
Anmerkung des Herausgebers: Als der Autor seiner Mutter beizubringen versuchte, LLM zur Erledigung von Arbeitsaufgaben zu nutzen, wurde ihr klar, dass die Optimierung von Aufforderungswörtern nicht so einfach war, wie man es sich vorgestellt hatte. Die automatische Optimierung von Aufforderungswörtern ist für unerfahrene Aufforderungswortschreiber wertvoll, die nicht über genügend Erfahrung verfügen, um die dem Modell bereitgestellten Aufforderungswörter anzupassen und zu verbessern , was zu einer weiteren Erforschung automatischer Tools zur Optimierung von Aufforderungswörtern geführt hat.
Der Autor dieses Artikels analysiert die Natur des Prompt Word Engineering aus zwei Perspektiven: Es kann als Teil der Hyperparameteroptimierung betrachtet werden, oder es kann als ein Prozess des Erkundens, Ausprobierens und Korrigierens betrachtet werden, der ständige Versuche und Anpassungen erfordert .
Der Autor glaubt, dass für Aufgaben mit relativ klarer Modelleingabe und -ausgabe, wie z. B. das Lösen mathematischer Probleme, die Klassifizierung von Emotionen und das Generieren von SQL-Anweisungen usw. Der Autor glaubt, dass Prompt Word Engineering in diesem Fall eher der Optimierung eines „Parameters“ gleicht, genau wie der Anpassung von Hyperparametern beim maschinellen Lernen. Mit automatisierten Methoden können wir ständig verschiedene Aufforderungswörter ausprobieren, um herauszufinden, welches am besten funktioniert. Für Aufgaben, die relativ subjektiv und vage sind, wie das Schreiben von E-Mails, Gedichten, Artikelzusammenfassungen usw. Da es keinen Schwarz-Weiß-Standard gibt, um zu beurteilen, ob die Ausgabe „korrekt“ ist, kann die Optimierung von Aufforderungswörtern nicht einfach und mechanisch durchgeführt werden.
Der ursprüngliche Artikellink: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Link zum LinkedIn-Profil: https://linkedin.com/in/ianhojy
Link zum mittleren Profil für Abonnements: https://ianhojy.medium.com/
Autor |. Ian Ho
Zusammengestellt |. Yue Yang
In den letzten Monaten habe ich versucht, verschiedene LLM-basierte Apps zu erstellen. Um ehrlich zu sein, verbringe ich einen Großteil meiner Zeit damit, Prompt zu verbessern, um die Ergebnisse zu erhalten, die ich von LLM haben möchte.
Oft steckte ich in Leere und Verwirrung fest und fragte mich, ob ich nur ein verherrlichter Schnellingenieur war. Angesichts des aktuellen Stands der menschlichen Interaktion mit LLMs (Large Language Models) neige ich immer noch zu dem Schluss: „Noch nicht“ und ich schaffe es in den meisten Nächten, mein Hochstapler-Syndrom zu überwinden. (Anmerkung des Übersetzers: Es handelt sich um ein psychologisches Phänomen, das sich auf Personen bezieht, die ihren eigenen Leistungen und Fähigkeiten skeptisch gegenüberstehen. Sie haben oft das Gefühl, ein Lügner zu sein, glauben, dass sie es nicht wert sind, die erreichten Erfolge zu haben oder zu erreichen, und das sind sie auch Ich habe Angst, entlarvt zu werden.) Derzeit werden wir dieses Thema vorerst nicht ausführlich besprechen.
Aber ich frage mich immer noch oft, ob der Prozess des Schreibens von Prompts eines Tages grundsätzlich automatisiert werden kann. Die Beantwortung dieser Frage hängt davon ab, ob Sie die wahre Natur des Prompt Engineering verstehen können.
Obwohl es im riesigen Internet unzählige Anleitungen zum Thema „Prompt Engineering“ gibt, kann ich mich immer noch nicht entscheiden, ob „Prompt Engineering“ eine Kunst oder eine Wissenschaft ist.
Einerseits fühlt es sich wie eine Kunst an, wenn ich die Eingabeaufforderungen, die ich schreibe, immer wieder lernen und verfeinern muss , basierend auf dem, was ich bei der Modellausgabe beobachte . Mit der Zeit habe ich herausgefunden, dass kleine Details wichtig sind – wie die Verwendung von „muss“ anstelle von „sollte“ oder das Hinzufügen von Leitlinien, Empfehlungen oder Spezifikationen) am Ende des Aufforderungsworts und nicht in der Mitte. Abhängig von der Aufgabe gibt es so viele Möglichkeiten, eine Reihe von Anweisungen und Richtlinien auszudrücken, dass es sich manchmal wie ein ständiges Ausprobieren anfühlt und Fehler macht.
Andererseits könnte man denken, dass Aufforderungswörter nur Hyperparameter sind. Letztlich behandelt LLM (Large Language Model) eigentlich nur die von uns geschriebenen Eingabeaufforderungswörter als Einbettungen, genau wie alle Hyperparameter. Wenn wir über einen vorbereiteten und genehmigten Datensatz zum Trainieren und Testen von Modellen für maschinelles Lernen verfügen, können wir Anpassungen an den Eingabeaufforderungswörtern vornehmen und ihre Leistung objektiv bewerten. Kürzlich habe ich einen Beitrag von Moritz Laurer, ML-Ingenieur bei HuggingFace[1], gesehen:
Jedes Mal, wenn Sie eine andere Eingabeaufforderung an Ihren Daten testen, werden Sie unsicherer, ob das LLM tatsächlich auf unsichtbare Daten verallgemeinert. Die Verwendung einer separaten Validierungsaufteilung zur Optimierung des Haupthyperparameters von LLMs (der Eingabeaufforderung) ist genauso wichtig wie der Train-Val-Test Aufteilung zur Feinabstimmung. Der einzige Unterschied besteht darin, dass Sie keinen Trainingsdatensatz mehr haben und es sich irgendwie anders anfühlt, weil es kein Training/keine Parameteraktualisierungen gibt. Es ist leicht, sich selbst vorzutäuschen, dass ein LLM Ihre Aufgabe gut erfüllt, während Sie die Eingabeaufforderung Ihrer Daten tatsächlich überbewertet haben. In jedem guten „Zeroshot“-Papier sollte klargestellt werden, dass vor dem endgültigen Testen ein Validierungssplit verwendet wurde, um die Eingabeaufforderung zu finden.
Da wir immer mehr verschiedene Eingabeaufforderungswörter (Prompts) an diesen Datensätzen testen, werden wir immer unsicherer, ob LLM wirklich auf unsichtbare Daten verallgemeinern kann ... Isolieren Sie einen Teil des Datensatzes. Legen Sie ihn als Validierungssatz fest, um die Haupthyperparameter anzupassen (Eingabeaufforderung) von LLM und die Verwendung der Train-Val-Test-Splitting-Methode (Anmerkung des Übersetzers: Teilen Sie den verfügbaren Datensatz in drei Teile: Trainingssatz, Validierungssatz und Testsatz). Die Feinabstimmung ist ebenso wichtig. Der einzige Unterschied besteht darin, dass dieser Prozess kein Training des Modells (kein Training) oder eine Aktualisierung der Modellparameter (keine Parameteraktualisierungen) umfasst, sondern nur die Bewertung der Leistung verschiedener Eingabeaufforderungswörter im Validierungssatz. Es ist leicht, sich selbst vorzutäuschen, dass das LLM bei der Zielaufgabe gut funktioniert, obwohl die abgestimmten Stichworte bei diesem aktuellen Datensatz möglicherweise sehr gut funktionieren, bei einem breiteren oder unsichtbaren Datensatz jedoch möglicherweise nicht. In jedem guten „Zeroshot“-Papier sollte klar angegeben werden, dass ein Validierungssatz verwendet wird, um vor dem endgültigen Testen die besten Eingabeaufforderungen zu finden.
Nach einigem Nachdenken denke ich, dass die Antwort irgendwo dazwischen liegt. Ob Prompt Engineering eine Wissenschaft oder eine Kunst ist, hängt davon ab, was wir von LLM erwarten. Wir haben LLM im letzten Jahr viele erstaunliche Dinge tun sehen, aber ich neige dazu, die Absichten der Menschen, große Modelle zu verwenden, in zwei große Kategorien einzuteilen: Probleme lösen und kreative Aufgaben erledigen (schaffen).
Auf der Problemlösungsseite haben wir LLMs, die mathematische Probleme lösen, Stimmungen klassifizieren, SQL-Anweisungen generieren, Texte übersetzen und so weiter. Im Allgemeinen denke ich, dass diese Aufgaben alle in Gruppen zusammengefasst werden können, da sie relativ klare Eingabe-Ausgabe-Paare haben können (Anmerkung des Übersetzers: Die Zuordnung zwischen Eingabedaten und entsprechenden Modellausgabedaten) (daher können wir viele Fälle sehen, in denen verwendet wird Nur eine kleine Anzahl von Eingabeaufforderungen kann die Zielaufgabe sehr gut erfüllen. Für diese Art von Aufgabe mit klar definierten Trainingsdaten (Anmerkung des Übersetzers: Die Beziehung zwischen Eingabe und Ausgabe im Trainingsdatensatz ist klar und deutlich) scheint mir Prompt Engineering eher eine Wissenschaft zu sein. Daher wird in der ersten Hälfte dieses Artikels Prompt als Hyperparameter erörtert und insbesondere der Forschungsfortschritt der automatisierten Prompt-Engineering untersucht (Anmerkung des Übersetzers: Verwendung automatisierter Methoden oder Technologien zum Entwerfen, Optimieren und Anpassen von Prompt-Wörtern).
In Bezug auf kreative Aufgaben sind die Aufgaben, die LLM erfordert, subjektiver und mehrdeutiger. Schreiben Sie E-Mails, Berichte, Gedichte, Abstracts. Hier stoßen wir auf mehr Unklarheiten – ist der Inhalt der Texte von ChatGPT unpersönlich? (Basierend auf den Tausenden von Artikeln, die ich darüber geschrieben habe, ist meine aktuelle Meinung „Ja“) Und da uns oft ein objektiveres Kriterium dafür fehlt, wie LLMs reagieren sollen, sind die Art und Anforderungen kreativer Aufgaben oft nicht angemessen Stellen Sie sich Stichworte als Parameter vor, die wie Hyperparameter angepasst und optimiert werden können.
An dieser Stelle könnten einige sagen, dass wir für kreative Aufgaben einfach den gesunden Menschenverstand einsetzen müssen. Ehrlich gesagt dachte ich das auch, bis ich versuchte, meiner Mutter beizubringen, wie man ChatGPT nutzt, um geschäftliche E-Mails zu generieren. Da es beim Prompt Engineering in diesen Fällen immer noch hauptsächlich um Verbesserungen durch kontinuierliches Experimentieren und Anpassen und nicht um eine einmalige Fertigstellung geht, wie können Sie Ihre eigenen Ideen nutzen, um Prompt zu verbessern und dennoch die Universalität von Prompt zu bewahren (wie im vorherigen Zitat erwähnt)? ), ist nicht immer offensichtlich.
Wie auch immer, ich habe mich nach einem Tool umgesehen, das Eingabeaufforderungen basierend auf Benutzerfeedback zu großen modellgenerierten Beispielen automatisch verbessern kann, aber nichts gefunden. Deshalb habe ich einen Prototyp eines solchen Tools gebaut, um zu untersuchen, ob es eine praktikable Lösung gibt. Später in diesem Artikel werde ich Ihnen ein Tool vorstellen, mit dem ich experimentiert habe und das Aufforderungswörter basierend auf Benutzerfeedback in Echtzeit automatisch verbessert.
01 Teil 1 – LLMs als Löser: Behandeln Sie Prompt Engineering als Teil der Hyperparameteroptimierung
Viele Leute in der Branche sind mit der berühmten „Zero-Shot-COT“-Terminologie aus dem Artikel „Large Language Models are Zero-Shot Reasoners“ [2] vertraut (Anmerkung des Übersetzers: Das Modell hat keine expliziten Trainingsdaten für eine bestimmte Aufgabe gelernt . Als nächstes lösen Sie neue Probleme, indem Sie vorhandenes Wissen kombinieren. Zhou et al. (2022) beschlossen, in dem Artikel „Große Sprachmodelle sind schnelle Ingenieure auf menschlicher Ebene“ [3] näher zu untersuchen. Was ist die verbesserte Version? —— „Lass uns das Schritt für Schritt klären, um sicherzustellen, dass wir die richtige Antwort haben.“ Im Folgenden finden Sie einen Überblick über die von ihnen vorgeschlagene Methode des Automatic Prompt Engineer:
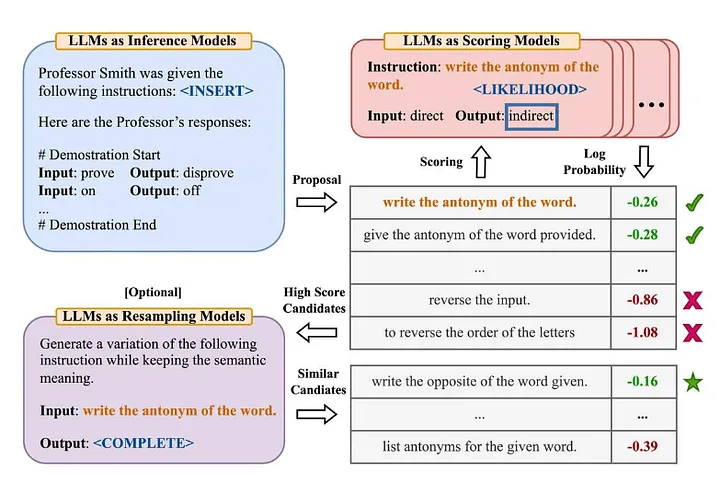
Quelle: Große Sprachmodelle sind schnelle Ingenieure auf menschlicher Ebene[3]
Um dieses Papier zusammenzufassen:
- Verwenden Sie LLM, um Kandidatenberatungsaufforderungen basierend auf bestimmten Eingabe-Ausgabe-Paaren zu generieren (Anmerkung des Übersetzers: Die Zuordnung zwischen Eingabedaten und entsprechenden Modellausgabedaten).
- Verwenden Sie LLM, um jede Anweisungsaufforderung zu bewerten, entweder basierend darauf, wie gut die mit der Anweisung generierte Antwort mit der erwarteten Antwort übereinstimmt, oder basierend auf der mit der Anweisung erhaltenen Modellantwort, um die logarithmische Wahrscheinlichkeit auszuwerten.
- Neue Aufforderungswörter für die Kandidatenberatung werden iterativ auf der Grundlage von Eingabeaufforderungswörtern (Anweisungen) für die Kandidatenberatung mit hoher Punktzahl generiert.
Es wurden einige interessante Schlussfolgerungen gezogen:
- Zusätzlich zum Nachweis der überlegenen Leistung von (menschlichen Prompt-Ingenieuren) und zuvor vorgeschlagenen Algorithmen stellen die Autoren fest: „Das Hinzufügen von Beispielen im Kontext beeinträchtigt intuitiv die Modellleistung … weil alle ausgewählten Befehlswörter zu sehr zum Zero-Shot-Lernszenario passen und daher eine schlechte Leistung erbringen.“ bei kleinen Proben (wenige Schüsse) .
- Die Wirkung des iterativen Monte-Carlo-Suchalgorithmus (Monte-Carlo-Suche) wird in den meisten Fällen allmählich schwächer, aber wenn der ursprüngliche Vorschlagsraum (Anmerkung des Übersetzers: Kann sich auf den Monte-Carlo-Suchalgorithmus beziehen, der ursprünglich zum Generieren von Kandidaten verwendet wurde) Es funktioniert gut, wenn der Der anfängliche Umfang oder die Lösung des Problems ist nicht geeignet oder effektiv genug.
Im Jahr 2023 führten einige Forscher von Google DeepMind dann eine Methode namens „Optimisation by Prompting (OPRO)“ ein. Ähnlich wie im vorherigen Beispiel enthält die Meta-Eingabeaufforderung eine Reihe von Eingabe-/Ausgabepaaren (Anmerkung des Übersetzers: Die Eingabe und Erwartungen, die eine bestimmte Aufgaben- oder Problemausgabekombination beschreiben). Der Hauptunterschied besteht darin, dass die Meta-Eingabeaufforderung auch zuvor trainierte Eingabeaufforderungswortbeispiele und ihre richtigen Antworten oder Lösungen enthält und wie genau das Modell diese Eingabeaufforderungswörter beantwortet hat. Außerdem werden die Unterschiede zwischen den verschiedenen Teilen der Meta-Eingabeaufforderungs-Leitwörter detailliert beschrieben für Beziehungen.
Wie die Autoren erklären, generiert jeder Schritt der Stichwortoptimierung in der Forschungsarbeit neue Stichworte, die auf frühere Lernverläufe verweisen sollen, damit das Modell die aktuelle Aufgabe besser verstehen und genauere Ausgabeergebnisse liefern kann.
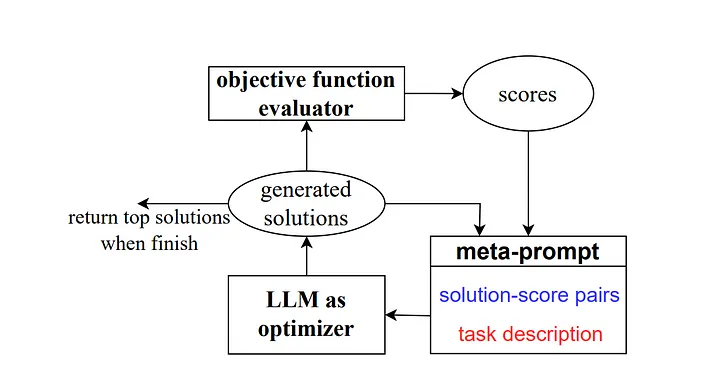
Quelle: Große Sprachmodelle als Optimierer[4]
Für das Zero-Shot-COT-Szenario schlugen sie die Prompt-Word-Optimierungsmethode „Atmen Sie tief durch und arbeiten Sie Schritt für Schritt an diesem Problem“ vor und erzielten gute Ergebnisse.
Dazu habe ich ein paar Gedanken:
- „Die Stile der von verschiedenen Arten von Sprachmodellen generierten Anleitungsaufforderungen variieren stark. Einige Modelle, wie PaLM 2-L-IT und text-bison, erzeugen sehr prägnante und klare Anleitungsaufforderungen, während andere, wie etwa GPTs, langwierig sind.“ sehr detailliert. „Das verdient unsere Aufmerksamkeit.“ Derzeit werden viele Prompt-Engineering-Methoden auf dem Markt unter Verwendung des OpenAI-Sprachmodells als Referenzobjekt geschrieben. Da jedoch immer mehr Modelle aus verschiedenen Quellen verwendet werden, sollten wir auf diese gängigen Prompt-Engineering-Richtlinien achten so gut. In Abschnitt 5.2.3 des Papiers wird ein Beispiel gegeben, das die hohe Empfindlichkeit der Modellleistung gegenüber kleinen Änderungen in Anweisungen zeigt. Wir müssen dem mehr Aufmerksamkeit schenken.
Bei der Verwendung von PaLM 2-L zur Bewertung des Modells auf dem GSM8K-Testsatz erreichte die Genauigkeit von „Lass uns Schritt für Schritt denken“ 71,8 % und die Genauigkeit von „Lass uns das Problem gemeinsam lösen“. während die ersten beiden Die semantische Kombination der Anweisungswörter „Lasst uns zusammenarbeiten, um dieses Problem Schritt für Schritt zu lösen“ hat eine Genauigkeit von nur 49,4 %.
Dieses Verhalten erhöht sowohl die Variation zwischen Einzelschrittanweisungen als auch die Schwankungen, die während des Optimierungsprozesses auftreten, was uns dazu veranlasst, bei jeder Schrittanweisungen mehrere Einzelschrittanweisungen zu generieren, um die Stabilität des Optimierungsprozesses zu verbessern.
Ein weiterer wichtiger Punkt wird in der Schlussfolgerung des Papiers erwähnt: „Eine Einschränkung unserer aktuellen Anwendung von Algorithmen auf reale Probleme besteht darin, dass die großen Sprachmodelle, die zur Optimierung von Stichworten verwendet werden, die fehlerhaften Fälle im Trainingssatz nicht effektiv ausnutzen, um daraus abzuleiten.“ vielversprechend Im Experiment haben wir versucht, Fehlerfälle hinzuzufügen, die beim Trainieren oder Testen des Modells in der Meta-Eingabeaufforderung auftraten, anstatt in jedem Optimierungsschritt zufällig Stichproben aus dem Trainingssatz zu ziehen, aber die Ergebnisse waren ähnlich, was zeigte, dass nur Die Die Informationsmenge in diesen Fehlerfällen reicht für den Optimierer LLM (ein großes Sprachmodell zur Optimierung von Eingabeaufforderungswörtern) nicht aus, um die Gründe für die falschen Vorhersagen zu verstehen. „Dies ist in der Tat hervorzuheben, denn obwohl diese Methoden starke Beweise dafür liefern Optimierungsprozess von Eingabeaufforderungswörtern Ähnlich dem Hyperparameter-Optimierungsprozess in traditioneller ML/KI, aber wir neigen dazu, positive, positive Beispiele zu verwenden, unabhängig davon, welche Art von Inhaltseingabe wir LLM bereitstellen möchten oder wie wir LLM anleiten Verbessern Sie die Aufforderungswörter. Bei traditionellem ML/KI ist diese Präferenz jedoch normalerweise nicht so offensichtlich, und wir konzentrieren uns mehr darauf, wie die Fehlerinformationen zur Optimierung des Modells verwendet werden, anstatt der Richtung oder Art des Fehlers selbst zu viel Aufmerksamkeit zu schenken (d. h. Wir konzentrieren uns auf -5- und +5-Fehler, die größtenteils gleich behandelt werden.
Wenn Sie sich für APE (Automated Prompt Engineering) interessieren, können Sie es unter https://github.com/keirp/automatic_prompt_engineer herunterladen und verwenden.
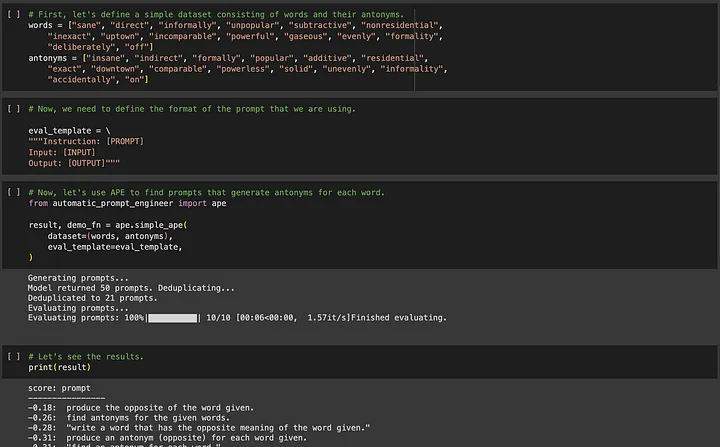
Quelle: Screenshot aus dem Beispielnotizbuch für APE[5]
Eine wichtige Anforderung bei beiden Methoden, APE und OPRO, besteht darin, dass Trainingsdaten zur Optimierung vorhanden sein müssen und der Datensatz groß genug sein muss, um die Universalität der optimierten Stichworte sicherzustellen.
Jetzt möchte ich über eine andere Art von LLM-Aufgabe sprechen, bei der wir möglicherweise nicht über leicht verfügbare Daten verfügen.
02 Teil 2 – LLMs als Schöpfer: Betrachten Sie Prompt Engineering als einen Prozess der schrittweisen Verbesserung durch ständiges Ausprobieren und Anpassen
Angenommen, wir würden uns jetzt ein paar Kurzgeschichten ausdenken.
Wir haben einfach keine Romantextbeispiele, an denen wir das Modell trainieren können, und es würde zu lange dauern, einige qualifizierte Romantextbeispiele zu schreiben. Darüber hinaus ist mir nicht klar, ob es sinnvoll ist, bei einem großen Modell eine „sogenannte richtige“ Antwort auszugeben, da es viele Arten von Modellausgaben geben kann, die akzeptabel sind. Daher ist es für diese Art von Aufgabe nahezu unpraktisch, Methoden wie APE zu verwenden, um die Eingabeaufforderungswortentwicklung zu automatisieren.
Einige Leser fragen sich jedoch möglicherweise: Warum müssen wir den Prozess des Schreibens von Aufforderungswörtern überhaupt automatisieren? Sie können mit einem beliebigen einfachen Aufforderungswort beginnen, z. B. „Stellen Sie mir drei Ideen für Kurzgeschichten über {{issue}} in zur {{country}}Verfügung“, füllen Sie {{Problem}} mit „Ungleichheit“, ersetzen Sie {{Land}} durch „Singapur“ und beobachten Sie das Antwortmodell Vergleichen Sie die Ergebnisse, entdecken Sie Probleme, passen Sie die Aufforderungswörter an, beobachten Sie dann, ob die Anpassung wirksam ist, und wiederholen Sie diesen Vorgang.
Aber wer profitiert in diesem Fall am meisten vom Cue-Word-Engineering? Gerade Anfänger, die keine Erfahrung im Schreiben von Aufforderungswörtern haben, verfügen nicht über genügend Erfahrung, um die bereitgestellten Aufforderungswörter anzupassen und zu verbessern . Ich habe dies aus erster Hand erfahren, als ich meiner Mutter beigebracht habe, ChatGPT zum Erledigen von Arbeitsaufgaben zu verwenden.
Meine Mutter ist vielleicht nicht sehr gut darin, ihre Unzufriedenheit mit den Ergebnissen von ChatGPT in weitere Verbesserungen von Prompt Words umzuwandeln, aber ich habe erkannt, dass wir, egal wie gut unsere Fähigkeiten im Bereich Prompt Word Engineering sind, wirklich gut darin sind, die Probleme zu artikulieren, die wir haben sehen (d. h. die Fähigkeit, sich zu beschweren). Deshalb habe ich versucht, ein Tool zu entwickeln, das Benutzern hilft, ihre Beschwerden zu äußern, und LLM die Aufforderungsworte für uns verbessern zu lassen. Für mich scheint dies eine natürlichere Art der Interaktion zu sein und es für diejenigen von uns, die LLM für kreative Aufgaben nutzen möchten, einfacher zu machen.
Es sollte vorab darauf hingewiesen werden, dass es sich lediglich um einen Proof-of-Concept handelt. Wenn Leser also gute Ideen haben, können sie diese gerne mit dem Autor teilen!
Schreiben Sie zunächst das Eingabeaufforderungswort mit {{}}-Variablen. Das Tool erkennt diese Platzhalter, damit wir sie später ausfüllen können, wiederum anhand des obigen Beispiels, und fordert das große Modell auf, einige kreative Geschichten über Ungleichheit in Singapur auszugeben.
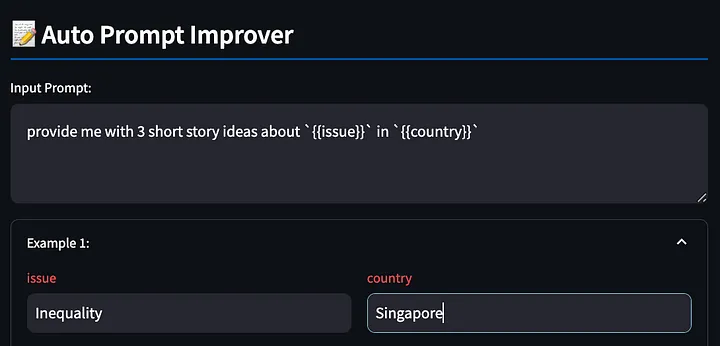
Als nächstes generiert das Tool eine Modellantwort basierend auf den ausgefüllten Eingabeaufforderungswörtern.

Dann geben Sie unser Feedback (Beschwerden über die Modellausgabe):
Das Modell wurde dann gebeten, die Generierung weiterer Beispiele für Story-Ideen einzustellen und Stichworte auszugeben, die sich gegenüber der ersten Iteration verbessert hatten. Bitte beachten Sie, dass die unten aufgeführten Aufforderungen verfeinert und verallgemeinert wurden und nun erfordern: „Beschreiben Sie die Strategien … zur Bewältigung oder Bewältigung dieser Herausforderungen.“ Und mein Feedback zur ersten Modellausgabe lautete: „Sprechen Sie darüber, wie der Protagonist der Geschichte Ungleichheit löst.“

Anschließend baten wir das große Modell, sich die Kurzgeschichte noch einmal auszudenken und dabei die modifizierten Aufforderungswörter zu verwenden.
Wir haben auch die Möglichkeit, auf „Nächstes Beispiel generieren“ zu klicken, um eine neue Modellantwort basierend auf anderen Eingabevariablen zu generieren. Hier sind einige generierte kreative Geschichten über das Entlassungsproblem in China:
Geben Sie dann Feedback zur obigen Modellausgabe:
Anschließend wurden die Aufforderungsworte weiter optimiert:

Die Optimierungsergebnisse sehen dieses Mal ziemlich gut aus. Schließlich war es zunächst nur ein einfaches Eingabeaufforderungswort. Nach weniger als zwei Minuten (wenn auch etwas beiläufigem) Feedback wurde das optimierte Eingabeaufforderungswort nach drei Iterationen erhalten. Jetzt können wir die Aufforderungswörter weiter optimieren, indem wir uns einfach hinsetzen und unsere Unzufriedenheit mit der LLM-Ausgabe zum Ausdruck bringen.
Die interne Implementierung dieser Funktion besteht darin, von der Meta-Eingabeaufforderung auszugehen und basierend auf dem dynamischen Feedback des Benutzers kontinuierlich neue Eingabeaufforderungswörter zu optimieren und zu generieren. Es ist nichts Besonderes und es gibt definitiv Raum für weitere Verbesserungen, aber es ist ein guter Anfang.
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
Einige Beobachtungen bei der Verwendung dieses Tools:
- GPT4 neigt dazu, beim Generieren von Text eine große Anzahl von Wörtern zu verwenden (die „Polyglotten“-Funktion). Aus diesem Grund kann es zwei Effekte geben. Erstens kann diese „ausführliche“ Eigenschaft eine Überanpassung an bestimmte Beispiele fördern . ** Wenn LLM zu viele Wörter erhält, werden diese verwendet, um spezifisches Feedback des Benutzers zu korrigieren. Zweitens kann diese „verbale“ Eigenschaft die Wirksamkeit von Aufforderungswörtern beeinträchtigen, insbesondere bei langen Aufforderungswörtern können einige wichtige Leitinformationen verdeckt werden. Ich denke, das erste Problem lässt sich lösen, indem man gute Meta-Eingabeaufforderungen schreibt, um das Modell zur Verallgemeinerung auf der Grundlage von Benutzerfeedback zu ermutigen. Das zweite Problem ist jedoch schwieriger. In anderen Anwendungsfällen werden lehrreiche Eingabeaufforderungen häufig ignoriert, wenn das Eingabeaufforderungswort zu lang ist. Wir können der Meta-Eingabeaufforderung einige Einschränkungen hinzufügen (z. B. die Anzahl der Wörter im oben bereitgestellten Eingabeaufforderungsbeispiel begrenzen) , dies ist jedoch wirklich willkürlich und einige Einschränkungen oder Regeln in den Eingabeaufforderungswörtern können durch das zugrunde liegende große Modell beeinflusst werden. Die Auswirkung eines bestimmten Attributs oder Verhaltens.
- Verbesserte Aufforderungswörter vergessen manchmal frühere Optimierungen des Aufforderungsworts. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, dem System eine längere Verbesserungshistorie zur Verfügung zu stellen. Dies führt jedoch dazu, dass die Aufforderungswörter zur Verbesserung zu lang werden.
- Ein Vorteil dieses Ansatzes in der ersten Iteration besteht darin, dass das LLM möglicherweise Anleitungen für Verbesserungen bietet, die nicht Teil des Benutzerfeedbacks sind. Im ersten Wort „Optimierung“ oben fügte das Tool beispielsweise „Bieten Sie eine breitere Perspektive auf das besprochene Problem …“ hinzu, obwohl ich bei „Feedback“ lediglich eine Anfrage nach relevanten Statistiken aus zuverlässigen Quellen gestellt habe.
Ich habe dieses Tool noch nicht bereitgestellt, da ich immer noch an der Meta-Eingabeaufforderung arbeite, um herauszufinden, was am besten funktioniert, einige der Streamlit-Framework-Probleme zu umgehen und dann andere Fehler oder Ausnahmen zu behandeln, die im Programm auftreten können. Aber das Tool sollte bald live sein!
03 Abschließend
Der gesamte Bereich des Prompt Engineering konzentriert sich darauf, die besten Prompt-Wörter zur Lösung von Aufgaben bereitzustellen. APE und OPRO sind die wichtigsten und herausragendsten Beispiele in diesem Bereich, aber sie repräsentieren nicht alle. Wir sind gespannt und freuen uns darauf, welche Fortschritte wir in Zukunft auf diesem Gebiet machen können. Die Bewertung der Auswirkungen dieser Techniken auf verschiedene Modelle kann die Arbeitstendenzen oder Arbeitsmerkmale dieser Modelle aufdecken und uns auch helfen zu verstehen, welche Meta-Prompt-Techniken effektiv sind. Daher denke ich, dass dies sehr wichtige Aufgaben sind, die uns bei der Verwendung von LLM helfen werden in unserer täglichen Produktionspraxis.
Allerdings sind diese Methoden möglicherweise nicht für andere geeignet, die LLM für kreative Aufgaben nutzen möchten. Im Moment gibt es viele vorhandene Lernhandbücher, die uns den Einstieg erleichtern können, aber nichts geht über Versuch und Irrtum. Kurzfristig denke ich daher , dass das Wertvollste darin besteht, wie wir diesen experimentellen Prozess effizient abschließen können, der unseren menschlichen Stärken entspricht (Feedback geben) und LLM den Rest erledigen lässt (Verbesserung der prompten Worte).
Ich werde auch weiter an meinem POC (Proof of Concept) arbeiten. Wenn Sie daran interessiert sind, kontaktieren Sie mich bitte ( https://www.linkedin.com/in/ianhojy/) !
Danke fürs Lesen!
ENDE
Verweise
[1] https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2] https://arxiv.org/pdf/2205.11916.pdf
[3] https://arxiv.org/pdf/2211.01910.pdf
[4] https://arxiv.org/pdf/2309.03409.pdf
[5] https://github.com/keirp/automatic_prompt_engineer
[6] https://arxiv.org/abs/2104.08691
[7] https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8] https://www.promptingguide.ai/techniques/ape
Dieser Artikel wurde von Baihai IDP mit Genehmigung des ursprünglichen Autors zusammengestellt. Wenn Sie die Übersetzung erneut drucken müssen, kontaktieren Sie uns bitte für die Genehmigung.
Ursprünglicher Link:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Ich habe beschlossen, Open-Source-Hongmeng aufzugeben . Wang Chenglu, der Vater von Open-Source-Hongmeng: Open-Source-Hongmeng ist die einzige Architekturinnovations- Industriesoftwareveranstaltung im Bereich Basissoftware in China – OGG 1.0 wird veröffentlicht, Huawei steuert den gesamten Quellcode bei Google Reader wird vom „Code-Scheißberg“ getötet Fedora Linux 40 wird offiziell veröffentlicht Ehemaliger Microsoft-Entwickler: Windows 11-Leistung ist „lächerlich schlecht“ Ma Huateng und Zhou Hongyi geben sich die Hand, um „Groll zu beseitigen“ Namhafte Spielefirmen haben neue Vorschriften erlassen : Hochzeitsgeschenke für Mitarbeiter dürfen 100.000 Yuan nicht überschreiten Ubuntu 24.04 LTS offiziell veröffentlicht Pinduoduo wurde wegen unlauteren Wettbewerbs zu einer Entschädigung von 5 Millionen Yuan verurteilt