
Einführung des Autors: Zhang Ji, beschäftigt sich mit der Trainingsoptimierung von Soutui/LLM und konzentriert sich auf die Optimierung der Systemunterschicht/Netzwerke.
Hintergrund
Da die Anzahl der Parameter großer Modelle von Milliarden auf Billionen ansteigt, führt die schnelle Ausweitung ihres Trainingsumfangs nicht nur zu einem erheblichen Anstieg der Clusterkosten, sondern stellt auch die Systemstabilität vor Herausforderungen, insbesondere durch das häufige Auftreten von Maschinenausfällen ein Problem, das nicht ignoriert werden kann. Bei groß angelegten verteilten Trainingsaufgaben sind Observability-Funktionen zum Schlüssel zur Fehlerbehebung und Leistungsoptimierung geworden. Daher wird technisches Personal, das im Bereich der groß angelegten Modellschulung tätig ist, zwangsläufig mit den folgenden Herausforderungen konfrontiert:
- Während des Trainingsprozesses kann die Leistung aufgrund verschiedener Faktoren wie Netzwerk- und Computerengpässen instabil sein, schwanken oder sogar nachlassen;
- Beim verteilten Training arbeiten mehrere Knoten zusammen (sei es ein Software-, Hardware-, Netzwerkkarten- oder GPU-Problem), der gesamte Trainingsprozess muss angehalten werden, was die Trainingseffizienz erheblich beeinträchtigt und wertvolle GPU-Ressourcen verschwendet.
Im tatsächlichen Trainingsprozess großer Modelle sind diese Probleme jedoch schwer zu beheben. Die Hauptgründe sind folgende:
- Der Trainingsprozess ist ein synchroner Vorgang, und es ist schwierig, anhand der Gesamtleistungsindikatoren auszuschließen, welche Maschinen zu diesem Zeitpunkt Probleme haben. Eine langsame Maschine kann die gesamte Trainingsgeschwindigkeit verlangsamen.
- Eine langsame Trainingsleistung ist oft kein Problem der Trainingslogik/des Trainingsrahmens, sondern wird in der Regel durch die Umgebung verursacht. Wenn keine trainingsbezogenen Überwachungsdaten vorhanden sind, hat das Drucken von Zeitleisten tatsächlich keine Auswirkung, und die Speicheranforderungen für die Speicherung von Zeitleistendateien sind ebenfalls wirkungslos hoch;
- Der Analyse-Workflow ist komplex. Wenn beispielsweise das Training hängt, müssen Sie den Druck aller Stapel abschließen, bevor der Brenner abläuft, und diese dann analysieren. Bei umfangreichen Aufgaben ist es schwierig, ihn innerhalb des Brenner-Timeouts abzuschließen.
Bei groß angelegten verteilten Trainingseinsätzen sind beobachtbare Fähigkeiten besonders wichtig für die Fehlerbehebung und Leistungsverbesserung. In der Praxis groß angelegter Schulungen hat Ant die xpu_timer-Bibliothek entwickelt, um die Beobachtbarkeitsanforderungen des KI-Trainings zu erfüllen. In Zukunft werden wir den XPU-Timer in DLRover öffnen. Jeder ist herzlich willkommen, zusammenzuarbeiten:) Die xpu_timer-Bibliothek ist ein Profiling-Tool, das die cublas/cudart-Bibliothek abfängt und cudaEvent verwendet, um die Matrixmultiplikations-/Set-Kommunikationsoperationen zeitlich festzulegen Es verfügt außerdem über Funktionen wie Timeline-Analyse, Hang-Erkennung und Hang-Stack-Analyse und ist für die Unterstützung einer Vielzahl heterogener Plattformen konzipiert. Dieses Tool verfügt über die folgenden Funktionen:
- Es gibt keinen Eingriff in den Code, keine Einbußen bei der Trainingsleistung und es kann im Trainingsprozess resident sein;
- Gleichgültig für Benutzer und irrelevant für das Framework
- Geringer Verlust/hohe Genauigkeit
- Die Aggregation/Bereitstellung von Indikatoren kann durchgeführt werden, um die weitere Verarbeitung und Analyse von Daten zu erleichtern.
- Hohe Effizienz der Informationsspeicherung
- Praktische interaktive Schnittstelle: Bietet eine benutzerfreundliche externe Schnittstelle, um die Integration mit anderen Systemen und die direkte Benutzerbedienung zu erleichtern und so den Einblick- und Entscheidungsprozess zu beschleunigen.
Design
Um das Problem von Trainingsabstürzen/Leistungseinbußen anzugehen, haben wir zunächst ein permanentes Kernel-Timing entwickelt:
- In den meisten Szenarien werden Trainingsabstürze durch NCCL-Operationen verursacht. Normalerweise müssen Sie nur die Matrixmultiplikation aufzeichnen und die Kommunikation festlegen.
- Bei Leistungseinbußen auf einer einzelnen Maschine (ECC, MCE) müssen Sie nur die Matrixmultiplikation aufzeichnen. Gleichzeitig kann durch die Analyse der Matrixmultiplikation auch überprüft werden, ob die Matrixform des Benutzers wissenschaftlich ist, und die Leistung von Tensorcore maximiert werden Verwendet Cublas direkt bei der Implementierung der Matrixmultiplikation.
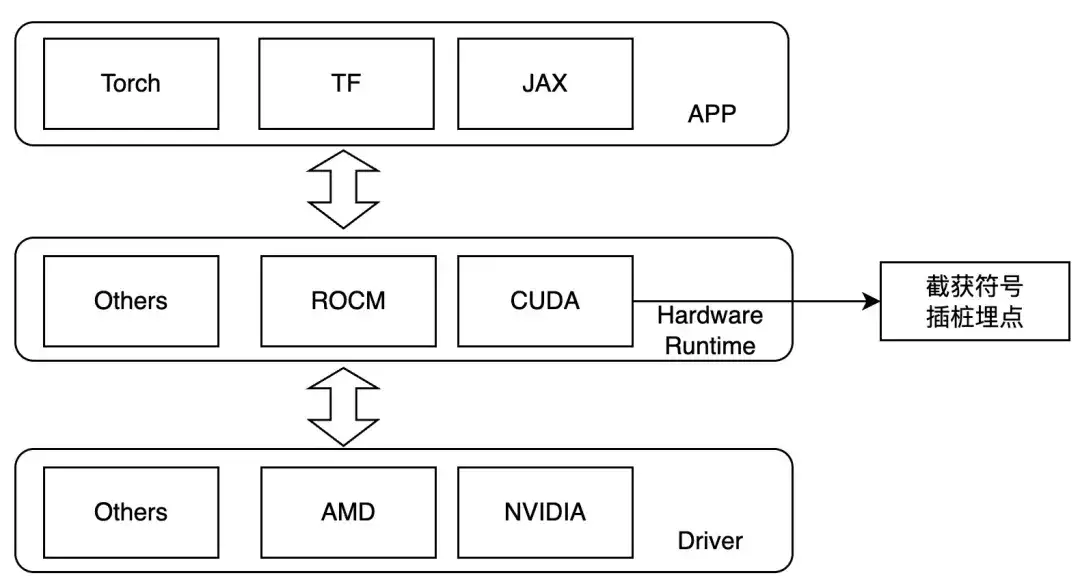
Daher planen wir, auf der Kernel-Startebene abzufangen und während der Laufzeit LD_PRELOAD festzulegen, um die interessierenden Vorgänge zu verfolgen. Diese Methode kann nur bei dynamischer Verknüpfung verwendet werden. Derzeit handelt es sich bei den gängigen Trainingsframeworks um dynamische Verknüpfungen. Bei NVIDIA-GPUs können wir auf die folgenden Symbole achten:
- ibcudart.so
- cudaLaunchKernel
- cudaLaunchKernelExC
- libcublas.so
- cublasGemmEx
- cublasGemmStridedBatchedEx
- cublasLtMatmul
- cublasSgemm
- cublasSgemmStridedBatched
Bei der Anpassung an unterschiedliche Hardware werden unterschiedliche Tracing-Funktionen über unterschiedliche Template-Klassen implementiert.
Arbeitsablauf
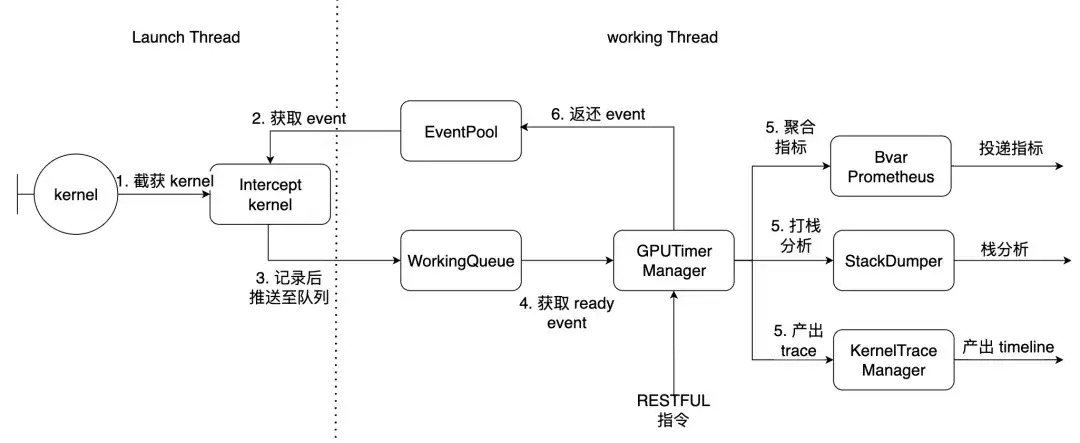
Am Beispiel von PyTorch ist der Startthread der Hauptthread der Fackel und der Arbeitsthread der Arbeitsthread innerhalb der Bibliothek. Hier werden die oben beschriebenen 7 Kernel abgefangen.
Anwendung und Effekte
Voraussetzungen
- NCCL wird statisch zu libtorch_cuda.so kompiliert
- Torch verknüpft libcudart.so dynamisch
Wenn NCCL dynamisch verknüpft ist, können benutzerdefinierte Funktionsoffsets bereitgestellt und zur Laufzeit dynamisch aufgelöst werden. Nach der Installation des Python-Pakets stehen Ihnen die folgenden Befehlszeilentools zur Verfügung
| xpu_timer_gen_syms | Bibliothek dynamisch injizierter Funktionsoffset zum dynamischen Generieren und Parsen von NCCL |
| xpu_timer_gen_trace_timeline | Wird zum Generieren von Chrome-Trace verwendet |
| xpu_timer_launch | Wird zum Mounten von Hook-Paketen verwendet |
| xpu_timer_stacktrace_viewer | Wird verwendet, um nach einer Zeitüberschreitung einen visuellen Stapel zu generieren |
| xpu_timer_print_env | Drucken Sie die Adresse von libevent.so und drucken Sie die Zusammenstellungsinformationen aus |
| xpu_timer_dump_timeline | Wird verwendet, um einen Timeline-Dump auszulösen |
LD_PRELOAD 用法:XPU_TIMER_XXX=xxx LD_PRELOAD=`path to libevent_hook.so` python xxx
Dynamische Erfassungszeitleiste in Echtzeit
Jeder Rang verfügt über einen Portdienst, der Befehle an alle Ränge gleichzeitig senden muss. Der Dienstport hat eine Datengröße von 32 B. Er speichert 1000 Datensätze und hat eine Größe von 32 KB Die Größe der generierten Timeline-JSON beträgt 150 KB * Weltgröße und ist damit weitaus kleiner als die grundlegende Verwendung
usage: xpu_timer_dump_timeline [-h]
--host HOST 要 dump 的 host
--rank RANK 对应 host 的 rank
[--port PORT] dump 的端口,默认 18888,如果一个 node 用了所有的卡,这个不需要修改
[--dump-path DUMP_PATH] 需要 dump 的地址,写绝对路径,长度不要超过 1000
[--dump-count DUMP_COUNT] 需要 dump 的 trace 个数
[--delay DELAY] 启动这个命令后多少秒再开始 dump
[--dry-run] 打印参数
Einzelmaschinensituation
xpu_timer_dump_timeline \
--host 127.0.0.1 \
--rank "" \
--delay 3 \
--dump-path /root/lizhi-test \
--dump-count 4000
多机情况# 如下图所示,如果你的作业有 master/worker 混合情况(master 也是参与训练的)
# 可以写 --host xxx-master --rank 0
# 如果还不确定,使用 --dry-run
xpu_timer_dump_timeline \
--host worker \
--rank 0-3 \
--delay 3 --dump-path /nas/xxx --dump-count 4000
xpu_timer_dump_timeline \
--host worker --rank 1-3 \
--host master --rank 0 --dry-run
dumping to /root/timeline, with count 1000
dump host ['worker-1:18888', 'worker-2:18888', 'worker-3:18888', 'master-0:18888']
other data {'dump_path': '/root/timeline', 'dump_time': 1715304873, 'dump_count': 1000, 'reset': False}
Die folgenden Dateien werden später zum entsprechenden Timeline-Ordner hinzugefügt.

Führen Sie dann xpu_timer_gen_trace_timeline unter dieser Datei aus
xpu_timer_gen_trace_timeline Es werden 3 Dateien generiert:
- merged_tracing_kernel_stack-Hilfsdatei, Flame-Graph-Originaldatei
- Trace.json zusammengeführte Zeitleiste
- tracing_kernel_stack.svg, Callstack für Matrixmultiplikation/nccl
Ein Fall von SFT-Analyse mit Lama-Rezepten und 32 Karten
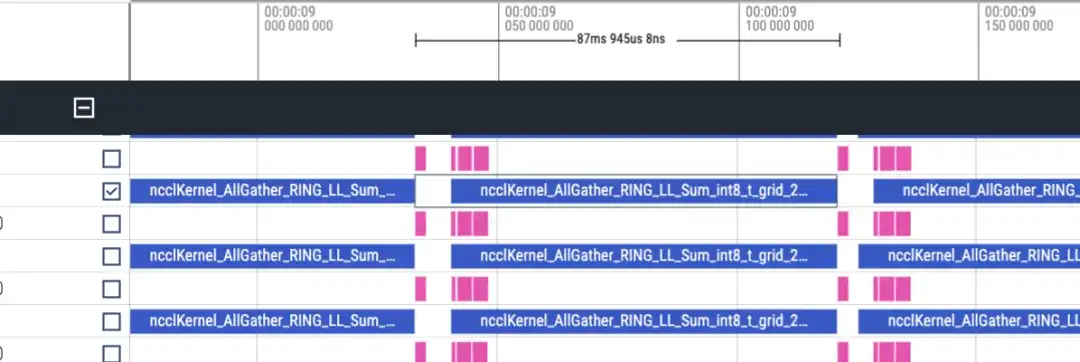
Die Zeitleiste sieht ungefähr wie folgt aus: Für jeden Rang werden zwei Zeilen matmul/nccl angezeigt, und alle Ränge werden angezeigt. Beachten Sie, dass es hier keine Vorwärts-/Rückwärtsinformationen gibt. Dies kann grob anhand der Dauer beurteilt werden, die doppelt so lang ist wie vorwärts.

Vorwärtszeitleiste, ca. 87 ms
Reverse-Timeline ca. 173 ms
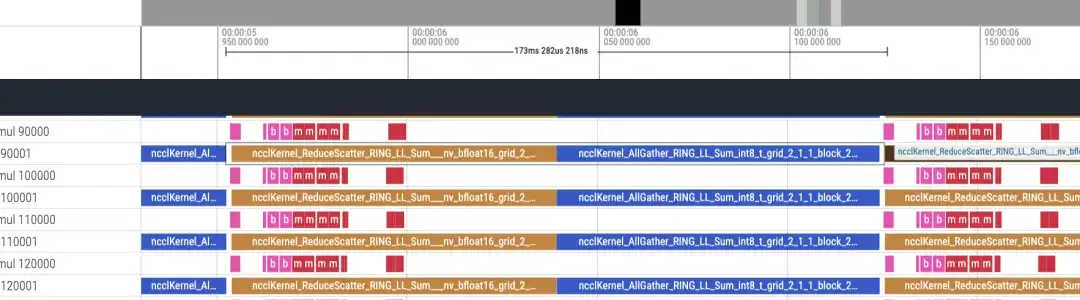
Insgesamt gibt es 48 Schichten und der Gesamtzeitverbrauch beträgt (173 + 87) * 48 = 12480 ms. Einschließlich lmhead, Einbettung und anderer Vorgänge dauert die Gesamtzeit korrekt. Anhand der Zeitleiste wird festgestellt, dass die Kommunikationszeit viel länger ist als die Berechnungszeit, und es kann festgestellt werden, dass der Engpass durch die Kommunikation verursacht wird.
Hang-Stack-Analyse
Nachdem Sie das Paket mit pip installiert haben, können Sie es über das Befehlszeilentool analysieren. Standardmäßig druckt der Kernel nach mehr als 300 Sekunden das SVG-Bild, um es anzuzeigen Drucken Sie den entsprechenden Stapel und drucken Sie die Ergebnisse des Trainingsprozesses in stderr. Wenn Sie GDB über Conda installieren, verwenden Sie die Python-API von GDB, um den LWP-Namen abzurufen. Der standardmäßig installierte GDB8.2 kann manchmal nicht abgerufen werden. gdb. Das Folgende ist ein 2-Karten-Stapel zur Simulation des NCCL-Timeouts:

Das Folgende ist ein Beispiel für ein 8-Karten-Lama7B-SFT-Training auf einer einzelnen Maschine
Mit den vom Python-Paket bereitgestellten Tools kann das Flame-Stack-Diagramm des Aggregationsstapels generiert werden. Hier können Sie den Stapel ohne Rang 1 sehen, da der Hang durch Töten von -STOP Rang1 während des 8-Karten-Trainings simuliert wird, sodass Rang 1 in der Stoppzustand.
xpu_timer_stacktrace_viewer --path /path/to/stack
运行后会在 path 中生成两个 svg,分别为 cpp_stack.svg, py_stack.svg
Beim Zusammenführen von Stapeln gehen wir davon aus, dass derselbe Aufrufpfad zusammengeführt werden kann, das heißt, der Stacktrace ist vollständig konsistent, sodass die meisten Stellen, die im Hauptthread stecken bleiben, gleich sind. Wenn jedoch einige Schleifen und aktive Threads vorhanden sind, werden sie gedruckt Der obere Stapel ist möglicherweise inkonsistent, aber der gleiche Stapel wird unten ausgeführt. Beispielsweise bleiben die Threads im Python-Stack hängen [email protected] Darüber hinaus hat die Anzahl der Stichproben im Flammendiagramm keine Bedeutung. Wenn ein Hängen erkannt wird, generieren alle Ränge entsprechende Stacktrace-Dateien (Rang1 ist angehalten, es gibt also keine), und jede Datei enthält den vollständigen Python/C++-Stack.
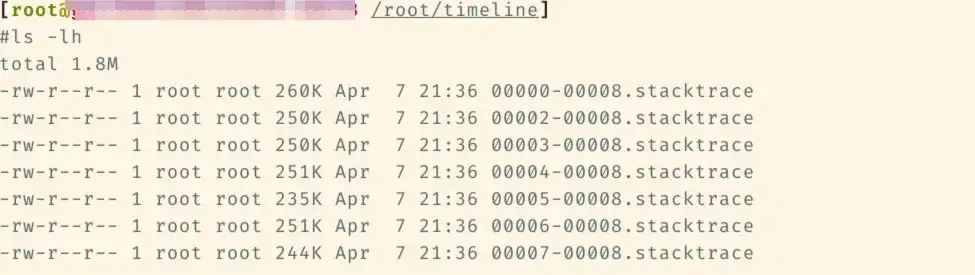
Der zusammengeführte Stapel sieht wie folgt aus, um die Kategorien des Stapels zu unterscheiden. Auf dem Python-Stack sind möglicherweise nur Cyan und Grün vorhanden:
- Cyan ist CPython/Python
- Rot steht für C/anderes System
- Grün ist Torch/NCCL
- Gelb ist C++

Der Python-Stack sieht wie folgt aus: Das blaue Blockdiagramm ist der spezifische Stack und die Benennungsregel lautet: func@source_path@stuck_rank|leak_rank
- func ist der aktuelle Funktionsname. Wenn gdb ihn nicht erhalten kann, wird er angezeigt.
- source_path, die SO/Quelladresse dieses Symbols im Prozess
- Stuck_rank stellt dar, welche Rangstapel hier eingegeben werden. Die aufeinanderfolgenden Rangnummern werden in Start-Ende gefaltet, z. B. Rang 0,1,2,3 -> 0-3
- Leak_rank stellt dar, welche Stapel hier nicht eingegeben wurden, und die Rangnummer wird hier ebenfalls gefaltet
Die Bedeutung im Bild ist also, dass Rang 0, Rang 2 bis 7 alle unter Synchronisierung hängen bleiben und Rang 1 nicht eingeht, sodass analysiert werden kann, dass ein Problem mit Rang 1 vorliegt (eigentlich ausgesetzt). Diese Informationen werden nur oben im Stapel hinzugefügt

Dementsprechend können Sie den Stapel von cpp sehen und sehen, dass der Hauptthread in der Synchronisierung feststeckt und schließlich in cuda.so hängen bleibt. Ohne diesen Stapel kann davon ausgegangen werden, dass Der Stapel, in dem sich __libc_start_main befindet, stellt den Einstiegspunkt des Prozesses dar.
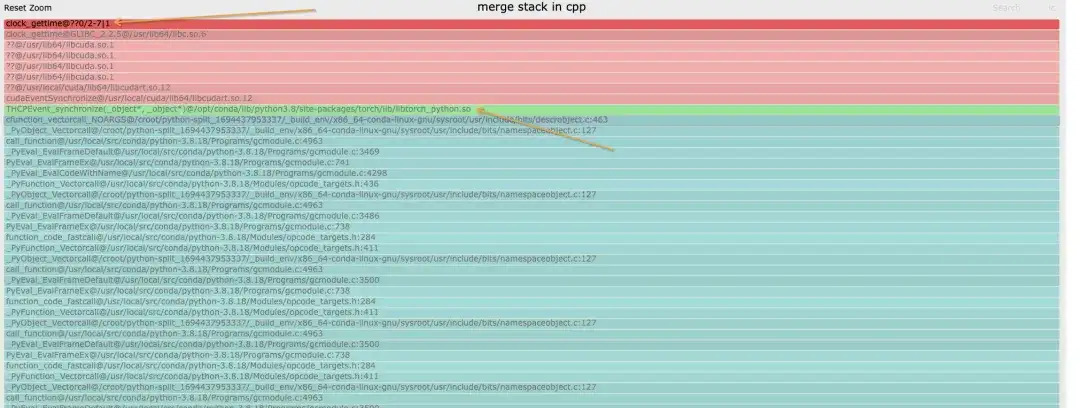
Im Allgemeinen kann davon ausgegangen werden, dass es nur einen tiefsten Link im Stapel gibt. Wenn eine Gabelung auftritt, beweist dies, dass unterschiedliche Ränge auf verschiedenen Links stecken.
Kernel-Call-Stack-Analyse
Im Gegensatz zur Torch-Timeline verfügt die Timeline nicht über einen Callstack. Beim Generieren der Timeline lautet der entsprechende Stapeldateiname tracing_kernel_stack.svg. Ziehen Sie diese Datei zur Beobachtung in Chrome.
- Grün ist der NCCL-Betrieb
- Das rote ist die Matmul-Operation
- Der Cyan-Stack ist der Python-Stack

Grafana-Marktanzeige
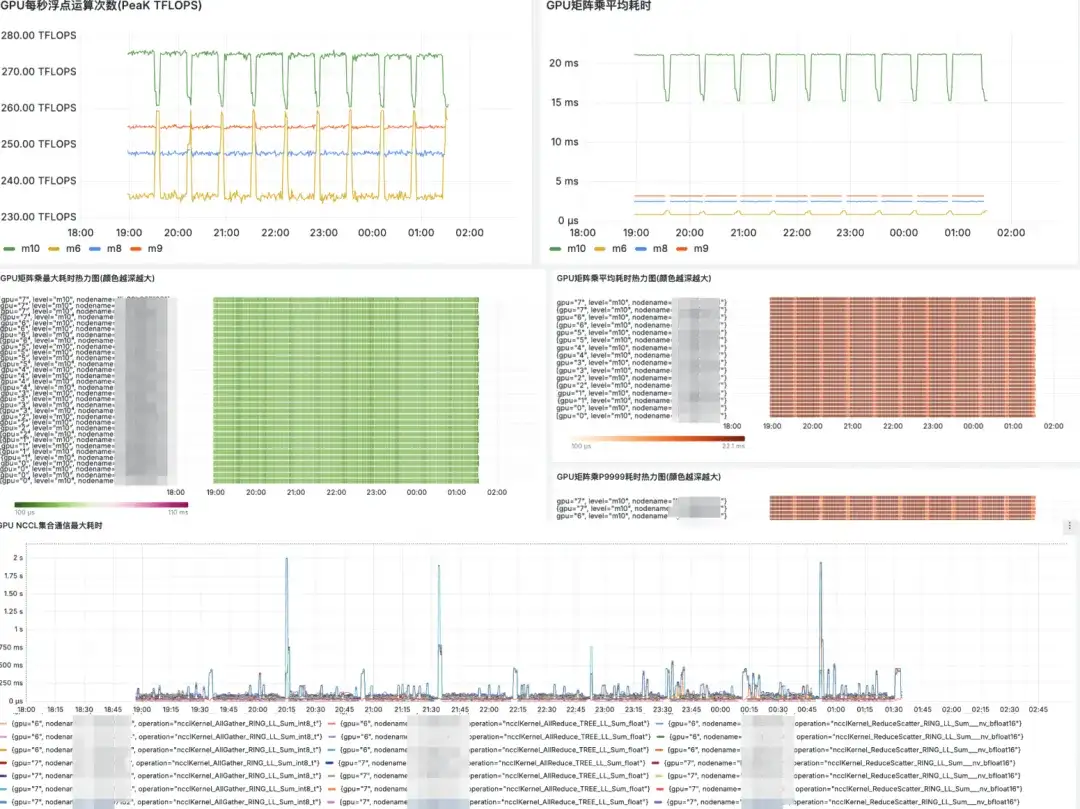
Zukunftsplan
- Fügen Sie eine detailliertere Ablaufverfolgung wie NCCL/eBPF hinzu, um die Grundursache von Hängeproblemen während des Trainings genauer zu analysieren und zu diagnostizieren.
- Unterstützt weitere Hardwareplattformen, einschließlich verschiedener inländischer Grafikkarten.
Über DLRover
DLRover (Distributed Deep Learning System) ist eine Open-Source-Community, die vom Team der Ant Group AI Infra verwaltet wird. Es handelt sich um ein intelligentes verteiltes Deep-Learning-System, das auf Cloud-nativer Technologie basiert. DLRover ermöglicht es Entwicklern, sich auf den Entwurf der Modellarchitektur zu konzentrieren, ohne sich mit technischen Details wie Hardwarebeschleunigung und verteiltem Betrieb befassen zu müssen. Darüber hinaus werden Algorithmen im Zusammenhang mit Deep-Learning-Training entwickelt, um das Training effizienter und intelligenter zu gestalten, beispielsweise mit Optimierern. Derzeit unterstützt DLRover den Einsatz von K8s und Ray für den automatisierten Betrieb und die Wartung von Deep-Learning-Trainingsaufgaben. Für weitere KI-Infra-Technologie beachten Sie bitte das DLRover-Projekt.
Treten Sie der Technologieaustauschgruppe DLRover DingTalk bei: 31525020959
DLRover Star:
https://github.com/intelligent-machine-learning/dlrover
Artikelempfehlungen
