
Inhaltsverzeichnis
1. Der Knoten ist offline oder außer Betrieb
1.1 Unterscheiden Sie den Unterschied zwischen Knoten offline und Knoten stillgelegt
1.2 Umgang mit verschiedenen Stürmen, wenn Knoten offline gehen
1.2.1 Datanode-Blockreplikation
1.2.2 Kontrollknoten-Offline-RPC-Sturmparameter
2. So gehen Sie schnell offline
1. Der Knoten ist offline oder außer Betrieb
Hintergrund: 5 Datenknoten speichern etwa 11,2 Millionen 40-T-Datenblöcke, die Cluster-Bandbreite ist auf 200 M/s begrenzt und die Standard-Knotenkonfiguration beträgt 4*5 T.
1.1 Unterscheiden Sie den Unterschied zwischen Knoten offline und Knoten stillgelegt
Knotenstilllegung : Fügen Sie zuerst den Knoten normal zur Stilllegungsliste hinzu, sagen Sie zuerst dem Namensknoten und dem Garn, keine neuen Aufgaben zu senden und Daten zu schreiben; warten Sie dann, bis die Datenblöcke auf dem Knoten in den Cluster kopiert werden; zu diesem Zeitpunkt die stillgelegten Knoten ist die Priorität Als Datenquelle von srcNode (der stillgelegte Knoten wird als Replikationsdatenquelle src bevorzugt, da er keine Schreibanforderung hat und die Last gering ist) kopieren andere Knoten Datenblöcke von dem stillgelegten Knoten auf andere Knoten, daher wird die Last dieses Knotens zu diesem Zeitpunkt hoch sein. Nachdem alle Datenblöcke kopiert wurden, wird der Knotenstatus Decommissioned, was auf der Benutzeroberfläche angezeigt werden kann. Beachten Sie, dass die Außerbetriebnahmedaten des Datenknotens nach 10 Minuten und 30 Sekunden mit dem Kopieren beginnen, nicht weil es sich um eine aktive Außerbetriebnahme handelt, da der Nannode und der Datenknoten immer eine einfache Master-Slave-Beziehung aufrechterhalten und der Namenode-Knoten keinen IPC zum aktiv initiiert Datanode-Knotenaufruf, alle Operationen, die der Datanode-Knoten mit dem Namensknoten abschließen muss, werden von dem DatanodeCommand zurückgegeben, der in der Heartbeat-Antwort der beiden übertragen wird.

Knotentrennung: Zum Beispiel wird der Datenknoten zum Anhalten gezwungen, die physische Maschine hängt sich auf (z. B. Trennung bei hoher Last, plötzlicher Netzwerkausfall, Hardwarefehler usw.), dies sind alle Knotentrennungen, im Allgemeinen nach 10 Minuten und 30 Sekunden default (hauptsächlich von zwei Parametern gesteuert) namenode erkennt, dass die Knotenkommunikation abnormal getrennt wurde. Dann findet der Namenode alle Blockids des Knotens und der Maschine heraus, auf der sich das entsprechende Replikat gemäß der IP des Knotens befindet, und arrangiert die Datenreplikation durch den Heartbeat-Mechanismus. Zu diesem Zeitpunkt ist die Datenquelle der Datenreplikation noch nicht vorhanden der Offline-Knoten, aber eine von mehreren Repliken. Der Knoten, an dem sich die Kopie befindet, folgt zu diesem Zeitpunkt ebenfalls der Rack-Bewusstseins- und Kopienablagestrategie.
Schreiende Erinnerung: Der Unterschied zwischen Knoten offline und Außerbetriebnahme ist nicht nur die Datenreplikationsmethode, sondern auch die Datenreplikationsstrategie des Namensknotens für Under-Replicated Blocks (Datenblock-Replikationsebenen sind in 5 Typen unterteilt); In einem extremen Beispiel werden die Daten nicht verloren gehen, wenn ein Single-Copy-Knoten außer Betrieb genommen wird, aber wenn ein Single-Copy-Knoten offline geht, gehen die Daten tatsächlich verloren;
1.2 Umgang mit verschiedenen Stürmen, wenn Knoten offline gehen
Dutzende Terabytes oder sogar Hunderte Terabytes, Millionen Blöcke von Knoten werden offline gehen und eine große Anzahl von RPC-Stürmen wird auftreten.In unserem Cluster mit einer großen Anzahl kleiner Dateien ist es eine große Herausforderung für den Namenode, der wirkt sich nicht nur auf die Produktionsleistung aus, sondern birgt auch viele Probleme.Große versteckte Gefahr, insbesondere für Cluster mit begrenzten Bandbreitenengpässen. Im Allgemeinen beträgt der Wert für Namenode, um zu erkennen, ob der Datanode offline ist, 10*3s (Heartbeat-Zeit) + 2*5min (Namenode-Erkennungszeit, der Parameter ist: dfs.namenode.heartbeat.recheck-interval) = 10 Minuten 30s. Wenn die Bandbreite innerhalb von 10 Minuten und 30 Sekunden weiterhin voll ist, die RPC-Anforderung verzögert wird und die Kommunikation zwischen den Datenknoten- und Namenode-Knoten nicht reibungslos verläuft, können andere Knoten leicht dazu gebracht werden, weiterhin offline zu gehen, wodurch ein Teufelskreis entsteht Wie sollte diese Situation vermieden werden?
1.2.1 Datanode-Blockreplikation
NameNode verwaltet eine Replikationsprioritätswarteschlange, und die Dateiblöcke mit unzureichenden Replikaten werden priorisiert, und die Dateiblöcke mit nur einer Replik haben die höchste Replikationspriorität. Wenn Sie sich also von hier aus die beiden Kopien des Clusters ansehen, bleibt, solange in einem Block eine Anomalie vorliegt, nur eine Kopie übrig, nämlich der Block mit der höchsten Priorität, der im Storm-Modus kopiert wird. Wenn die Steuerung nicht gut ist, wird sie leicht die Leistung des Clusters beeinträchtigen oder sogar den Cluster hängen lassen. Daher wird im Allgemeinen nicht empfohlen, dass der Cluster-Replikationsfaktor 2 ist.
Die fünf Priority-Queues des folgenden Blocks sollen repliziert werden: Tatsächlich befindet sie sich in der privaten Methode getPriority von UnderReplicatedBlocks, die so aussieht:
/**HDFSversion-3.1.1.3.1, 保持低冗余块的优先队列*/
class LowRedundancyBlocks implements Iterable<BlockInfo> {
/** The total number of queues : {@value} */
static final int LEVEL = 5;
/** The queue with the highest priority: {@value} */
static final int QUEUE_HIGHEST_PRIORITY = 0;
/** The queue for blocks that are way below their expected value : {@value} */
static final int QUEUE_VERY_LOW_REDUNDANCY = 1;
/**
* The queue for "normally" without sufficient redundancy blocks : {@value}.
*/
static final int QUEUE_LOW_REDUNDANCY = 2;
/** The queue for blocks that have the right number of replicas,
* but which the block manager felt were badly distributed: {@value}
*/
static final int QUEUE_REPLICAS_BADLY_DISTRIBUTED = 3;
/** The queue for corrupt blocks: {@value} */
static final int QUEUE_WITH_CORRUPT_BLOCKS = 4;
/** the queues themselves */
private final List<LightWeightLinkedSet<BlockInfo>> priorityQueues
= new ArrayList<>(LEVEL);
}L1 (höchste) : Blöcke mit Datenverlustrisiko, wie: 1. Blöcke mit nur einer Kopie (insbesondere bei Blöcken mit 2 Kopien geht ein Knoten offline) oder diese Blöcke haben 0 aktive Kopien 2. Eine einzelne Kopie läuft Blöcke, die stillgelegten Knoten gehören.
L2: Der tatsächliche Wert der Blockkopie ist viel niedriger als der konfigurierte Wert (z. B. 3 Kopien, 2 fehlen), dh wenn die Anzahl der Kopien weniger als 1/3 des erwarteten Werts beträgt, werden diese Blöcke gelöscht von der zweiten Priorität kopiert. Beispielsweise werden bei einem Block mit 4 Kopien, wenn 3 davon verloren gehen oder beschädigt werden, diese bevorzugter dupliziert als 2 des 4-Kopien-Blocks.
L3: Unzureichende Kopien, die Kopien mit höherer Priorität als L2 werden zuerst kopiert. dritte Priorität.
L4: Die Mindestanzahl von Kopien des Blocks, die die Anforderungen erfüllt. Die Duplizierungsanforderung ist geringer als bei L2-L3.
L5: Der Block ist beschädigt und es ist derzeit eine nicht beschädigte Kopie verfügbar
1.2.2 Kontrollknoten-Offline-RPC-Sturmparameter
Die drei Parameter sind die Parameter in hdfs-site.xml. Einzelheiten finden Sie auf der offiziellen Website von Apache Hadoop. Tatsächlich wird die Geschwindigkeit der Blockreplikation von zwei Aspekten bestimmt. Einer ist die Geschwindigkeit der Namenode-Verteilungsaufgaben und der andere ist die Replikationsgeschwindigkeit zwischen Datenknoten. Ersteres kann als Eingang, letzteres als Ausgang verstanden werden.
1. Eingabeparameter: Steuerung der Aufgabenverteilung von der Namensknotenebene Diese Parameteränderung muss den Namensknoten neu starten und muss den Datenknoten nicht neu starten.
dfs.namenode.replication.work.multiplier.per.iteration Der Standardwert dieses Parameters ist 2 für Apache Hadoop und 10 für cdh-Cluster
Dieser Parameter bestimmt die Anzahl der Blöcke, die für jeden DN repliziert werden können, wenn NN und DN eine Aufgabenliste in einem Heartbeat (3s) senden. Wenn beispielsweise 5 Knoten im Cluster vorhanden sind und dieser Wert auf 5 gesetzt ist, beträgt die Anzahl der Datenblöcke, die der Namnode für einen Herzschlag an den Datenknoten senden kann, 5*5=25 Blöcke. Wenn ein Knoten offline/stillgelegt ist und 365.588 Blöcke kopiert werden müssen, wie lange dauert es, bis der Namensknoten die Aufgabe der zu kopierenden Blöcke an den Datenknoten verteilt?
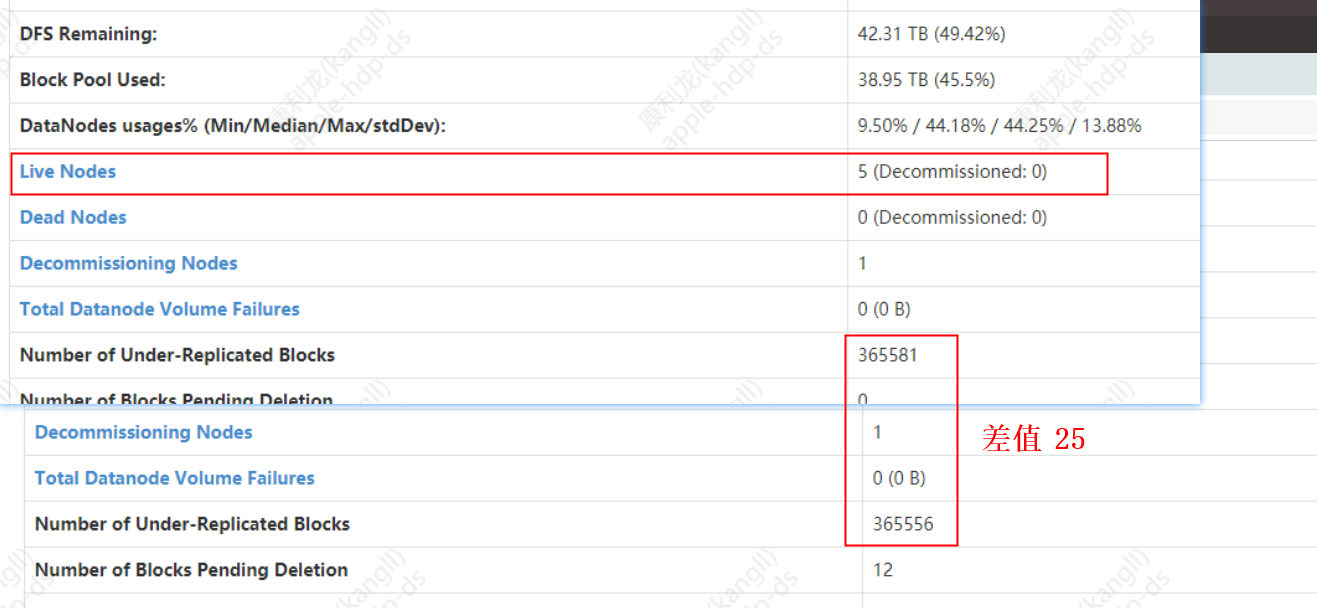
Die Namenode-Parameter von Ambari-Web werden wie folgt festgelegt:
Das Ergebnis der Limitberechnung:
Task-Verteilungszeit = Gesamtzahl der zu kopierenden Blöcke / (cluster active dn * parameter value) * heartbeat time
Zeit = 365585/(5*5)=14623 Herzschläge*3s/jeder Herzschlag=43870s = ungefähr 13 Stunden
Je mehr Knoten also vorhanden sind, desto schneller werden die Aufgaben verteilt, und die Verteilungsgeschwindigkeit ist proportional zur Anzahl der Knoten und diesem Parameter
2. Export-Parameter: Im Vergleich zur obigen Aufgabenverteilungssteuerung von Namenode werden die folgenden zwei Parameter auf Datanode-Ebene gesteuert, diese beiden Parameter müssen auch den Namenode neu starten
dfs.namenode.replication.max-streamsDer Standardwert von Apache Hadoop ist 2 und der Standardwert von cdh cluster ist 20.
Die Bedeutung dieses Parameters besteht darin, die maximale Anzahl von Threads für die Datenreplikation durch den Datanode-Knoten zu steuern Aus dem oben Gesagten wissen wir, dass die Replikationspriorität des Blocks in 5 Typen unterteilt ist. Dieser Parameter steuert, dass die Blockreplikation mit der höchsten Priorität nicht eingeschlossen wird. Das heißt, zusätzlich zum Höchstprioritätslimit für den Replikationsfluss
dfs.namenode.replication.max-streams-hard-limitDieser Wert ist Apache Hadoop-Standardwert 2, Cdh-Cluster-Standardwert 40
Die Bedeutung dieses Parameters besteht darin, die Anzahl von Strömen zu steuern, die von allen Prioritätsblöcken des Datenknotens einschließlich der höchsten Priorität kopiert werden; im Allgemeinen werden die obigen und die obigen zwei Parameter in Verbindung miteinander verwendet.
Schreiende Zusammenfassung: Der erstgenannte Parameter steuert die Häufigkeit, mit der der Datenknoten Aufgaben annimmt, und die beiden letztgenannten Parameter begrenzen weiter das maximale Übertragungsvolumen des parallelen Thread-Netzwerks, das der Datenknoten auf einmal abschließt. Der spezifische Wert der obigen Parameter hängt von der Größe des Clusters und der Konfiguration des Clusters ab und kann nicht auf die gleiche Weise diskutiert werden. Im Allgemeinen ist es einfacher und leichter vom Eingang aus zu kontrollieren. Wenn die Skalierung beispielsweise 5 Cluster ist, dfs.namenode.replication.work.multiplier.per.iteration=10, 5 DataNodes, dann verteilt der Cluster 50 Blöcke pro Heartbeat. Wenn der Dateispeicher des Clusters vollständig auf 5 Knoten verteilt ist, Jeder Knoten repliziert 10 Blöcke gleichzeitig (tatsächlich nehmen nicht alle Knoten an der Datenreplikation aufgrund der Copy-Shelving-Strategie, der Rack-Bewusstheit usw. teil), die Größe jedes Blocks beträgt 128 MB und die Netzwerklast jedes Knotens beträgt 128 * 10 /3= 546Mb/s, dann muss man abwarten, ob es in Kombination mit der tatsächlichen Situation zu einem Bandbreitenengpass kommt und ob ein so großes Network IO die Berechnung normaler Tasks beeinträchtigt, ggf. sollte dieser Wert gesenkt werden.
2. So gehen Sie schnell offline
Das Wesentliche, wie Knoten schnell offline geschaltet werden können, besteht darin, die Replikationsgeschwindigkeit von Replikaten zu erhöhen. Sie wird hauptsächlich durch die drei oben genannten Parameter gesteuert: Der erste dient der Steuerung der Verteilung von Namenode-Aufgaben und der zweite der Steuerung der Replikationsrate von Datenknoten, vorausgesetzt, dass dies die normalen Produktionsaufgaben nicht beeinträchtigt. Je kleiner die Clustergröße, desto langsamer der Offline-Modus, da beispielsweise die Gesamtzahl der Verteilungen viel langsamer ist.
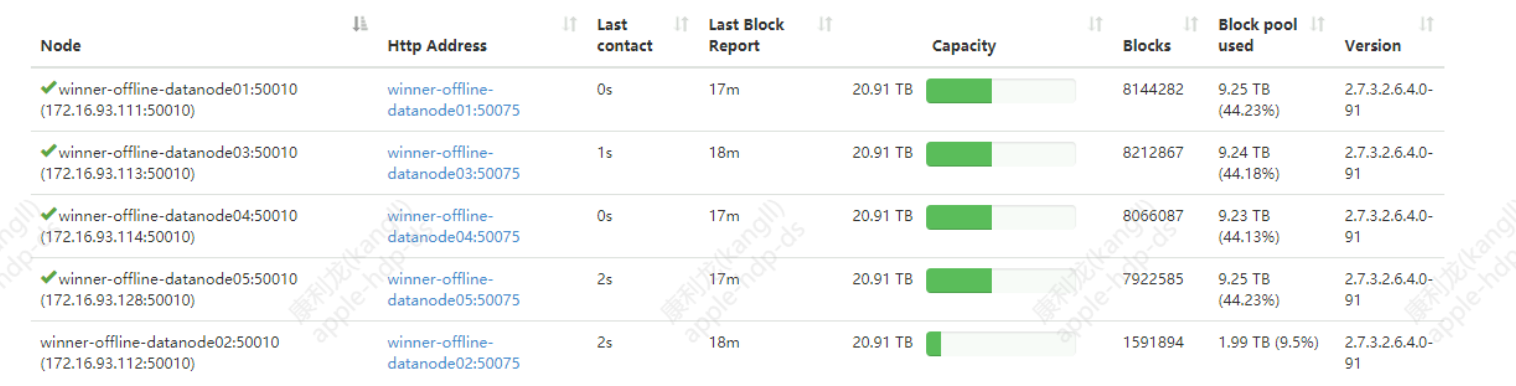
Das Folgende ist der Datanode-Knoten:
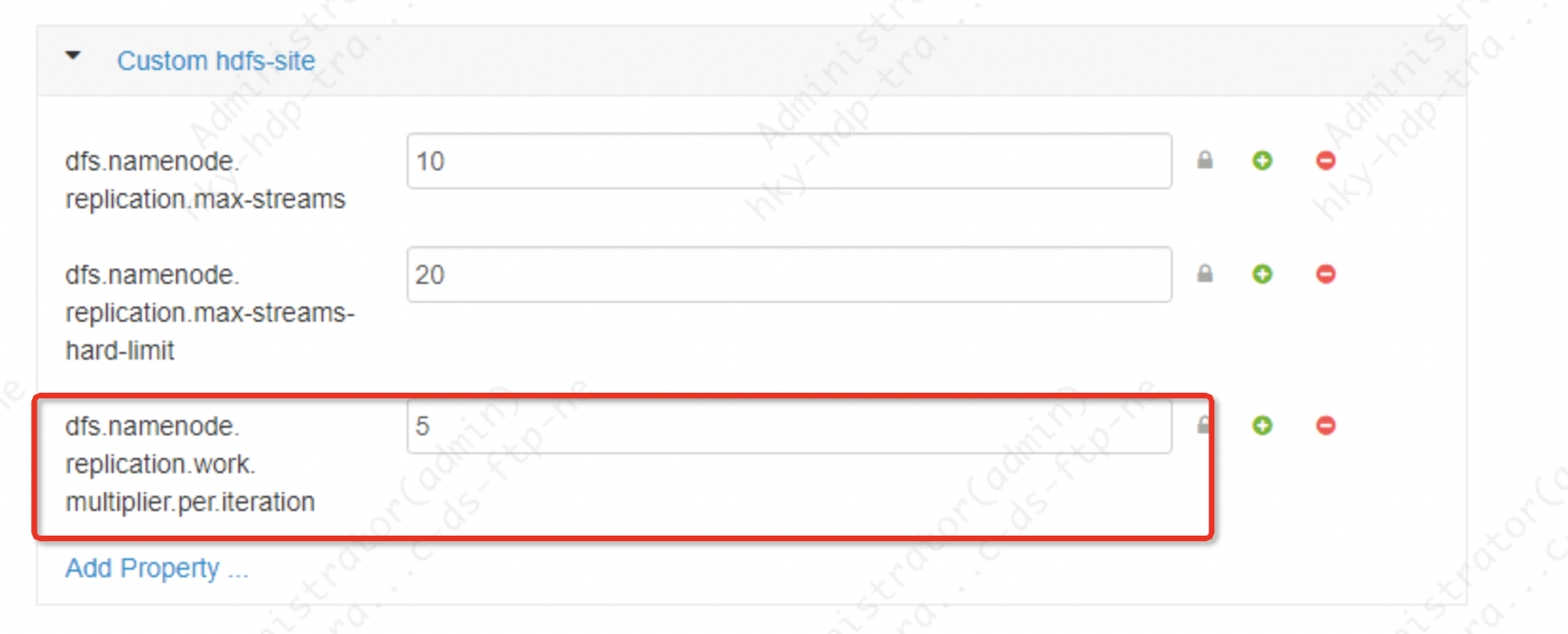
Ambari-Web-Parametereinstellungen:
dfs.namenode.replication.work.multiplier.per.iteration=5
dfs.namenode.replication.max-streams=10
dfs.namenode.replication.max-streams-hard-limit=20Das Ergebnis der Limitberechnung:
Task-Verteilungszeit = Gesamtzahl der zu kopierenden Blöcke / (cluster active dn * parameter value) * heartbeat time
Zeit = 365585/(5*5)=14623 Herzschläge*3s/jeder Herzschlag=43870s = ungefähr 13 Stunden
Da der Cluster kleine Dateien nicht rechtzeitig verarbeitet, die Anzahl der Blöcke groß ist und es nur 5 Cluster-Knoten gibt, wird die Außerbetriebnahme eines Datenknotens lange dauern, um die Blockreplikation abzuschließen, aber es liegt in einem akzeptablen Bereich. Wenn es sich um einen Knoten mit relativ vielen Knoten handelt, werden wir die obigen Parameter weiter anpassen.
Im aktiven Namenode-Protokoll können wir sehen, dass die Anzahl der Blöcke, die jedes Mal kopiert werden müssen, 50 Blöcke beträgt, und die Gesamtzahl der Blöcke, die kopiert werden müssen, 344341 und andere Informationen beträgt.
/var/log/hadoop/hdfs/hadoop-hdfs-namenode-namenode.log
15.12.2022 11:41:15,551 INFO BlockStateChange (UnderReplicatedBlocks.java:chooseUnderReplicatedBlocks(395)) – chooseUnderReplicatedBlocks hat 50 Blöcke auf Prioritätsstufe 2 ausgewählt; Gesamt=50 Lesezeichen zurücksetzen? FALSCH
15.12.2022 11:41:15,552 INFO BlockStateChange (BlockManager.java:computeReplicationWorkForBlocks(1653)) – BLOCK* benötigteReplikationen = 344341, ausstehendeReplikationen = 67.
15.12.2022 11:41:15,552 INFO blockmanagement.BlockManager (BlockManager.java:computeReplicationWorkForBlocks(1660)) – Ausgewählte Blöcke, die nicht repliziert werden konnten = 10; davon haben 0 kein Ziel, 10 haben keine Quelle, 0 sind UC, 0 werden aufgegeben, 0 haben bereits genügend Replikate.
15.12.2022 11:41:15,552 INFO blockmanagement.BlockManager (BlockManager.java:rescanPostponedMisreplicatedBlocks(2121)) – Erneuter Scan von später verschobenenMisreplicatedBlocks in 0 ms abgeschlossen. 18 Blöcke sind übrig. 0 Blöcke wurden entfernt.
