table of Contents
development path
1.0 stage
Common files are stored in two ways: disk, memory.
It related to two common questions: addressing bandwidth.
Disk addressing milliseconds (ms) level, the bandwidth xx G
memory addressing in nanoseconds (ns) level of bandwidth: a large
disk and memory, in terms of addressing, times slower 10w
Disk has a track, sector. A sector 512byte, capacity is small, poses a problem, if the file is relatively large when the need to keep access to the sector, constantly addressing, the corresponding index file will be very large.
Memory storage, data not persistent.
4k alignment: the operating system, regardless of how large the file is read, the first I / O, a minimum size of 4k. It may be set to be larger than 4k.
2.0 stage
Relational database appears:
database smallest data storage unit called page (oracle of Block), usually 8K, 4k set to an integer multiple of, the operating system in order to meet a purpose I / O size.
In the database, the data files can be, seen to split from the page number of 0-N.
Index: Data after normal data page, and then open a new space, where the Data page information storage information of each page corresponding to the index field, and its associated index of normal data.
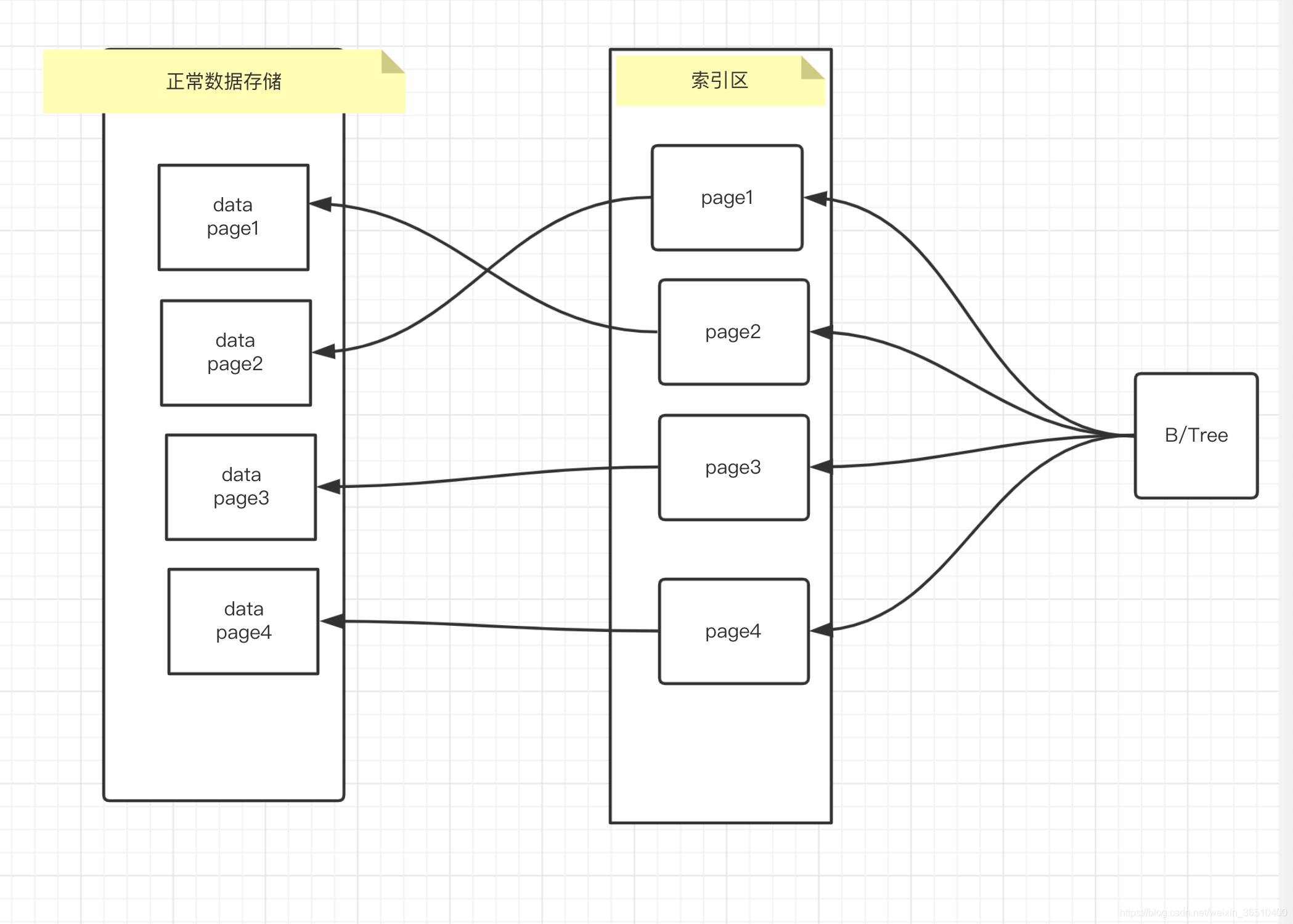
When a query by B / tree index information, an index of a hit, as PAGE1, can take advantage of data page2 metadata is found, loaded into the memory data page2.
When the amount of data is very large, the performance will be donated deletion of data reduced query performance, if only a few queries, query performance does not decrease obviously, but if the high concurrent queries, restricted to read I / O's capacity, will cause a lot of page read line blockage, performance will drop obvious. We hope to be able to speed faster.
3.0 stage
Cache: memcached, redis
Redis
Schematic:
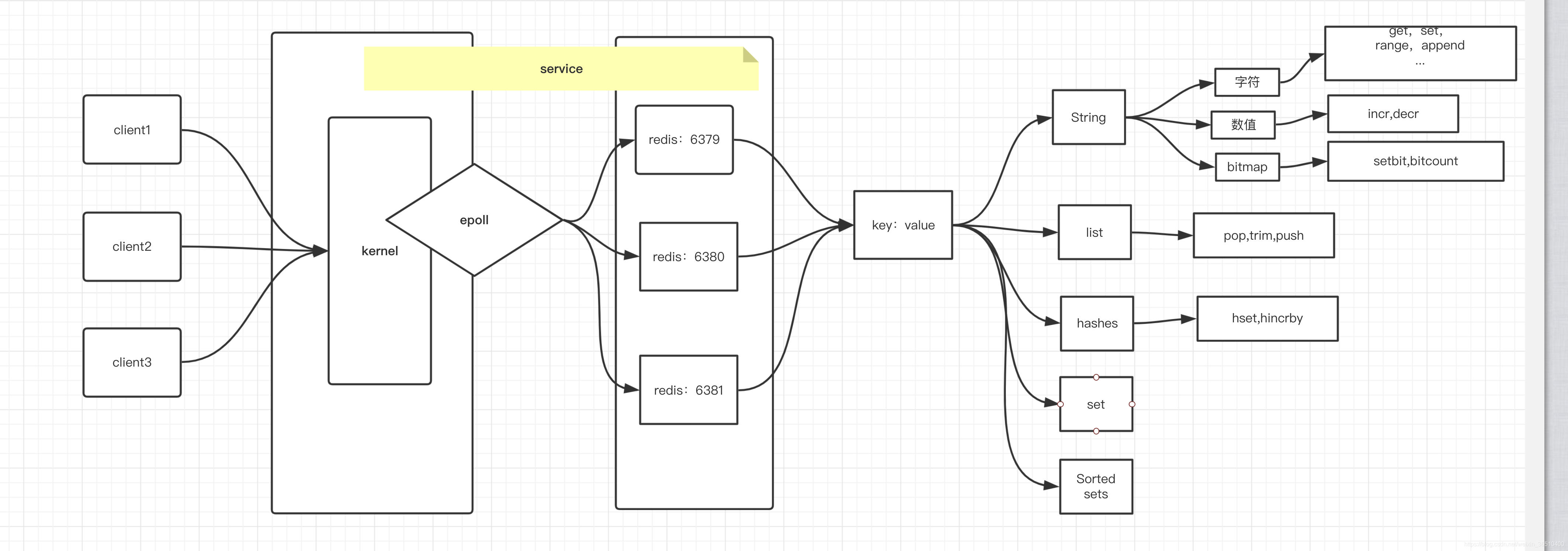
After the client establishes a connection with Redis, by epoll multiplexing process to achieve a single high throughput,
Binary Security

Storing a same value: when using the shell when utf-8, the Redis 3 bytes is stored, when the shell encoded into GBK, again storage "in", the Redis stored in 2 bytes.
For Redis binary security to read the byte stream data, rather than character stream.
Affairs

As shown, client1 client2 and are connected to a Redis instance. client1 and client2 both transactional operations, client1 update key, delete key client2 query key again.
We all know that Redis for this business process, a single process, and that there are now two transactions, Redis is how to achieve it?
A transaction from start to execution, there are the following three steps: 1. Begin a transaction, 2 commands into the team, 3 to perform a transaction...
Redis received from the first transaction open command MULTI, each transaction would maintain a buffer queue commands, execute the command until the end Exec:

So two transactions, the final execution order, to see which arrives first transaction exec command.
important point:Redis transaction, and transactional relational database is a little different. It is atomic database transaction, if any of a plurality of command failures, will be rolled back. Redis transaction, when to perform a row, if an error occurs, the command has been executed will not be rolled back, while subsequent commands will still execute down, so Redis transaction is not atomic operations can be understood as the pack a bunch of commands executed.
Expiration eliminated
There are two main expired elimination mechanism: passive, active
- Passive (lazy man): When a client initiates a key request of, Redis will detect whether the current this key has expired. This has an obvious drawbacks, if not decades, a key client access, then this key will persist for decades without being cleaned.
- Active: Redis performed 10 times per second:
. A key 20 for randomly detecting expiration
b delete key has expired.
C 20 key expired if greater than 25%, the above process is repeatedly performed. - AOF file handling expired
in order to obtain the correct behavior without sacrificing consistency, when a key expires, DEL command is written AOF sent salves
Endurance of
There are two ways Redis persistence:
- RDB (total amount of data)
- AOF of (increment data)
RDB:
Well understood, RDB way, that is, all data in the current Redis cache, all written to disk. The question is, how to write it?
The introduction of a question: Suppose the current time node in the morning 10: 00, Redis has recorded a = 3, b = 4, and now need to put this demand is be persistent.
- A program: Redis main thread blocked, rejected all external response, etc. Once the data is written to disk, and then receives an external request.
- Option Two: Redis is not blocking the main line, continue to respond to external read / write requests to open a sub-thread is responsible for writing data to disk
From the response speed of response and throughput, the second method is certainly a priority, but if you choose Option II, will bring a problem if the child thread needs to be written to disk 30min, while the main thread in this 30min inside, will be key = a, and the data key = b, respectively, 5 times, 8 times the update, then that within 30min, really started when the child thread persistence time, this time to get the value, which may be 5/8 any update of the previous value. That is: the key = a value may be stored in the second modification is a result of the time 10: 17, key = b is stored in the result of the seventh modification, the time 10:26. RDB data file at this time is not the time of 10:00.
So Redis RDB is how to achieve it?
First need to introduce a few concepts:
- Virtual memory address
- Physical memory address
- fork
- copy on write
We all know that each thread has its own thread space to Linux / Uinx system, for example, export command that allows a child process the parent process data visible, that the child thread to hold the parent object references in each thread space, each thread has its own virtual memory addresses are mapped to physical memory addresses by the address os:
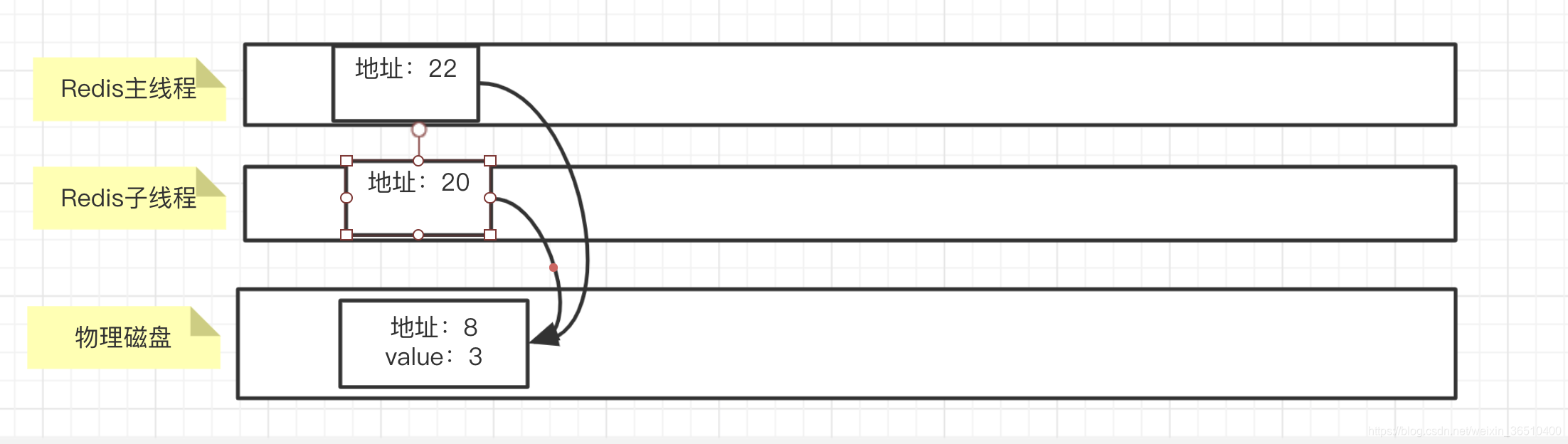
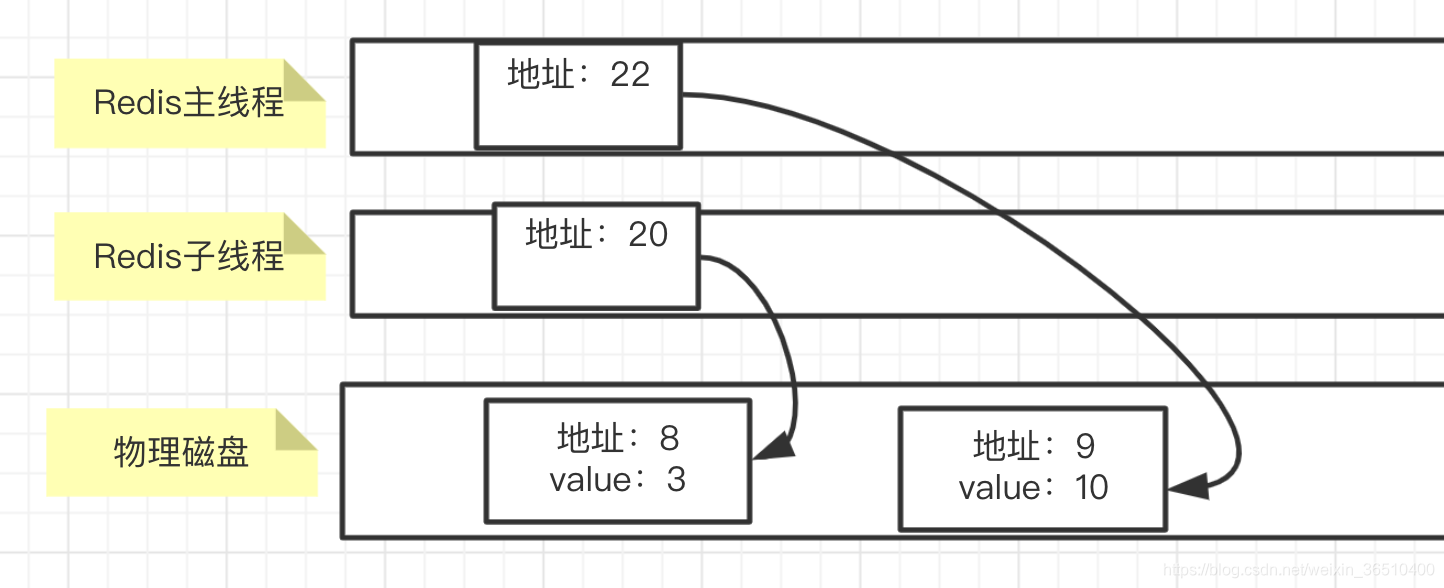
when the child thread by fork Redis way out, we have a complete backup of data held in a certain period of time, the main process. You certainly have to ask, the main thread is still responding to client read and write requests, if a copy of the data, the disk has not been written before, the main thread will be the data has been modified, and that the child thread to get through the memory mapped value, whether it is data after revision? This time they copy on write rafts handy. As the name suggests, write, copy, that is, when the need to modify the data, the data will be copied. FIG above example, when the main thread at a time, need physical memory 10 into data of 8, the final address mapping relationship as follows:
corresponding to the command takes two Redis:
- save, blocking, corresponding to a program
- bgsave, non-blocking, corresponding to the two methods
Meanwhile, the configuration item redis.conf save, actually corresponds to bgsave command takes two parameters: the time interval, changing the number of rows

AOF
Redis will write to the log file, append only, stop logs were added.
Imagine the following question:
there is now a Xiao Ming, very boring, in the next year, to keep the implementation of Redis in such operations, the new key1, delete key1, then add key1, then delete the key1, so repeatedly. ok, there is a problem now, a year later, the log file will be how much? Follow-up this file in each instruction is being fetched for data recovery, and ultimately the restoration is complete, how long it will take?
From the above example it can be seen that log persistent, very distinct advantages and disadvantages:
Advantages: the maximum to retain each data changes, data integrity good
disadvantages: files kept append, will cause the file non-stop expansion, subsequent recovery efficiency is very low.
Redis how to solve this problem?
Obviously, we need to solve two problems: 1 log file is too large, 2 instruction vain repetitions, as the example above, one year, the actual data, or add a key, or what data are not.
Redis AOF rewrite:
Existing assumed as follows:
1.set key1 XX
2.set key2 XX
3.Set key3 XX
...
10.set key10 XX
10 operations, 10 to Redis records, then the presence of 10 instructions AOF intermediate file, then the data 10 is present in Redis.
When performing overwriting AOF, before directly reading data in Redis, i.e., the final instruction: set key1 xx key2 xx key3xx ... key10 xx, 10 will eventually merge into one instruction.
Implementation modalities:
- Performed manually
bgrewriteaof
- Automatic execution
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage
Question:
If the current instruction rewritten to fork child-threaded execution, then, if the child thread executed during rewriting, the parent thread a piece of data will be changed, then the child thread after rewrite is completed, alterations to this instruction data It will not be recorded into the new AOF file.
To solve the problem of inconsistent data state, after the fork a child thread parent thread, maintains a command buffer, in the meantime, the parent thread continue to respond to external requests, while this will log the time in the buffer, when after rewriting the child thread to complete, within the parent thread and then command buffer, append files into the new AOF.
AOF record Frequency:
- no: os using read and write buffers, when the data buffer is filled, the append file into the AOF
- second (default): written per second
- always: every time modifications are written AOF
RDB, AOF mixed write
Redis 4.0 version, support RDB + AOF swizzling mode, i.e. some of the old data saved in the form of RDB, then the subsequent instructions in the form of instructions written AOF.
When AOF rewrite command is executed, the current data will be saved as RDB, a write command into the buffer zone during the final buffer write AOF. Note that the final mixture is generated to write a AOF file, which, rdb is the first half of binary data to "redis" character beginning, is the second half of the file in the buffer subsequent instruction. After the rewrite is completed, after writing a command into the AOF continues to append file.
Advantages: RDB to recover data quickly, in large amounts of data quickly restored on the basis of only the incremental data is less data to modify instruction, greatly enhance the efficiency of data recovery.
