Overview
1.1 Cover and Hart in 1968 proposed initial neighborhood algorithm
1.2 classification (classification) algorithm
1.3 input-based learning instances (instance-based learning), lazy learning (lazy learning) that is crammed, not a good model for training ahead
1.4 In order to judge examples of unknown classes, all known classes of example as a reference
algorithm
Step:
Select the parameter K
is calculated from all known and unknown examples of instances of
selected recent known instance of K
according to the minority is subordinate voting rule (majority-voting) majority, so the unknown instance classified as K nearest neighbors majority of most samples category
Distance (Euclidean Distance)
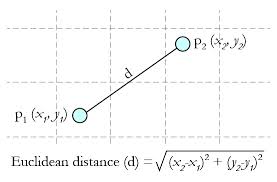
from the n-dimensional:
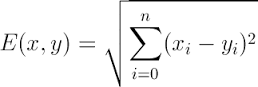
example
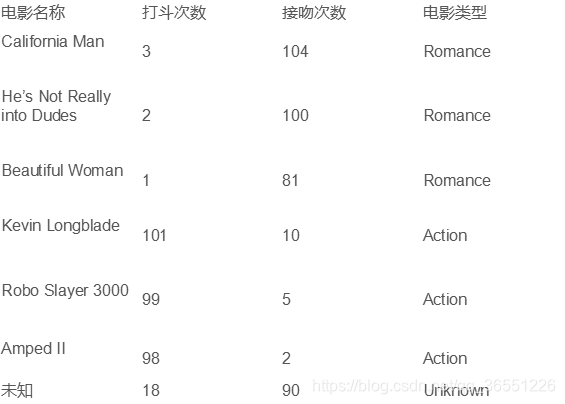
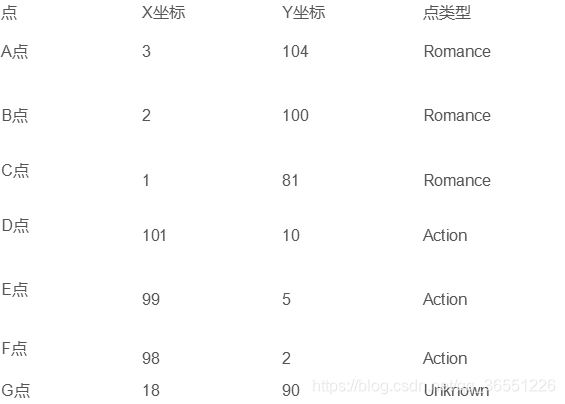
import math
def ComputeEuclideanDistance(x1, y1, x2, y2):
d = math.sqrt(math.pow((x1-x2), 2) + math.pow((y1-y2), 2))
return d
d_ag = ComputeEuclideanDistance(3, 104, 18, 90)
print('d_ag:', d_ag)
Calculating for each point a distance to point G
Advantages and disadvantages
advantage:
- Simple, easy to understand, easy to implement
- By the choice of K may be provided with data lost noise robustness
Disadvantages:
- It requires a lot of space to store all known instances
- Algorithm complexity is high (need to compare all instances of known instance to be classified)
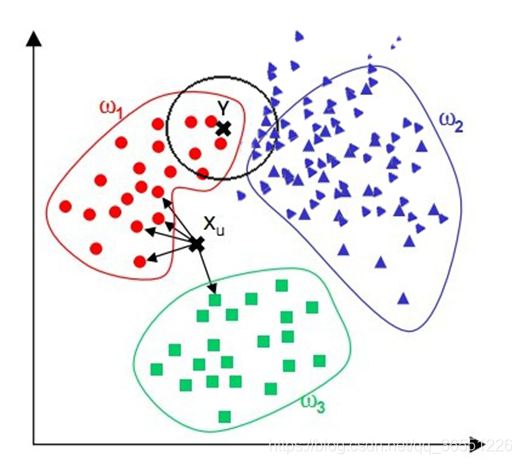
- When the uneven distribution of its sample, such as a class in which the sample is too large (too many instances) dominant when new and unknown instance easily be classified as dominant this sample, because the number of instances of this type of sample is too large, but this new instance of actual and unknown wood close to the target sample
- The point Y in the figure above, should be attributed to the red-based, but the majority of blue attributable to the class
Improve
Consideration of the distance, together with the weight according to a distance, such as: 1 / d (d: distance)
Examples
sklearn
from sklearn import neighbors
from sklearn import datasets
knn = neighbors.KNeighborsClassifier()
iris = datasets.load_iris()
knn.fit(iris.data, iris.target)
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(predictedLabel)
customize
import csv
import random
import math
import operator
def loadDataset(filename, split, trainingSet = [], testSet = []):
with open(filename, 'rt') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y]) # 将字符型数据转为浮点型
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length): # 计算每个维度的和
distance += pow((instance1[x]-instance2[x]), 2)
return math.sqrt(distance) # 测试数据到每一个训练数据的距离
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
#testinstance
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
#distances.append(dist)
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k): # k个最近的距离
neighbors.append(distances[x][0])
return neighbors
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)): # 看邻居的标签,进行投票
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0] # 票数最多的标签
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0
def main():
#prepare data
trainingSet = []
testSet = []
split = 0.67
loadDataset(r'irisdata.txt', split, trainingSet, testSet)
print('Train set: ' + repr(len(trainingSet)))
print('Test set: ' + repr(len(testSet)))
#generate predictions
predictions = []
k = 3
for x in range(len(testSet)):
# trainingsettrainingSet[x]
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print ('>predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
print ('predictions: ' + repr(predictions))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')
if __name__ == '__main__':
main()
