL https://login2.scrape.cuiqingcai.com/page/1
There is no problem now, this time we found that its URL is INDEX_URL, and the simulated login is successful! At the same time, you can further output the text attribute of response_index to see if the acquisition is successful.
The subsequent crawling can be crawled in the same way.
But we found that this method of implementation is actually quite cumbersome. Cookies need to be processed and passed on each time. Is there an easier way?
Yes, we can directly use the built-in Session object of requests to help us automatically process Cookies. After using the Session object, requests will automatically save the Cookies that need to be set after each request, and automatically carry it on the next request. It is equivalent to helping us maintain a Session object, which is more convenient.
So, the code just now can be simplified as follows:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
session = requests.Session()
response_login = session.post(LOGIN_URL, data={
'username': USERNAME,
'password': PASSWORD
})
cookies = session.cookies
print('Cookies', cookies)
response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
As you can see, we no longer need to care about the handling and delivery of Cookies. We declare a Session object, and then use the post or get method of the Session object directly every time a request is called.
The running effect is exactly the same, and the results are as follows:
Cookies <RequestsCookieJar[<Cookie sessionid=ssngkl4i7en9vm73bb36hxif05k10k13 for login2.scrape.cuiqingcai.com/>]>
Response Status 200
Response URL https://login2.scrape.cuiqingcai.com/page/1
Therefore, in order to simplify the writing, it is recommended to directly use the Session object to make the request, so that we don't need to care about the operation of Cookies, and it will be more convenient to implement.
This case is relatively simple overall, but if you encounter a more complex website, such as a verification code, with encrypted parameters, etc., it is not easy to directly use requests to handle the simulated login. If you can't log in, then the entire page is not Can't climb anymore? So is there any other way to solve this problem? Of course there are. For example, we can use Selenium to simulate a browser to achieve simulated login, and then obtain the cookies after the simulated login is successful, and then send the obtained cookies to requests for crawling.
Here we still take the page just now as an example. We can hand over the simulated login to Selenium to implement, and the subsequent crawling to
requests to implement, the code implementation is as follows:
from urllib.parse import urljoin
from selenium import webdriver
import requests
import time
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
browser = webdriver.Chrome()
browser.get(BASE_URL)
browser.find_element_by_css_selector('input[name="username"]').send_keys(USERNAME)
browser.find_element_by_css_selector('input[name="password"]').send_keys(PASSWORD)
browser.find_element_by_css_selector('input[type="submit"]').click()
time.sleep(10)
# get cookies from selenium
cookies = browser.get_cookies()
print('Cookies', cookies)
browser.close()
# set cookies to requests
session = requests.Session()
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
Here we use Selenium to open the Chrome browser first, then jump to the login page, and then simulate the input of the user name and password, and then click the login button. At this time, we can find that the browser prompts login success, and then successfully jumped to home page.
At this time, we can get all the cookies of the current browser by calling the get_cookies method. This is the cookies after a successful login. With these cookies, we can access other data.
Next, we declare the Session object of requests, then traverse the cookies just now and set it to the cookies of the Session object, and then take the Session object to request INDEX_URL, and then we can get the corresponding information without jumping Go to the login page.
The results are as follows:
Cookies [{
'domain': 'login2.scrape.cuiqingcai.com', 'expiry': 1589043753.553155, 'httpOnly': True, 'name': 'sessionid', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': 'rdag7ttjqhvazavpxjz31y0tmze81zur'}]
Response Status 200
Response URL https://login2.scrape.cuiqingcai.com/page/1
You can see that the simulated login and subsequent crawling were also successful. Therefore, if it is difficult to simulate the login process, we can also use Selenium or Pyppeteer to simulate the browser operation to achieve it. The purpose is to get the cookies after login. After cookies, we use these cookies to crawl Just fetch other pages.
So here we can also find that for websites based on Session + Cookies authentication, the core point of simulated login is to obtain Cookies, which can be saved or passed to other programs for continued use. It can even be said that cookies can be stored persistently or transmitted to other terminals for use. In addition, in order to improve the utilization of cookies or reduce the probability of banning, a Cookie pool can be built to achieve random access to cookies.
Case two
For case two, a JWT-based website usually adopts a front-end and back-end separation. The front-end and back-end data transmission relies on Ajax, and the login verification relies on the value of the JWT token. If the JWT token is valid, then the server You can return the data you want.
Let's first log in in the browser and observe the network request process, as shown in the figure.

Here we find that the requested URL when logging in is https://login3.scrape.cuiqingcai.com/api/login, which is requested through Ajax, and its Request Body is JSON format data instead of Form Data, and the status code is returned Is 200.
Then look at the returned result, as shown in the figure.

You can see that the returned result is a JSON format data, including a token field, the result is:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTg3ODc3OTQ2LCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNTg3ODM0NzQ2fQ.ujEXXAZcCDyIfRLs44i_jdfA3LIp5Jc74n-Wq2udCR8
This is the content of the JWT we talked about in the last lesson. The format is three-part, separated by ".".
So after this JWT, how to obtain subsequent data? Let's observe the content of the subsequent request, as shown in the figure.
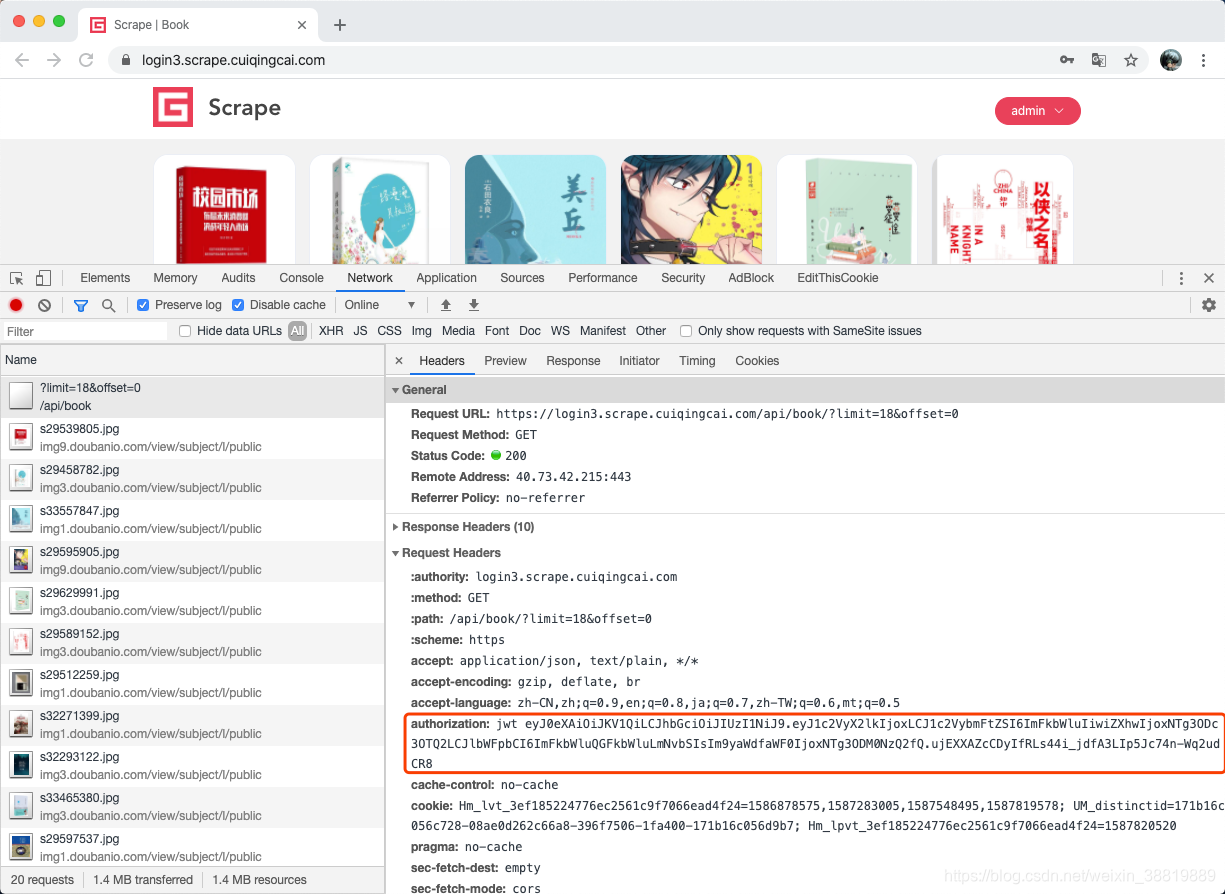
Here we can find that there is an Authorization field in the Request Headers in the subsequent Ajax request for data acquisition. The result is jwt and then the content of the JWT just now is added. The returned result is the data in JSON format.

No problem, the whole idea of simulating login is simple:
simulate request login result, bring the necessary login information, and get the result of JWT.
Subsequent requests add the Authorization field to the Request Headers, and the value is the content corresponding to the JWT.
OK, then we use the code to achieve the following:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login3.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/api/login')
INDEX_URL = urljoin(BASE_URL, '/api/book')
USERNAME = 'admin'
PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, json={
'username': USERNAME,
'password': PASSWORD
})
data = response_login.json()
print('Response JSON', data)
jwt = data.get('token')
print('JWT', jwt)
headers = {
'Authorization': f'jwt {jwt}'
}
response_index = requests.get(INDEX_URL, params={
'limit': 18,
'offset': 0
}, headers=headers)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
print('Response Data', response_index.json())
Here we also define the login interface and the interface for obtaining data, respectively LOGIN_URL and INDEX_URL, and then simulated login through a post request. Since the data submitted here is in JSON format, the json parameter is used to pass it here. Then get the JWT result contained in the returned result. In the second step, you can construct Request Headers, then set the Authorization field and pass in the JWT, so that the data can be successfully obtained.
The results are as follows:
Response JSON {
'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTg3ODc4NzkxLCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNTg3ODM1NTkxfQ.iUnu3Yhdi_a-Bupb2BLgCTUd5yHL6jgPhkBPorCPvm4'}
JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTg3ODc4NzkxLCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNTg3ODM1NTkxfQ.iUnu3Yhdi_a-Bupb2BLgCTUd5yHL6jgPhkBPorCPvm4
Response Status 200
Response URL https://login3.scrape.cuiqingcai.com/api/book/?limit=18&offset=0
Response Data {
'count': 9200, 'results': [{
'id': '27135877', 'name': '校园市场:布局未来消费群,决战年轻人市场', 'authors': ['单兴华', '李烨'], 'cover': 'https://img9.doubanio.com/view/subject/l/public/s29539805.jpg', 'score': '5.5'},
...
{
'id': '30289316', 'name': '就算這樣,還是喜歡你,笠原先生', 'authors': ['おまる'], 'cover': 'https://img3.doubanio.com/view/subject/l/public/s29875002.jpg', 'score': '7.5'}]}
As you can see, the content of the JWT was successfully output here, and the corresponding data was finally obtained, and the simulated login was successful!
Similar thinking, if we encounter a JWT certified website, we can also implement simulated login in a similar way. Of course, some pages may be more complicated and require specific analysis of specific situations.
to sum up
Above we have demonstrated the process of simulated login crawling through two examples, and we can use similar ideas to solve this situation in the future.
Code: https://github.com/Python3WebSpider/ScrapeLogin2 , https://github.com/Python3WebSpider/ScrapeLogin3 .