AdaGrad algorithm adjusts the learning rate in each dimension of the gradient values of each dimension according to the independent variables, thus avoiding a unified dimension of the problem difficult to adapt to all dimensions.
Features:
-
Small quantities stochastic gradient by accumulation variable elements, appears in the denominator of the learning rate. (If the partial derivatives of the objective function related arguments have been large, the learning rate decreased rapidly; and vice versa.)
-
If the early fall too fast iteration + current solution is still poor, it can make it difficult to find an effective solution.
First, the algorithm early solution
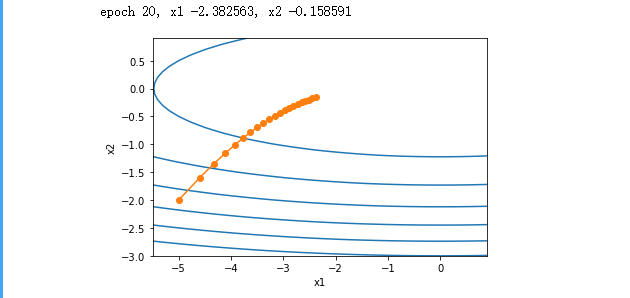
Achieve AdaGrad algorithm Using the study was 0.4. Auto iteration variable output trajectory smoother. But the
in the cumulative effect of the learning rate continue to decay, automatically variable in the smaller size range of movement iterations later.
%matplotlib inline
import math
import torch
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
def adagrad_2d(x1, x2, s1, s2):
g1, g2, eps = 0.2 * x1, 4 * x2, 1e-6
s1 += g1 ** 2
s2 += g2 ** 2
x1 -= eta /math.sqrt(s1 + eps) * g1
x2 -= eta / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2
def f_2d(x1, x2):
return 0.1 * x1 **2 + 2 *x2 ** 2
eta = 0.4
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))
operation result:
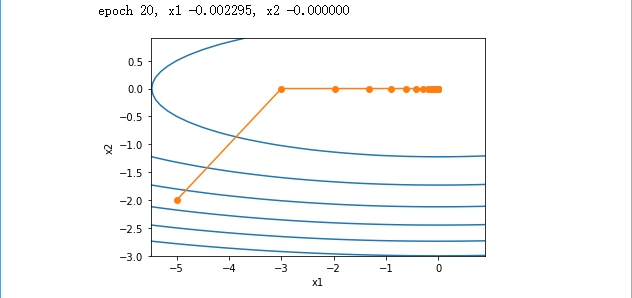
Increase the learning rate zoomed to 2. Auto variables can be seen more quickly approaching the optimal solution
eta = 2
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))
operation result:
Second, from scratch to achieve
With momentum method ⼀ like, AdaGrad algorithm with it the need to maintain state variables ⼀ like shape automatically for each variable. The following AdaGrad operator
implementing the method algorithm formula.
# 从零开始实现
%matplotlib inline
import math
import torch
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
features, labels = d2l.get_data_ch7()
def init_adagrad_states():
s_w = torch.zeros((features.shape[1], 1), dtype=torch.float32)
s_b = torch.zeros(1, dtype=torch.float32)
return (s_w, s_b)
def adagrad(params, states, hyperparams):
eps = 1e-6
for p, s in zip(params, states):
s.data += (p.grad.data**2)
p.data -= hyperparams['lr'] * p.grad.data / torch.sqrt(s + eps)
d2l.train_ch7(adagrad, init_adagrad_states(), {'lr' : 0.1},features,labels)
operation result:

Third, the emergence of run-time error
Error Code OSError: ../../data/airfoil_self_noise.dat not found.File not found:

in this site downloads "airfoil_self_noise.dat", putting it in this path "../../data/airfoil_self_noise.dat". You can run successfully.

Reference Links: https://zh.d2l.ai/chapter_optimization/adagrad.html