1 Overview of Unsupervised Learning
We all know that monitoring data is very valuable. Generally speaking, it is easy for us to obtain data, but it is more difficult to obtain labels. Therefore, unsupervised learning is critical in machine learning. How to make good use of a large amount of unsupervised data is critical to the cold start of the business and continuous iterative operation.
Unsupervised learning is roughly divided into
- Turn the complexity into simplicity. Including
- Clustering, combining unsupervised data into clusters. The data in the cluster is similar, but the data in the cluster is not similar.
- Dimensionality reduction, feature extraction. Extract features for unsupervised data, such as images and text. Such as PCA, Auto-Encoder, MF
- Out of nothing, mainly all kinds of generative models.
This article mainly talks about unsupervised linear models. Including clustering, PCA, MF, etc.
2 Clustering
2.1 Cluster types
Clustering is very important in actual business, especially when the business is cold-started. It can be used for intention category mining, knowledge base production, topic mining, etc. It can also be combined with the marking data to realize the noise discovery of the marking data. There are many clustering algorithms, as follows
- Divide clustering k-means, k-medoids, k-modes, k-medians, kernel k-means
- Hierarchically class Agglomerative, divisive, BIRCH, ROCK, Chameleon, HAC
- Density clustering DBSCAN, OPTICS, HDBScan
- Grid clustering STING
- Model clustering GMM
- Graph clustering Spectral Clustering (spectral clustering)
2.2 Clustering algorithm steps (k-means, DBScan)
The k-means steps are:
- Randomly select k values as the initial mean vector (cold start)
- Put the sample into the nearest mean vector cluster
- After the cluster is constructed, recalculate the mean vector
- Iteration second step
- Until the clusters of the two iterations are exactly the same, stop
DBScan steps:
First calculate all possible cores based on neighborhood parameters, minimum distance, and minimum cluster size
Select one of the cores, and remove all the samples with the density of the calculator from the core set.
Continue to perform the second step in the remaining core set
If the core set is empty, or a new cluster cannot be generated, the end
2.3 Cluster evaluation index
The clustering evaluation indicators are divided into the following, sklearn has implemented them, just call them directly
- No validation set, DBI, DB index
- There are validation set, rand coefficient, NMI mutual information, homogeneity, etc.
3 PCA principal component analysis
PCA (Principe Component Analysis) uses the idea of dimensionality reduction to convert multiple indicators into a few indicators. For example, face recognition is transformed into recognizing eyes, nose, mouth, etc. This is the meaning of principal component analysis.
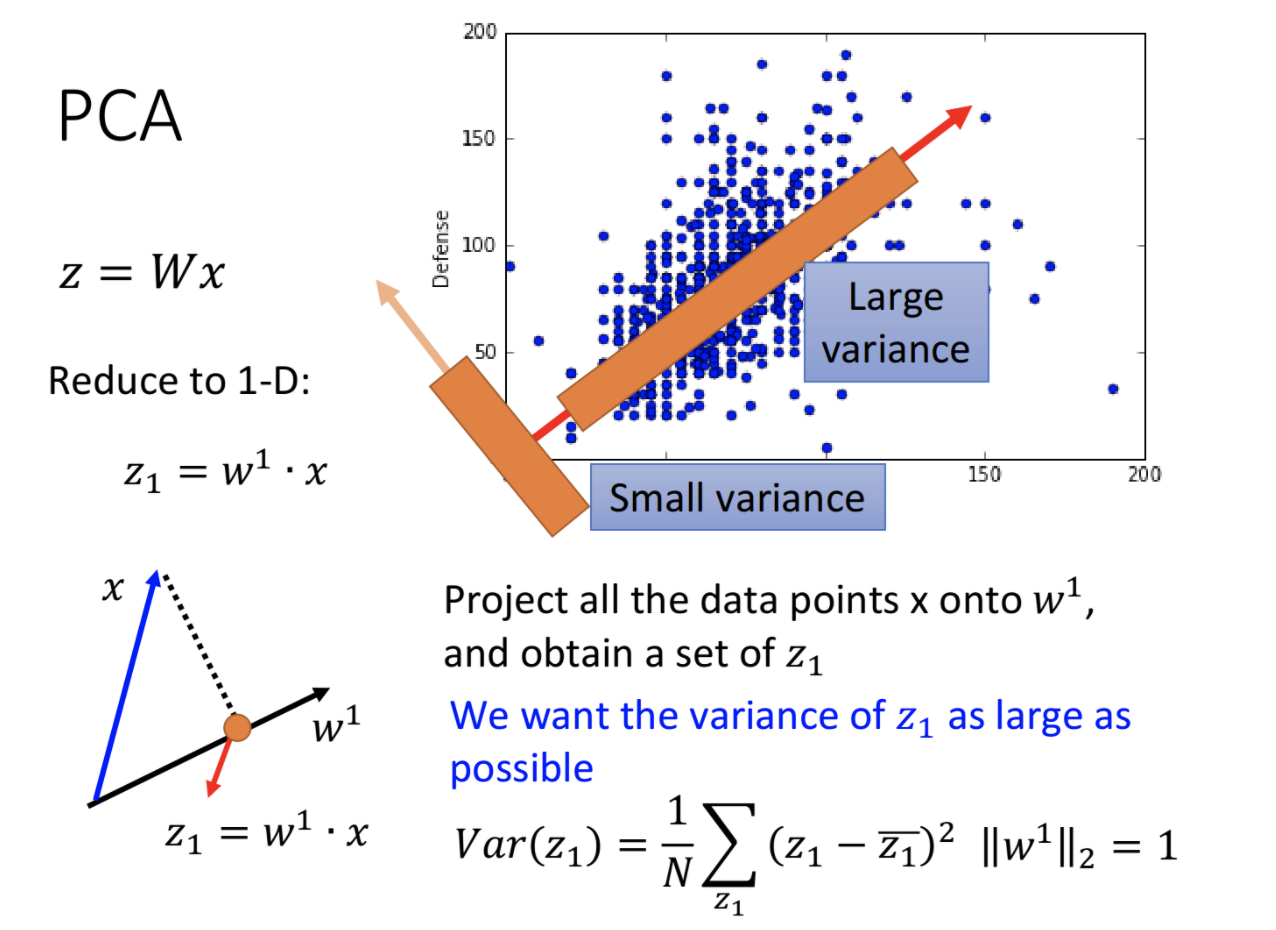
PCA is a linear transformation that transforms data into a new coordinate system. The first largest variance of any data projection is on the first coordinate (first principal component), and the second largest variance is on the second coordinate (first principal component). Two principal components), and so on. The idea of PCA is to reduce the dimensionality while retaining the features that contribute to the data variance. These features are the main features of the data, called principal components.
The following figure shows PCA in one-dimensional space. The direction with the largest variance of the data projection is the first principal component, which is the most important feature.
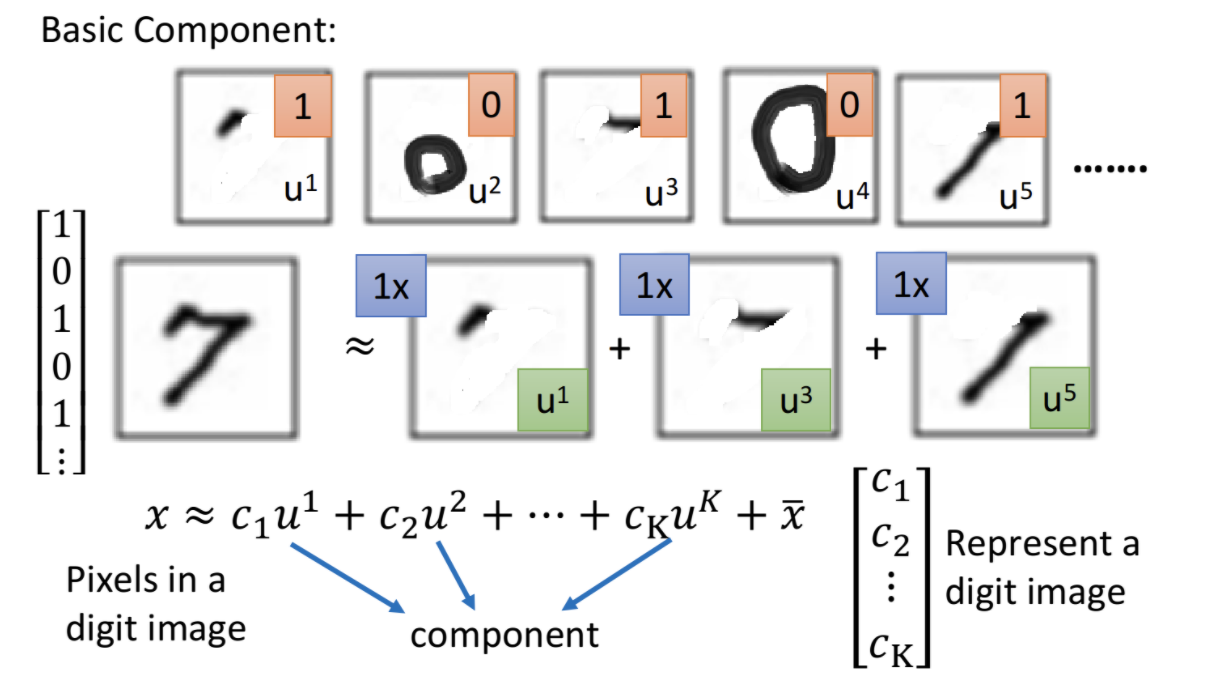
The main characteristics of the data can be found through PCA. The number 7 can be found in the following figure, which is composed of three main characteristics.
The disadvantages of PCA are
- Unsupervised, less accurate. LDA based on supervised works better, but supervised data is needed.
- In the linear model, the captured features are still too shallow. Compared with Auto-Encoder, which can be based on a deep model, the feature extraction capability is much weaker.
4 MF matrix factorization
Matrix decomposition can also get basic components and features. Matrix decomposition can be realized by using SVD. The following are the features of handwriting recognition extracted by MF. As you can see, the basic strokes can be extracted.
