I recently encountered a typical case because of the performance of the derived table in sql caused by rewriting the SQL to improve performance, but did not clarify the reason of which the derived table is exactly what causes adverse effects on performance.
After so happened, soon saw accidentally introduced and its related properties derived table hereinafter referred to, only to find why, based on this article, use a very simple demo to demonstrate the problem , while cautioning against the use of MySQL in a derived table.
What is a derived table
Definition of derived tables, do not force the force, the next shot can be born from the love of the public company in number, that's very clear, the connection address: https://mp.weixin.qq.com/s/CxagKla3Z6Q6RJ- x5kuUAA , invasion delete, thank you. 
Here we focus on it some limitations when join with the parent query, if there are distinct derived table, group by union / union all, having, associated with sub-queries, limit offset, etc., ie parameter parent query can not be passed to the derived table query, causing some performance issues.
testing scenarios
Assumed to be in the MySQL relational data, imagine there is this query: an order table and the corresponding logistics information table, the relationship is 1: N, check orders and the latest logistics information, the query how to write (assuming that the problem exists and no proof of whether reasonable)?
I believe not complicated, to see if it is a single order of logistics information, join two tables together, in reverse chronological order according to the first to take this information if you want to query multiple orders or all orders over a certain period of time information it?
If it is a commercial database or MySQL 8.0 has ready-made analysis functions can be used, if it is MySQL 5.7, there is no ready-made analysis functions, how to write it?
Simple demo it, to illustrate the problem: Add t1 represents the orders table, t2 represents a stream information table, c1 is the order number (association key), the data of t1 and t2 is more than one pair.
CREATE TABLE t1 ( id INT AUTO_INCREMENT PRIMARY key, c1 INT, c2 VARCHAR(50), create_date datetime ); CREATE TABLE t2 ( id INT AUTO_INCREMENT PRIMARY key, c1 INT, c2 VARCHAR(50), create_date datetime ); CREATE INDEX idx_c1 ON t1(c1); CREATE INDEX idx_c1 ON t2(c1);
1:10 scale test data is written into two tables, that order exists a 10 logistics information, its order of creation time logistics information is randomly distributed within a certain time frame. Test data in one million is enough.
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loop_count` INT ) BEGIN SET @p_loop = 0; while @p_loop<loop_count do SET @p_date = DATE_ADD(NOW(),INTERVAL -RAND()*100 DAY); INSERT INTO t1 (c1,c2,create_date) VALUES (@p_loop,UUID(),@p_date); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); SET @p_loop = @p_loop+1; END while; END
This is a typical example of data (order information and its logistics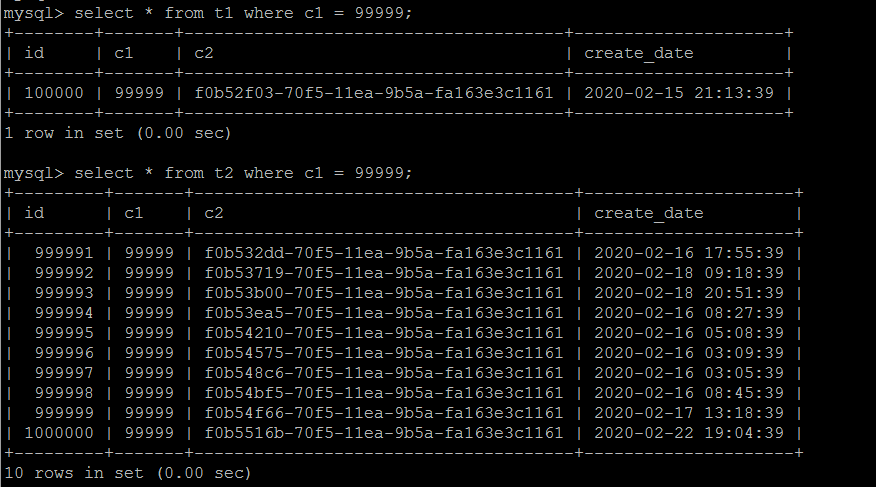
Performance problems derived table
according to the wording of the most common, it is to achieve a similar commercial database ROW_NUMBER () function, a packet number according to the order, and ordering information for each stream request to order number, and finally taking the first stream of information i.e. can.
For simplicity, this SQL query only the latest logistics information an order.
So he wrote such a statement, which through a derived table, use a typical row_number () function is equivalent to realize the analysis, this statement is certainly no problem to implement the logic, the results are fully in line with expectations, but the execution time will be close to 3 second, this is too far beyond the expected.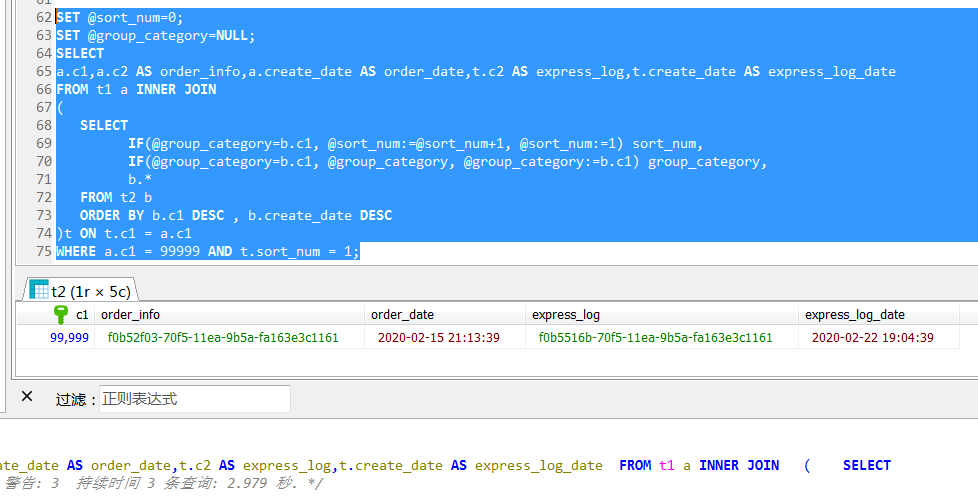
Parenthetically: Many people including interviews would ask, SQL optimization What skills?
Does not rule out the implication is that some people want you to enumerate some "fixed routine," how about where such conditions, and how to build the index, what a mess, list out a lot, so many years later, in this type of routine my list is still by far the most annoying routines.
The ever-changing reality, a fixed routine may be so that, but more often, it is necessary to make a specific analysis is based on circumstances rather than dead condom way, if there is a (series) rules can be set, the execution plan is not another back to the original model of the RBO?
Faced with a need to optimize the SQL, then figure out the sql logic: first whether it is actually how the implementation of the first in my mind to have an implementation plan, expected to have an implementation that are expected to perform the most efficient .
1, if you perform as expected, but the performance did not meet expectations, need to reflect on what is causing factors?
2, if not performed as expected, but the efficiency is relatively high or exceeded expectations, also need to reflect on, and the statement itself is not clear how to get the most efficient?
For this SQL, I tend to make a clear sorting is achieved by a derived table child tables, the parent query then filtered (screened latest piece of data),
I personally speculative execution plan is as follows:
Because the join condition is t.c1 = a.c1, where conditions are a.c1 = 99999, logically speaking, it is more clear and logical, since a.c1 = 99999 and t.c1 = a.c1, this filter criteria will advance directly to the sub-query ( internal derived table), sift get away with
the performance of the surface, the actual implementation of such a plan is likely not to go, but it is unexpected.
It can be seen inside the derived table is a full table scan, that is to say with t2 doing a full table scan, and then sort its logistics information, and then screened order number (where a.c1 = 99999 according to the outer query )
this can be said to be completely unexpected, initially did not know the outer query, and can not advance to the internal derived table.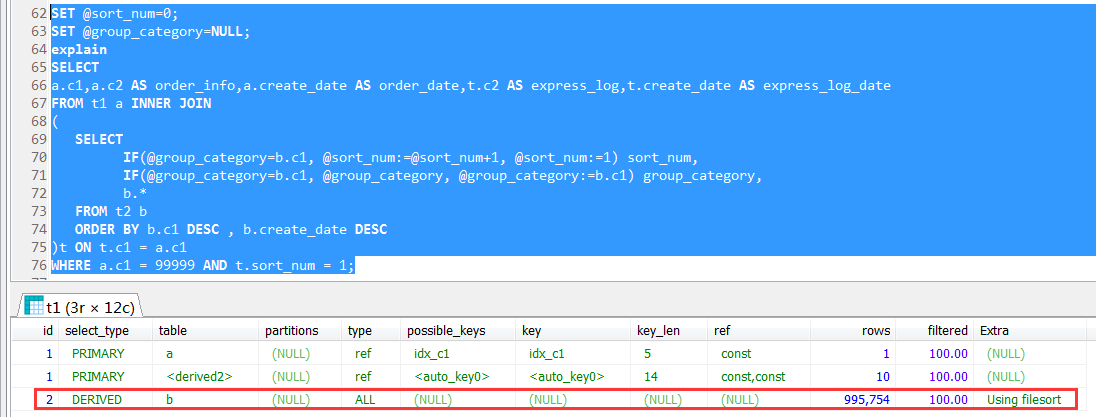
This involves the implementation of a related derived_merge,
refers to a query optimization technology, the role is to merge derived table to an external query to improve the efficiency of data retrieval. This feature is introduced (refer MySQL5.7 version https://blog.csdn.net/sun_ashe/article/details/89522394 ).
For a practical example, such as for select * from (select * from table_name ) t where id = 100;
with soil words of the conditions the outer query would advance to the subquery derived table, in commercial databases, it's all is taken for granted, it is not necessarily in MySQL, but had to admit MySQL optimizer weak.
Based on this a bit rewritten SQL, as follows, main and child tables to join up, while the sub-table is sorted, and then the outer layer of screening the latest piece of information (t.sort_num = 1),
then rewrite the query takes only 0.125 second, about 20 times + upgrade, which is the absence of any change in external conditions of the situation.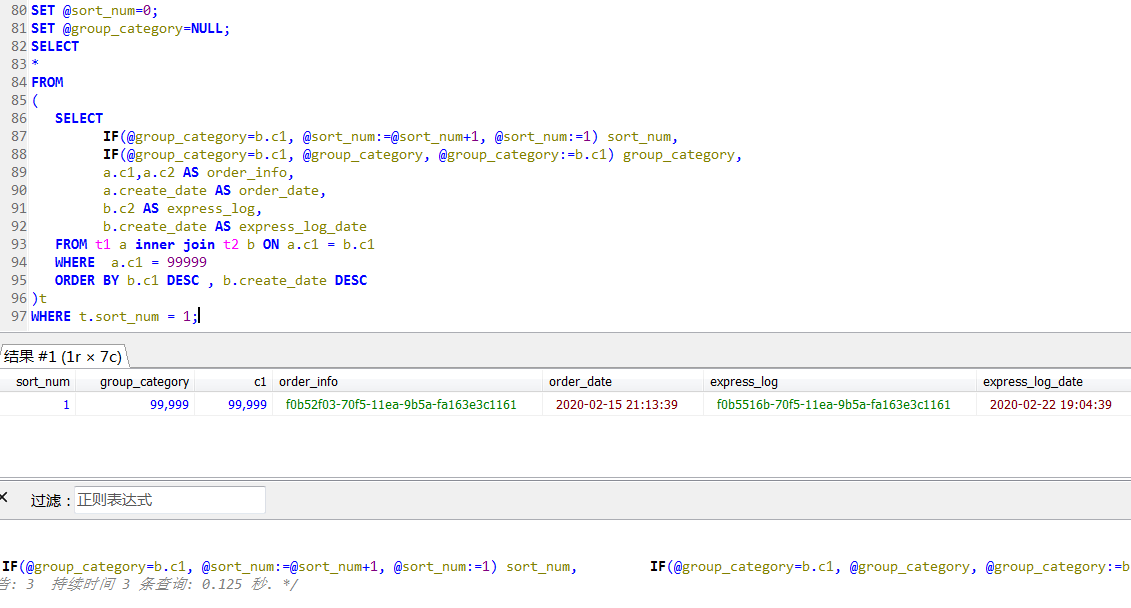
In fact, this implementation plan is the above-mentioned "expected" implementation plan, screening conditions are applied to the two tables, calculated to do the sort of logic after been to the screening.
As for why the first time did not use the wording, in fact, write SQL everyone has their own habits, the idea is to first of all can be done does not involve any join, first the target object sorting calculations, etc., to complete a matter within after then join the main table fetch data.
Personally I think that this is a way to write logic looks more clear and understandable, especially when more join the list each step to complete their share of things, and then talk to the other tables join (this is of course a matter of opinion issues, personal ideas may be different, here a little deviation.)
If the above-mentioned first written in SqlServer or other relational database, is fully equivalent to the wording of the second, so the start was not expected this huge performance difference.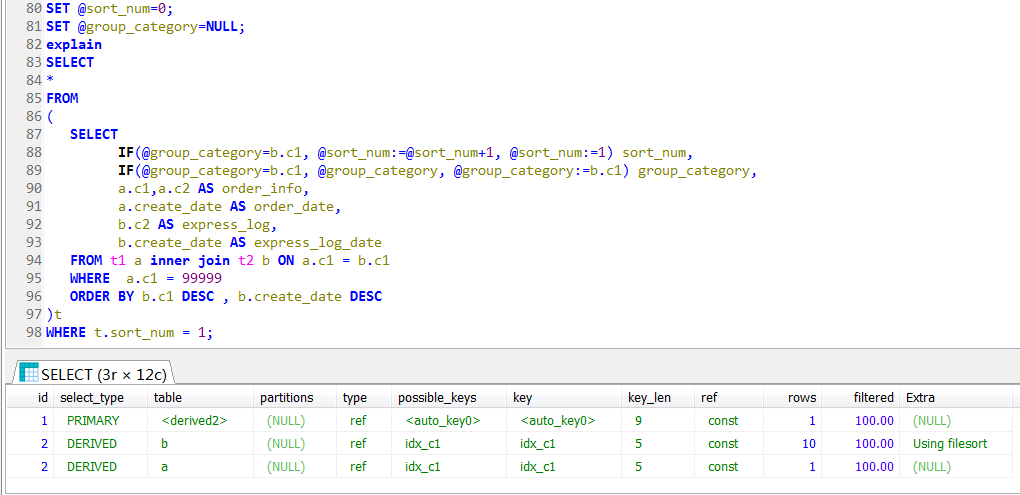
In fact, here you can not return to the restrictions mentioned at the beginning of this article derived tables, and this screenshot from here: https://blog.csdn.net/sun_ashe/article/details/89522394 , invasion deleted.
Any walked continue logic, we are unable to realize the outer query filter criteria to advance to the sub-derived table query.
That there is distinct derived table, group by union / union all, having, a correlated subquery, case limit offset, etc., can not be derived_merge.
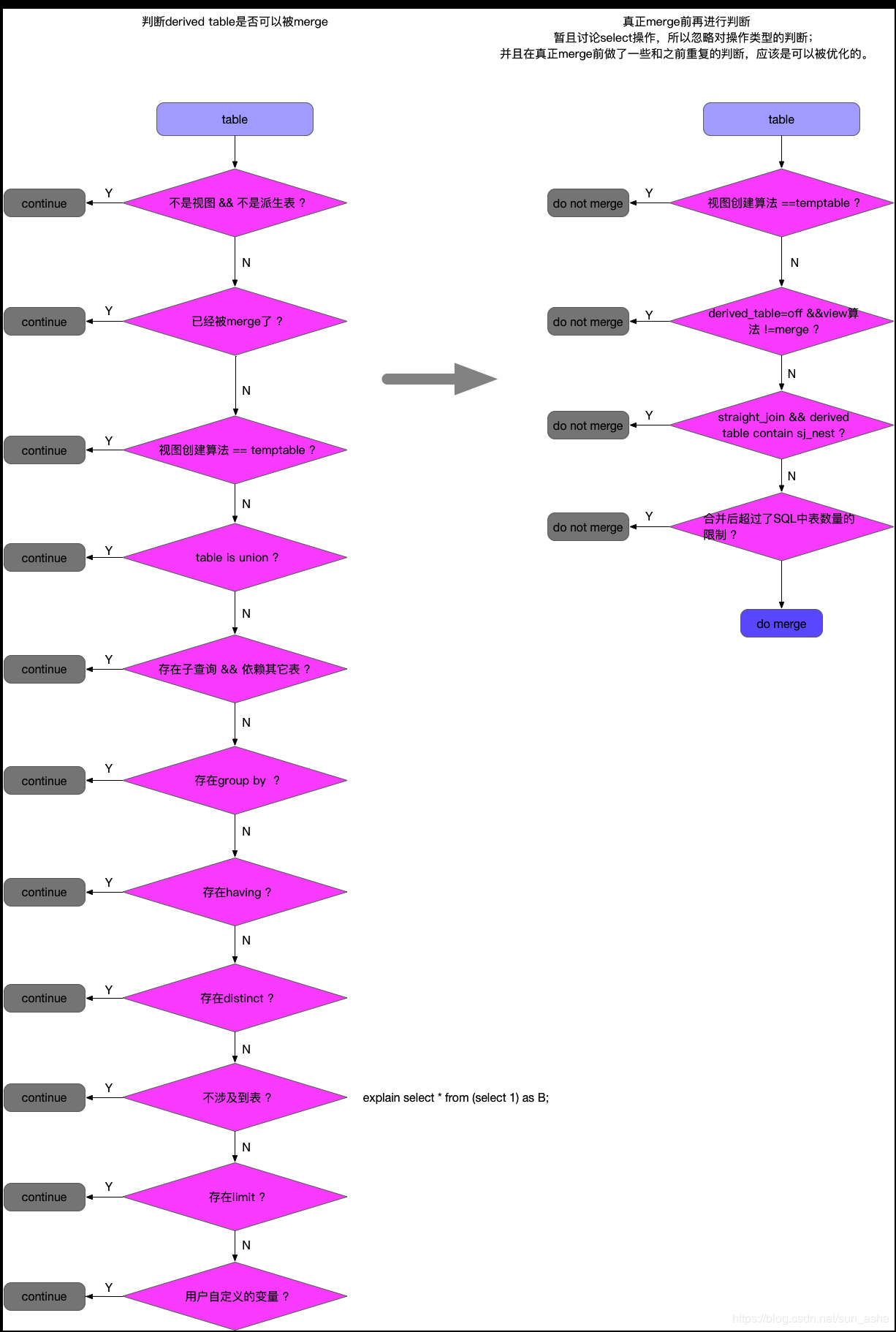
It is believed that in any case continue a trend of branch, it is unable to use the derived_merge.
to sum up
More than a simple case, for a limited derived_merge may these databases on other issues is not a problem, the problem is in MySQL, MySQL optimizer is actually still need to improve, and if there are similar once derived table situation, encountered a performance problem or need is worth noting.
Anticlimactic ......
demo manner sql
SET @sort_num=0; SET @group_category=NULL; SELECT a.c1,a.c2 AS order_info,a.create_date AS order_date,t.c2 AS express_log,t.create_date AS express_log_date FROM t1 a INNER JOIN ( SELECT IF(@group_category=b.c1, @sort_num:=@sort_num+1, @sort_num:=1) sort_num, IF(@group_category=b.c1, @group_category, @group_category:=b.c1) group_category, b.* FROM t2 b ORDER BY b.c1 DESC , b.create_date DESC )t ON t.c1 = a.c1 WHERE a.c1 = 99999 AND t.sort_num = 1; SET @sort_num=0; SET @group_category=NULL; explain SELECT * FROM ( SELECT IF(@group_category=b.c1, @sort_num:=@sort_num+1, @sort_num:=1) sort_num, IF(@group_category=b.c1, @group_category, @group_category:=b.c1) group_category, a.c1,a.c2 AS order_info, a.create_date AS order_date, b.c2 AS express_log, b.create_date AS express_log_date FROM t1 a inner join t2 b ON a.c1 = b.c1 WHERE a.c1 = 99999 ORDER BY b.c1 DESC , b.create_date DESC )t WHERE t.sort_num = 1;