A reference blog
1, https://blog.csdn.net/panguoyuan/article/details/38727273 a given problem
2, https://blog.csdn.net/qq_31975963/article/details/83898920 log4j output problem
Second, the problems encountered (1)
When the code is running large data Lesson found again reported the following exception (write blog before swear when I run no abnormal ..........)
Exception in thread "main" java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
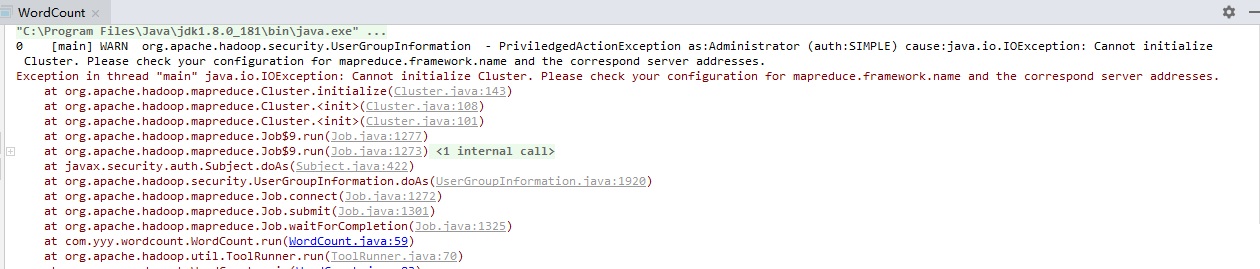
Then find online blog, blog found a reference 1, to solve this problem. Later, he joined with the content in my pom.xml file
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
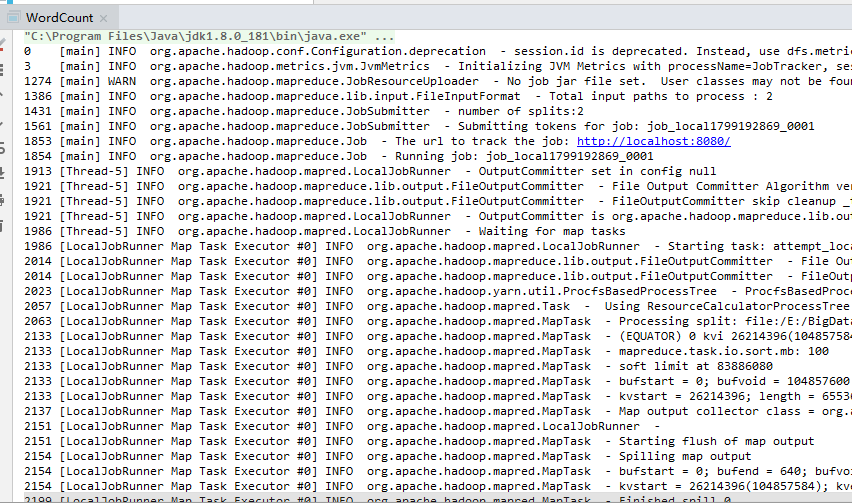
Then the problem is solved, then the result of the normal output, but does not seem to have found the console log contents output. . . . .
Third, the problems (2) encountered
No console log output. . . . (It is there ,,,, ago I swear)

The Internet to find a solution reference blog 2, to solve this problem
Create a file log4j.properties in the resources directory, add about content
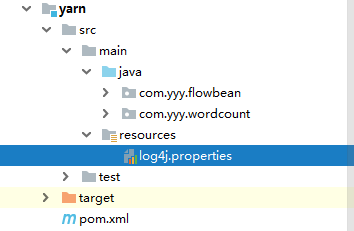
# Set root logger level to DEBUG and its only appender to A1.
log4j.rootLogger=INFO, A1
# A1 is set to be a ConsoleAppender.
log4j.appender.A1=org.apache.log4j.ConsoleAppender
# A1 uses PatternLayout.
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
Then there is the log run output