Article Directory
Decision tree is defined
Tree and divide a data set selected for a feature, thus classifying data
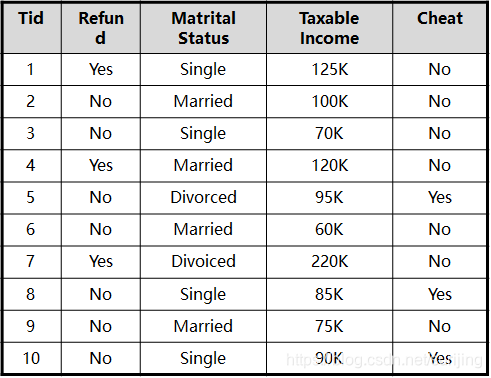
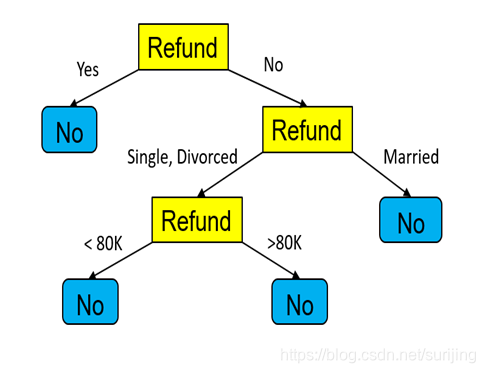
Decision Tree build process
Feature selection: select a characteristic feature from the training data as the standard of the current node splitting
Decision Trees: evaluation criteria based on the selected feature, from under the child node generated recursively until the data set is not sub-tree is stopped growing
pruning : If the tree level is too deep, it will cause over-fitting, needs pruning to reduce the size and structure of the tree (including the pre-pruning and pruning)
Note: the generated decision tree is a recursive process, decision tree the basic algorithm, there are three situations in which a recursive returns:
1. the current sample contains the right node of the same category, no division of
2. the current set of attributes is empty, or all samples the same values on all properties, not dividing
3. sample set containing the current node is empty can not be divided
Decision Tree Algorithm
| ID3 | By information gain |
|---|---|
| C4k5 | By information gain ratio |
| CART | By Gini coefficient |
- ID3
to information theory, based on information entropy and information gain, as measured in order to achieve categorize the data;
core idea: to gain information measure attribute selection, select gain the greatest attribute information to split after split
| Entropy | 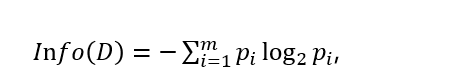 |
|---|---|
| Information gain | 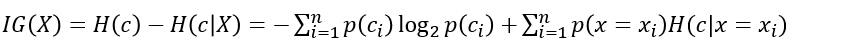 |
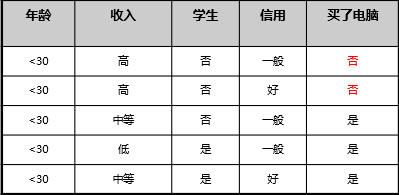
Example:
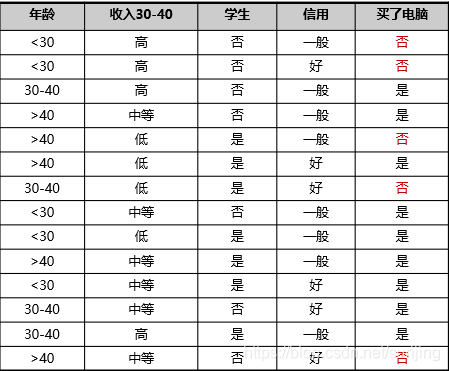
In the above case, the number of samples: 14; the number of samples not later: 5; the number of samples for later: 9
Step: data set information entropy calculation
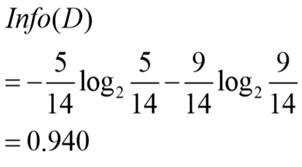
second step to determine the properties of the first division --- -> information gain is calculated for each attribute, sizes:
| By age |  |
|---|---|
| By revenue | 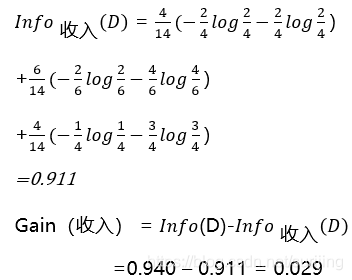 |
| By students | 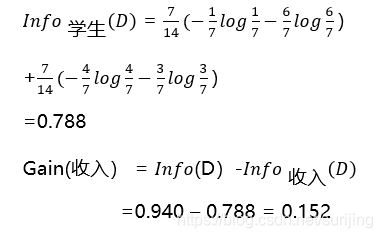 |
| By credit | 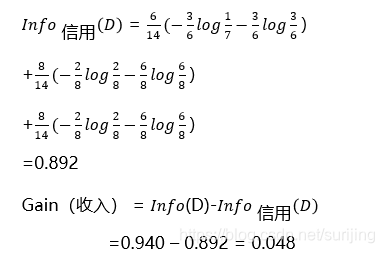 |
| Finally, compare information gain | The first results were split by age |
The third step is to determine the second division of the property:
the splitting process the same as the first, based on the age of the data set
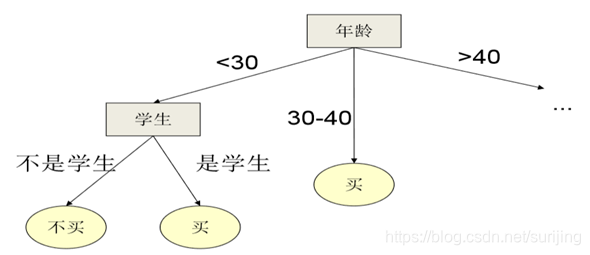
until the last node of comparable data on stop dividing
| Decision tree advantages | Conceptually simple, the computational complexity is not high, strong explanatory, easy to understand output; preparation of simple data; missing insensitive intermediate values; wide range of applications |
|---|---|
| The shortcomings of the decision tree | May cause problems over-matched; more difficult to deal with when information is missing; information gain measure will be biased in favor of higher value attribute as a classification attributes |
- C4.5
ID3 algorithm, the property can only be discrete, C4.5 is optimized ID3 algorithm
| Improved 1 | Instead of using information gain information gain ratio to select properties, tend to overcome the lack of choice when selecting property values and more with the information gain attributes: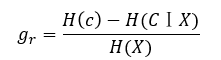 |
|---|---|
| Improved 2 | To complete the processing of the successive discrete attribute values |
| Improved 3 | You can handle the case of loss of property values of |
| Improved 4 | Prune the tree after the completion of construction: pre-pruning: pre-set needs to generate several levels of the tree, after completely correct classification of the training set to stop the growth of trees; pruning: let the whole tree is generated, then then prune |
Example:


- CART
ID3 is only applicable to the classification, information gain through each column
C4.5 by information gain of each column
and CART purity ----- by the Gini coefficient after the classification
split is designed to enable data becomes pure, decision-making result tree output closer to the true value, if the classification tree, CART values measured using GINI purity node, if a regression tree, using the sample variance measure node purity, the more impure node, node classification or prediction of the effect worse;
the CART can do both classified and can do return, a binary tree is
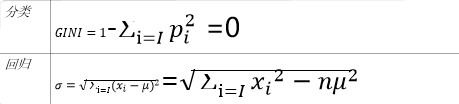
an example:
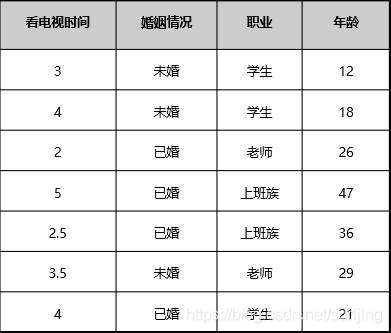
| Press room situation there | 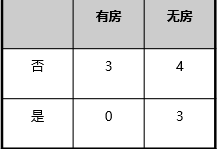 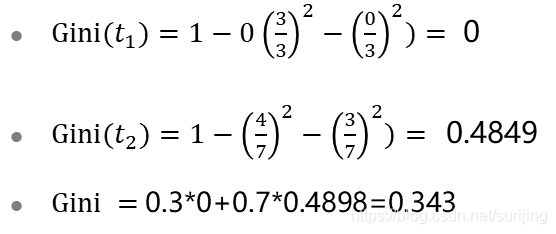 |
|---|---|
| By marital status | 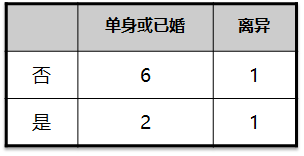 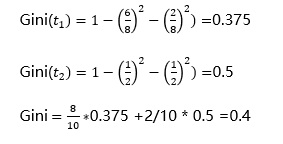 |
Successive values of division:
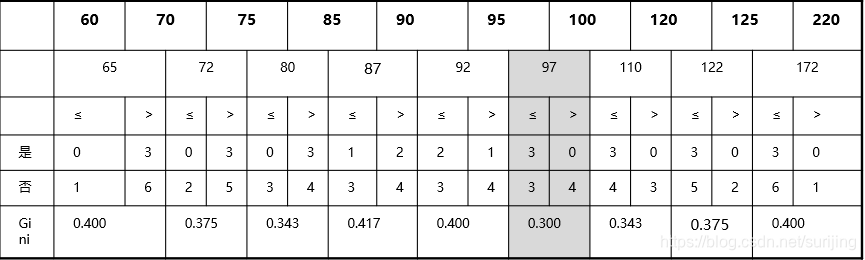
ID3python achieve
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 7 11:58:40 2020
@author: DELL
"""
#定义函数,构造函数数据集
import operator
from math import log
import subprocess
from sklearn import tree
def createDataSet():
labels =["头发","声音"]#两个特征
dataSet=[['长','粗','男'],
['短','粗','男'],
['短','粗','男'],
['长','粗','女'],
['长','细','女'],
['短','粗','女'],
['短','细','女'],
['长','粗','女']]
return dataSet,labels
#获取函数类型的类别
def createTree(dataSet,lables):
#获取每个类别男生数量,女生数量
classlist=[example[-1] for example in dataSet]
#print(classlist)
#统计每个类别的人数classlist.count(classlist)
#判断 是否停止树的计算
#第一种情况,如果类别人数和总人数相等,不进行下述计算
if classlist.count(classlist[0])==len(classlist):
return classlist[0]
#第二种情况,如果数据集中只有一个人 也不进行计算
if len(dataSet[0]) == 1:
return majorityCnt(classlist)
#选择分裂类型
bestFeat = chooseBestFeatureTosplit(dataSet)
bestFeatlable = lables[bestFeat]
myTree = {bestFeatlable:{}}
del(lables[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=lables[:]
myTree[bestFeatlable][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
def chooseBestFeatureTosplit(dataSet):
#获取特征列的个数("长",“粗”)两列
numFeature = len (dataSet[0])-1
#对整个数据集 计算 信息熵
baseEntropy = calcShannonEnt(dataSet)
#对每一列计算条件信息熵
bestInfoGain = 0
bestFeature = -1
#把两列属性获取出来
for i in range (numFeature):
featlist = [example [i] for example in dataSet]
#print(featlist)
'''['长', '短', '短', '长', '长', '短', '短', '长']
['粗', '粗', '粗', '粗', '细', '粗', '细', '粗']'''
#获取每个特征里面 有的属性值 长的一列 粗的一列
uniqueVals = set(featlist)
#print(uniqueVals)
'''{'长', '短'}
{'粗', '细'}'''
newEntroy = 0
#统计每个类别的 样本的 数量--->得出信息熵
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)#对哪个数据集,哪个类别,哪个属性
#计算 条件信息熵
prob = len(subDataSet)/float(len(dataSet))
newEntroy += prob*calcShannonEnt(subDataSet)
#信息增益 信息熵-条件信息熵
infoGain= baseEntropy - newEntroy
#比较两列属性的信息增益
#比较出最大的信息增益
if(infoGain > bestInfoGain):
bestInfoGain=infoGain
bestFeature = i
return bestFeature
#计算信息熵
#按照某个特征值 对数据集进行划分,希望获取某个类的总个数
#返回和某个类别一样的所有数据“长”, 去除掉 当前的属性列 所有数据集
def splitDataSet(dataSet,i,value):
retDataSet=[]
for vote in dataSet:
if vote[i]==value:
reduceFeatVec = vote[:i]
reduceFeatVec.extend(vote[i+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def calcShannonEnt(dataSet):
classCount = {}
#遍历整个 数据集 各个类别的人数统计出来
for vote in dataSet:
currentLabel = vote [-1]
if currentLabel not in classCount.keys():
classCount[currentLabel]=0
classCount[currentLabel] += 1
#得到 (男,3) (女,4)这种类别
#根据 信息熵的计算方式 得到信息熵
shannonEnt = 0
for key in classCount:
#获取整个数据集的大小-----14
numEntries = len(dataSet)
prob = float(classCount[key])/numEntries
shannonEnt -= prob*log(prob,2)#基础的信息熵
return shannonEnt
def majorityCnt(classlist):
classcount ={}
#在classlist男和女进行遍历
for vote in classlist:
if vote not in classcount.keys():
#如果没有男或女这个标签就添加并加一
classcount[vote] = 0
classcount[vote] += 1
sortedClasscount=sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
#print (sortedClasscount[0][0])
return sortedClasscount[0][0]
if __name__=='__main__':
dataSet,lables = createDataSet()
#print(dataSet)
print(createTree(dataSet,lables))
