
It's another company that has no red envelopes! ! !
problem analysis
Through the above dialogue, can you guess all the reasons for cache penetration? Before answering, let's take a look at the specific code of the caching strategy.Cache
server IP=hash(key)% number of servers
One more sentence here, the value of the key can be specifically designed according to the specific business. For example, if I want to do load balancing, the key can be the server IP of the caller; to obtain user information, the key can be the user ID; and so on.
With the same number of servers, the above design is no problem. But you must know that the real world of programmers is miserable, and the only constant is that the business has been changing. I have no choice but to rely on technology to change this situation.
If we now have 10 servers, when we request a key of 6, the result is 4. Now we add a server and the number of servers becomes 11. When we request a server with a key of 6, the result is 5. It is not difficult to find that not only the request with key 6, but almost most of the request results have changed. This is the problem we want to solve, and this is the main problem we need to pay attention to when designing distributed cache and other similar scenarios.
Our ultimate design goal is: in the case of changes in the number of servers
- Try to increase the cache hit rate (the data transferred is the least)
- Cached data is distributed as evenly as possible
solution
Through the above analysis, we understand that the root cause of a large number of cache failures is the change in the denominator of the formula. If we keep the denominator unchanged, we can basically reduce the amount of data being moved.
Constant denominator scheme
If it is based on the formula: cache server IP=hash(key)% number of servers, we keep the denominator unchanged, which can basically improve the existing situation. Our strategy for selecting a cache server will become:
Cache server IP=hash(key)%N (N is a constant)
The value of N can be selected, and a value that satisfies the situation can be selected according to the specific business. For example: We can be sure that the number of servers will not exceed 100 in the future, and N can be set to 100. What's the problem?
The current situation can be considered that the server number is continuous, any request will hit a server, or the above is an example, our server now whether it is 10 or increased to 11, the request with the key of 6 can always get the information of a server. But now our policy formula has a denominator of 100. If the number of servers is 11 and the result of a request with a key of 20 is 20, the server numbered 20 does not exist.
The above is the problem caused by the simple hash strategy (the simple remainder hash strategy can be abstracted as a continuous array element, which is accessed according to the subscript)
In order to solve the above problems, the industry has already had a solution, that is, consistent hashing .
The consistent hash algorithm was proposed in 1997 by Karger et al. of the Massachusetts Institute of Technology in the solution of distributed Cache. The design goal is to solve the hot spot problem in the Internet. The original intention is very similar to CARP. Consistent hashing corrects the problems caused by the simple hash algorithm used by CARP, so that DHT can be truly applied in the P2P environment.
The specific features of consistent hashing, please Baidu, I will not introduce them in detail here. As for the idea of solving the problem, I need to emphasize it here:
- First obtain the hash value of the server (node) and configure it on the ring, which has 2^32 nodes.
- Use the same method to find the hash value of the key that stores the data, and map it to the same circle.
- Then start clockwise search from the location where the data is mapped, and save the data to the first server found. If the server is still not found after 2^32, it will be saved to the first server
-

What happens when a new server is added?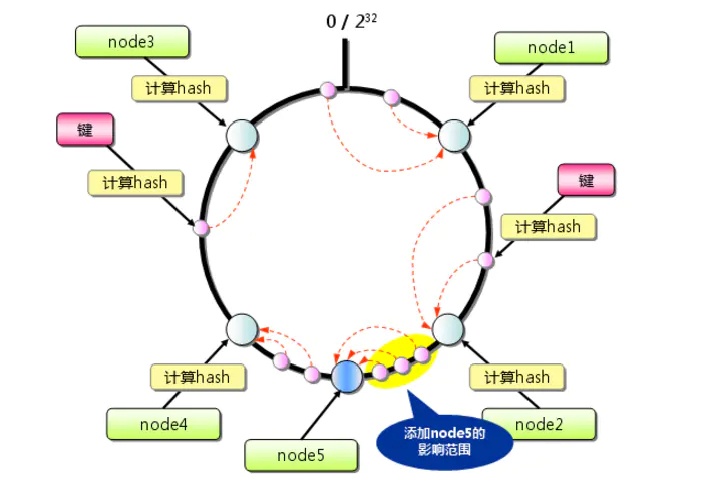
From the above figure, we can find that only the yellow part has changed. The situation for deleting a server is similar.
Through the above introduction, consistent hashing is a solution to our current problems. There are thousands of solutions, and it is better to solve the problem.
Optimization
The plans so far seem perfect, but the reality is cruel. Although the above scheme is good, there are still flaws. If we have 3 servers, the distribution of servers on the hash ring in an ideal state is as follows:
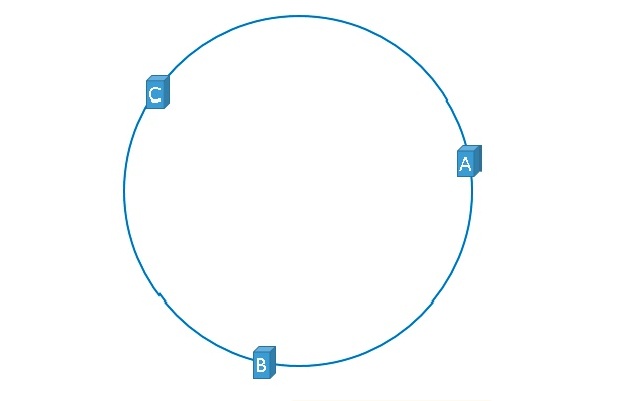
But the reality is often like this:
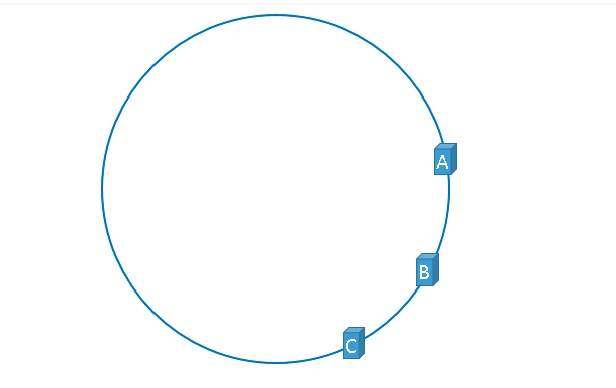
This is the so-called hash ring skew. Uneven distribution will overwhelm the server in some scenarios, and the actual production environment must pay attention to this problem. To solve this problem, virtual nodes came into being.
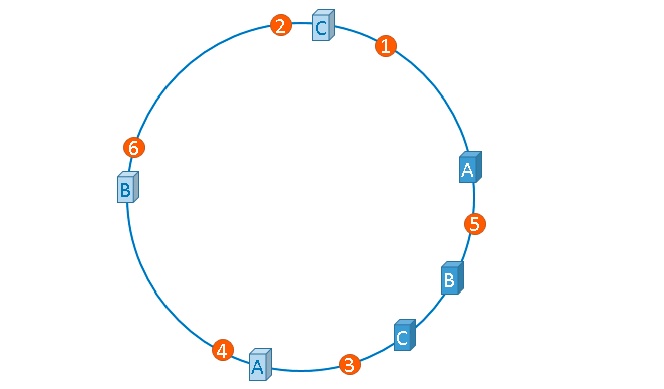
As shown in the figure above, the hash ring is no longer the actual server information, but the mapping information of the server information. For example, ServerA-1 and ServerA-2 are all mapped to server A, which is a copy of server A on the ring. This solution is to use the quantity to achieve the purpose of uniform distribution, and the memory required may be slightly larger, which can be regarded as a solution for designing space.
Extended reading
- Since it is a hash, there will be a hash conflict. What should I do if the hash values of multiple server nodes are the same? We can use a hash table addressing scheme: starting from the current position clockwise to find an empty position until an empty position is found. If it is not found, Caicai thinks whether your hash ring should be expanded, or whether your denominator parameter is too small.
- In the actual business, the operation of adding or reducing servers is much less than searching for servers, so the search speed of the data structure of our storage hash ring must be fast. Specifically, the essence is: a certain self-hash ring Value, can quickly find the first element that is not empty.
- If you have been to Niang, you will find that the number of virtual hash ring nodes introduced on the Internet is 2^32 (2 to the 32th power), which is the same. Isn't it possible except for this number? From Caicai's point of view, this number must be so large, as long as it meets our business needs and meets business data.
- The hash function used in consistent hashing must not only ensure relatively high performance, but also keep the hash value as evenly distributed as possible. This is also a requirement for an industrial-grade hash function. The hash function of the following code example is actually not The best, interested students can optimize it.
- The GetHashCode() method that comes with some languages is problematic when applied to consistent hashing, such as c#. The hash value of the same string is changed after the program restarts. All need a more stable string to int hash algorithm.
The essential problem solved by consistent hashing is that the same key can be correctly routed to the same target through the same hash function. Like our usual database sharding strategy, database sharding strategy, load balancing, data sharding, etc., it can be solved by consistent hashing.
Combining theory with practice is the essence (NetCore code)
The following code can be directly applied to the production environment of small and medium-sized projects with a little modification
//真实节点的信息 public abstract class NodeInfo { public abstract string NodeName { get; } }Node information used in the test program:
class Server : NodeInfo { public string IP { get; set; } public override string NodeName { get => IP; } }The following is the core code of consistent hashing:
/// <summary> /// 1.采用虚拟节点方式 2.节点总数可以自定义 3.每个物理节点的虚拟节点数可以自定义 /// </summary> public class ConsistentHash { //哈希环的虚拟节点信息 public class VirtualNode { public string VirtualNodeName { get; set; } public NodeInfo Node { get; set; } }
//添加元素 删除元素时候的锁,来保证线程安全,或者采用读写锁也可以
private readonly object objLock = new object();
//虚拟环节点的总数量,默认为100
int ringNodeCount;
//每个物理节点对应的虚拟节点数量
int virtualNodeNumber;
//哈希环,这里用数组来存储
public VirtualNode[] nodes = null;
public ConsistentHash(int _ringNodeCount = 100, int _virtualNodeNumber = 3)
{
if (_ringNodeCount <= 0 || _virtualNodeNumber <= 0)
{
throw new Exception("_ringNodeCount和_virtualNodeNumber 必须大于0");
}
this.ringNodeCount = _ringNodeCount;
this.virtualNodeNumber = _virtualNodeNumber;
nodes = new VirtualNode[_ringNodeCount];
}
//根据一致性哈希key 获取node信息,查找操作请业务方自行处理超时问题,因为多线程环境下,环的node可能全被清除
public NodeInfo GetNode(string key)
{
var ringStartIndex = Math.Abs(GetKeyHashCode(key) % ringNodeCount);
var vNode = FindNodeFromIndex(ringStartIndex);
return vNode == null ? null : vNode.Node;
}
//虚拟环添加一个物理节点
public void AddNode(NodeInfo newNode)
{
var nodeName = newNode.NodeName;
int virtualNodeIndex = 0;
lock (objLock)
{
//把物理节点转化为虚拟节点
while (virtualNodeIndex < virtualNodeNumber)
{
var vNodeName = $"{nodeName}#{virtualNodeIndex}";
var findStartIndex = Math.Abs(GetKeyHashCode(vNodeName) % ringNodeCount);
var emptyIndex = FindEmptyNodeFromIndex(findStartIndex);
if (emptyIndex < 0)
{
// 已经超出设置的最大节点数
break;
}
nodes[emptyIndex] = new VirtualNode() { VirtualNodeName = vNodeName, Node = newNode };
virtualNodeIndex++;
}
}
}
//删除一个虚拟节点
public void RemoveNode(NodeInfo node)
{
var nodeName = node.NodeName;
int virtualNodeIndex = 0;
List<string> lstRemoveNodeName = new List<string>();
while (virtualNodeIndex < virtualNodeNumber)
{
lstRemoveNodeName.Add($"{nodeName}#{virtualNodeIndex}");
virtualNodeIndex++;
}
//从索引为0的位置循环一遍,把所有的虚拟节点都删除
int startFindIndex = 0;
lock (objLock)
{
while (startFindIndex < nodes.Length)
{
if (nodes[startFindIndex] != null && lstRemoveNodeName.Contains(nodes[startFindIndex].VirtualNodeName))
{
nodes[startFindIndex] = null;
}
startFindIndex++;
}
}
}
//哈希环获取哈希值的方法,因为系统自带的gethashcode,重启服务就变了
protected virtual int GetKeyHashCode(string key)
{
var sh = new SHA1Managed();
byte[] data = sh.ComputeHash(Encoding.Unicode.GetBytes(key));
return BitConverter.ToInt32(data, 0);
}
#region 私有方法
//从虚拟环的某个位置查找第一个node
private VirtualNode FindNodeFromIndex(int startIndex)
{
if (nodes == null || nodes.Length <= 0)
{
return null;
}
VirtualNode node = null;
while (node == null)
{
startIndex = GetNextIndex(startIndex);
node = nodes[startIndex];
}
return node;
}
//从虚拟环的某个位置开始查找空位置
private int FindEmptyNodeFromIndex(int startIndex)
{
while (true)
{
if (nodes[startIndex] == null)
{
return startIndex;
}
var nextIndex = GetNextIndex(startIndex);
//如果索引回到原地,说明找了一圈,虚拟环节点已经满了,不会添加
if (nextIndex == startIndex)
{
return -1;
}
startIndex = nextIndex;
}
}
//获取一个位置的下一个位置索引
private int GetNextIndex(int preIndex)
{
int nextIndex = 0;
//如果查找的位置到了环的末尾,则从0位置开始查找
if (preIndex != nodes.Length - 1)
{
nextIndex = preIndex + 1;
}
return nextIndex;
}
#endregion
}
#### 测试生成的节点 ConsistentHash h = new ConsistentHash(200, 5);
h.AddNode(new Server() { IP = "192.168.1.1" });
h.AddNode(new Server() { IP = "192.168.1.2" });
h.AddNode(new Server() { IP = "192.168.1.3" });
h.AddNode(new Server() { IP = "192.168.1.4" });
h.AddNode(new Server() { IP = "192.168.1.5" });
for (int i = 0; i < h.nodes.Length; i++)
{
if (h.nodes[i] != null)
{
Console.WriteLine($"{i}===={h.nodes[i].VirtualNodeName}");
}
}输出结果(还算比较均匀):2====192.168.1.3#4
10====192.168.1.1#0
15====192.168.1.3#3
24====192.168.1.2#2
29====192.168.1.3#2
33====192.168.1.4#4
64====192.168.1.5#1
73====192.168.1.4#3
75====192.168.1.2#0
77====192.168.1.1#3
85====192.168.1.1#4
88====192.168.1.5#4
117====192.168.1.4#1
118====192.168.1.2#4
137====192.168.1.1#1
152====192.168.1.2#1
157====192.168.1.5#2
158====192.168.1.2#3
159====192.168.1.3#0
162====192.168.1.5#0
165====192.168.1.1#2
166====192.168.1.3#1
177====192.168.1.5#3
185====192.168.1.4#0
196====192.168.1.4#2
#### 测试一下性能 Stopwatch w = new Stopwatch();
w.Start();
for (int i = 0; i < 100000; i++)
{
var aaa = h.GetNode("test1");
}
w.Stop();
Console.WriteLine(w.ElapsedMilliseconds);输出结果(调用10万次耗时657毫秒):657
#### 写在最后
以上代码实有优化空间
1. 哈希函数
2. 很多for循环的临时变量
有兴趣优化的同学可以留言哦!!
>**更多精彩文章**
>- [分布式大并发系列](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&album_id=1342955119549267969&__biz=MzIwNTc3OTAxOA==#wechat_redirect)
>- [架构设计系列](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&album_id=1342959003139227648&__biz=MzIwNTc3OTAxOA==#wechat_redirect)
>- [趣学算法和数据结构系列](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&album_id=1342962375443529728&__biz=MzIwNTc3OTAxOA==#wechat_redirect)
>- [设计模式系列](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&album_id=1342964237798391808&__biz=MzIwNTc3OTAxOA==#wechat_redirect)
