I have studied git many times in succession, but forgot many times. In the end, you will only upload and push your changes on the idea. Recently I watched another one that talked about git. It ’s not bad. At least I have n’t forgotten it after many days, so I specially recorded it.
Prequel
Let's talk nonsense first (just want to learn commands, it is recommended to start from the biography)
Linus created open source Linux in 1991. Since then, the Linux system has continued to develop and has become the largest server system software.
Although Linus created Linux, the growth of Linux relies on the participation of enthusiastic volunteers from all over the world. So many people are writing code for Linux around the world. How is the Linux code managed?
Before 2002, volunteers from all over the world sent the source code files to Linus by diff, and then Linus himself merged the code manually!
You might think, why doesn't Linus put Linux code in the version control system? Are there free version control systems such as CVS and SVN? Because Linus is firmly opposed to CVS and SVN, these centralized version control systems are not only slow, but must also be connected to the Internet before they can be used. There are some commercial version control systems. Although they are easier to use than CVS and SVN, they are paid and do not match the spirit of Linux's open source.
However, by 2002, the Linux system had been developed for ten years. The size of the code base made it difficult for Linus to continue to manage it manually. The brothers in the community also expressed strong dissatisfaction with this method, so Linus chose a business BitKeeper's version control system, BitKeeper's owner BitMover, out of a humanitarian spirit, authorized the Linux community to use this version control system for free.
The good situation of stability and unity was broken in 2005, because the Linux community gathered people, and it was inevitable that some of the Liangshan heroes' habits were contaminated. Andrew, who developed Samba, tried to crack BitKeeper's protocol (it's not just him), and was discovered by BitMover (the monitoring work was done well!), So BitMover was furious and wanted to take back the free use rights of the Linux community.
Linus can apologize to BitMover and promise to strictly discipline his brethren in the future. Well, this is impossible. The actual situation is this:
Linus spent two weeks writing a distributed version control system in C by himself, this is it! Within a month, the source code of the Linux system has been managed by Git! How is cattle defined? Everyone can appreciate it.
Git quickly became the most popular distributed version control system. Especially in 2008, the GitHub website went online. It provides free Git storage for open source projects. Numerous open source projects began to migrate to GitHub, including jQuery, PHP, Ruby and so on.
History is so accidental, if it was not for BitMover's threat to the Linux community, we may not have free and super easy to use Git now.
Principle 1. git principle
First, git works based on version snapshots.
Git is more like viewing data as a set of snapshots of a small file system. Every time you submit an update or save the project state in Git, it mainly takes a snapshot of all the files at that time and saves the index of the snapshot. For efficiency, if the file is not modified, Git will no longer re-store the file, but only keep a link to the previously stored file. Git treats data more like a snapshot stream.

Principle 2. git guarantees data integrity
All data in Git is calculated with a checksum before storage and then referenced with the checksum. This function is built at the bottom of Git and is an integral part of Git's philosophy. If you lose information or damage files during the transfer process, Git can find it.
The mechanism that Git uses to calculate the checksum is called SHA-1 hash (hash). This is a string of 40 hexadecimal characters (0-9 and af), calculated based on the content of the file in Git or the directory structure. The SHA-1 hash looks like this:
24b9da6552252987aa493b52f8696cd6d3b00373
There are many cases of using this kind of hash value in Git, you will often see this kind of hash value. In fact, the information stored in the Git database is indexed by the hash value of the file content, not the file name.
Principle 3. The version is missing
The Git operations you perform almost only add data to the Git database. It is difficult for Git to perform any irreversible operation or to clear the data in any way. Like other version control tools, it is possible to lose or mess up the modified content when the update is not submitted; but once you submit the snapshot to Git, it is difficult to lose data, especially if you regularly push the database to other warehouses.
This makes our use of Git a process of peace of mind, because we know that we can do all kinds of attempts without risk of messing things up.
Intermediate – very important concepts: repository (warehouse), work area, temporary storage area, branch area

1. Version library (warehouse)
The repository is also known as a repository, and the English name is repository. You can simply understand it as a directory. All files in this directory can be managed by Git. Git can track each file's modification and deletion so that you can track it at any time History, or it can be "restored" at some point in the future.
2. Work area
Location where files to be managed are stored
3. Temporary storage area
The operation of adding the git add command or git rm command in the repository to the temporary storage area is recorded in the temporary storage area
4. Branch area
The branch area in the repository is where the final version information is saved. The git commit command submits the operations recorded in the temporary area to the branch.
Multiple branches can be configured. If not specified, the default is the master branch, and a head pointer points to the master. The latest location of the branch
1. Create a repository
First, if you want your files to be managed by git, you must declare your folder as a git folder. The command used is:
git init
After the command is executed, there will be an additional .git directory under this directory. This directory is used by Git to track and manage the repository. Do not modify it manually.
Git is a version management tool that many people can use, so how to let others know that you are you? We can do some configuration
First set user.name, use git config --global suer.name "the name you want to set"
git config --global user.name "zhangsan"
Sometimes the name will be repeated, so you have to set up an email. Just use git config --global user.email mailbox.
git config --global user.email zhangsan@qq.com
Because this is not a discussion of git related configuration, so just give a brief introduction.
View your own configuration information using git config --list
git config --list
2. Work area and warehouse
The folder managed by git can be divided into three areas: work area, temporary storage area, and branch area.
The work area can be understood as the area where the file is modified.
The branch area can be understood as: the area of the submitted file (commit successful file).
The temporary storage area is between the two, which can be understood as the transition area between the two. Can be submitted to the branch area, can also be withdrawn to the work area.

3. New documents and add and commit
First, let's write a file at will, called text01.txt. We can use a command to view the changes in the folder managed by git.
git status
This is an explanation of the output.

Because we added the text01.txt file, git prompts us that there is a file that is not tracked (that is, this file cannot be submitted to the branch area). We can use the git add file name command to track the file, and at the same time, the file will be submitted to the temporary storage area.
git add text01.txt
At the same time, let's check the status of git again
git status
The second line of text on the image below was wrong, should be content no uncommitted

We've added over documents, but also submitted to the staging area, then as long as he submitted to the branch area can be.
Use git commit -m related information. The relevant information is the remarks of this submission.
-m后面输入的是本次提交的说明,可以输入任意内容
本例中只经历了一个修改就提交了,其实完全可以 多个修改后一次提交
git commit -m "add file test.txt"
Check the repository status again
git status

When drawing, the repository now becomes the following state:

4. Modify and compare files
First modify test01.txt. Check the status of the repository after modification
git status

The state of the drawing library is as follows:

At this time, we can view the modification information of the file. Use the git diff file name command.
git diff test.txt
On my computer,

add the file to the staging area as shown below .
git add test01.txt
View status
git status
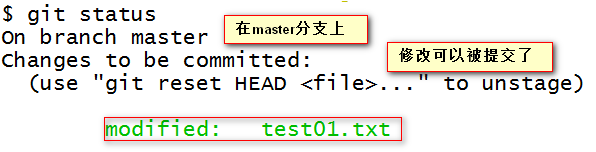
The state of the image's version library is as follows:

At this time, submit the modification to the branch.
git commit -m "change Git to git"
Check status again
git status

The image library status is as follows

5. View historical versions
Modify test01.txt again. Add files to the temporary storage area after modification.
git add text01.txt
Then submit the file to the branch.
git commit -m "...some msg..."
At this point, multiple files have been submitted to the branch area, you can use the git log command to view the historical version
git log

6. Roll back the version
One day, while being modified, I suddenly found that I made a mistake and needed to go back to a previous commit. This operation is called rollback. You can use the following command:
git reset --hard HEAD^
In Git, HEAD is used to indicate the current version. The previous version is HEAD ^, and the last version is HEAD ^^. Of course, writing 100 ^ to the top 100 versions is easier to count, so it is written as HEAD ~ 100.
If you are too lazy to count the previous version, you can also roll back to the specified version number.
git reset --hard 5527510751b4303390bb4f321bfa8b7f997cbfd0
You can knock on the first few if you are too lazy.
git reset --hard 55275
Roll back to the previous version and use git log again to view the historical version.
git log
When using this command, you will find that only the current version and the previous version are displayed; the versions after the current version cannot be viewed.
So does it mean that we can only roll back and not back?
Of course not.
Use the git reflog command to view all versions.
git reflog
With the git reset command, you can easily roll back to any version.
7. Undo the modification
Back to the original. We revised the file again, but found that the modification was wrong and wanted to undo this modification. You can use git checkout-file name. This command will restore the workspace file to the status of the latest add or commit before.
git checkout -- test.txt
We continue to modify the file and add the file to the temporary storage area (not yet submitted to the branch area). Suddenly, we found that it was wrong again ... It is not easy to use the git checkout command alone. At this time, we can cooperate with other commands.
First, we can roll back to the current version (when rolling back to other versions, the files in the staging area will disappear, so that the files in the staging area are cleared)
git reset HEAD test.txt
Then use the git checkout command to undo.
git checkout -- test.txt
This time, we continue to modify the file, add and commit the file. Then I found that it was wrong again ... I can undo this modification by rolling back. However, even if you roll back, you can still see this commit using git reflog. Therefore, as long as it is submitted to the git branch area, it is impossible to delete.
8. Delete files
We found a file useless and deleted it.
rm test01.txt
Of course, it can also be deleted manually. Check the repository status after deleting
git status

Add the deleted files to the temporary storage area. Use the git rm file name command.
git rm test01.txt
Of course, you can also use the git add command. View the repository.
git status
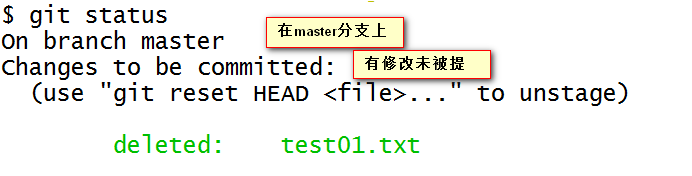
Submit it to the branch.
9. What does git manage and track
git tracks and manages changes, not files.
For example, first, we add a new line of text to test01.txt: 111111.
Then add the file to the staging area.
Then add a regret file to test01.txt: 222222.
Then commit to the branch.
Then check the status of the repository, you will find that 222222 has not been submitted.
10. Command summary

11. Specify the version tag name by tag
The version in git has a version number, and the submission and rollback of the code are based on the version number, but the version number in git is a random string, which is not easy to remember. At this time, you can use the labeling mechanism for a certain submission Add tags to facilitate future search. After the label is enlarged, all the positions where the version number needs to be used can be replaced with the corresponding label. The label can also be understood as an alias.
First, label the current commit of the current branch.
git tag v1.0
You can also view all tags
git tag
You can also label the previously submitted version
git tag v0.9 f52c663
You can also create labels with instructions. Use -a to specify the label name, and -m to specify the description text.
git tag -a v0.1 -m "version 0.1 released " 1094adb
You can view a tag information by the following command:
git show v0.1
If the label is wrong, you can delete it
git tag -d v0.1
If you want to push tags to a remote, use git push origin tagName.
git push origin v1.0
You can also push all the local tags that have not been pushed to the remote all at once.
git push origin --tags
However, if the tag has been pushed to the remote, it will be troublesome to delete it. First remove the local label
git tag -d v0.9
Then delete from remote
git push origin :refs/tags/v0.9
12. Specify git to ignore some content
You can configure the .gitIgnore file in the warehouse. Which files are configured in it does not require git management. When git processes this warehouse, it will automatically ignore the contents of the declaration.
.gitIgnore file format:
1) Spaces do not match any file, can be used as a separator, and can be escaped with a backslash
2) Lines beginning with "#" will be ignored by Git. That is, the file identification comment starting with # can be escaped with a backslash.
3) Standard glob pattern matching can be used. The so-called glob pattern refers to the simplified regular expression used by the shell.
4) The beginning of a slash "/" indicates a directory; the "/" ending pattern only matches the folder and the contents of the folder path, but does not match the file; "/" The starting pattern matches the project and the directory; if A pattern does not contain a slash, it matches the content relative to the current .gitignore file path, if the pattern is not in the .gitignore file, it is relative to the project root directory.
5) Use asterisk " " to match multiple characters, that is, to match multiple arbitrary characters; use two asterisks " **" to match any intermediate directory, such as a/**/za / z, a / b / z or a / b / c / z etc.
6) Use a question mark "?" To match a single character, that is, to match an arbitrary character;
7) Use square brackets "[]" to contain a single character matching list, that is, to match any one of the characters listed in square brackets. For example, [abc] means to match either an a, a b, or a c; if a dash is used to separate two characters in square brackets, it means that all characters within these two characters can be matched. For example, [0-9] means to match all digits from 0 to 9, and [az] means to match any lowercase letter).
8) The exclamation mark "!" Means that the matched files or directories are not ignored (tracked), that is, files or directories other than the specified mode are to be ignored. You can add an exclamation point (!) In front of the mode to reverse. Special attention is needed: if the parent directory of the file has been excluded by the previous rule, then the "!" Rule will not work for this file. In other words, the pattern at the beginning of "!" Means negative, the file will be included again. If the parent directory of the file is excluded, the use of "!" Will not be included again. You can use backslashes to escape.
Need to remember: git rules are matched from top to bottom for the .ignore configuration file, which means that if the previous rule matches a larger range, the following rule will not take effect;
because of markdown syntax problems, some symbols May display errors, so attach the image version below:

Example:
# means this is a comment and will be ignored by Git
. A means ignore all files ending in .a
! Lib.a means except lib.a
/ TODO means only ignore TODO files in the project root directory, excluding subdir / TODO
build / means ignore all files in the build / directory and filter the entire build folder;
doc / .txt means ignore doc / notes.txt but not doc / server / arch.txt
bin /: means to ignore the bin folder under the current path, all contents in this folder will be ignored, not to ignore the bin file
/ bin: means to ignore the bin file under the root directory
/ .c: means to ignore cat.c, not Ignore build / cat.c
debug / .obj: Ignore debug / io.obj, do not ignore debug / common / io.obj and tools / debug / io.obj
/ foo: Ignore / foo, a / foo, a / b / foo, etc.
a / / b: means to ignore a / b, a / x / b, a / x / y / b,
etc./bin/run.sh means not to ignore the run.sh file in the bin directory
* .log : Means to ignore all .log files
config.php: means to ignore the config.php file in the current path
/ mtk / means to filter the entire folder
* .zip means to filter all .zip files
/mtk/do.c means to filter a specific file
The filtered files will not appear in the git repository (gitlab or github), of course, there are still in the local library, but they will not be uploaded when they are pushed.
It should be noted, adding gitignore also specify which files to version management, as follows:
! .Zip
/mtk/one.txt!
The only difference is the beginning of the rule more than an exclamation point, Git will meet such rules The file is added to the version management. Why are there two kinds of rules?
Imagine a scenario: if we only need to manage the one.txt file in the / mtk / directory, and no other files in this directory need to be managed, then the .gitignore rule should be written as:
/ mtk /
! /Mtk/one.txt
Assuming that we only have filtering rules without adding rules, then we need to write all files except one.txt in the / mtk / directory!
Note that the above / mtk / * cannot be written as / mtk /, otherwise the parent directory is excluded by the previous rules, although the one.txt file is added! Filter rules will not take effect!
There are some rules as follows:
fd1 / *
Description: Ignore the entire contents of the directory fd1; Note that whether it is the / fd1 / directory under the root directory or a subdirectory / child / fd1 / directory, it will be ignored;
/ fd1 / *
Description: Ignore the entire contents of the / fd1 / directory under the root directory
/ *
! .gitignore
! / fw /
/ fw / *
! / fw / bin /
! / fw / sf /
Description: Ignore everything, but not .gitignore files, / fw / bin / and / fw in the root directory / sf / directory; mainly use the! rule on the parent directory of bin / so that it is not excluded.
Because of the markdown syntax problem, some symbols may display errors, so attach the image version below:

13. Summary
This is the end of git local management. For local management, these commands are basically enough
. 1. Distinguish the work area, temporary storage area and branch area
. 2. add is submitted to the work area, commit is submitted to the branch area. Once submitted to the branch area, it can never be deleted. Even if you roll back to the previous version, you can still find the submitted information.
3. git log to view the information of all previous versions of the current version, and git reflog to view the information of all versions.
4. When you git commit, you must write the information behind -m
5. Actually, I forgot to say, if you find it troublesome, you can use git add * to submit all files, or git add / src to submit all files in the root directory src. The add command is still very flexible.
6. It is not necessary to memorize the content specified by git. I know that there is such a thing. Just check it when you use it.
