1. Definieren Sie die LSTM-Struktur
bilstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2, bidirectional=True)
Definieren Sie ein zweischichtiges bidirektionales LSTM mit einer Eingabegröße von 10 und einer versteckten Größe von 20.
Hinweis: Nachdem die Struktur von LSTM definiert wurde, sollten die Ebenen input_size, hidden_size und num_layers unter demselben Programm dieselben sein wie hier.
2. Eingabeformat
Offizielle Dokumentation:
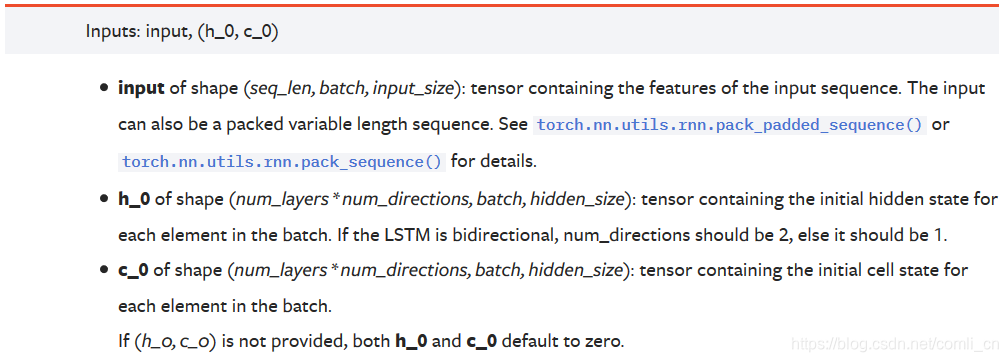
input = torch.randn(5, 3, 10)#(seq_len, batch, input_size)
(1) Wenn die einzugebenden Daten eindimensionale Daten sind, dann:
seq_lenGibt an, wie viele Daten für jede Charge eingegeben werden
StapelGibt an, dass die Daten in Stapel unterteilt sind
input_sizeZu diesem Zeitpunkt ist es 1
Zum Beispiel:
Wir haben Originaldatendaten = 1,2,3,4,5,6,7,8,9,10, insgesamt 10 Proben, und dann werden diese Daten zur Verarbeitung in LSTM gespeichert. Vor der Verarbeitung müssen wir das Datenformular transformieren. Zuerst setzen wir seq_len auf 3, dann lautet das Datenformular zu diesem Zeitpunkt:
1-2-3, 2-3-4, 3-4-5, 4-5- 6, 5-6-7, 6-7-8, 7-8-9, 8-9-10, 9-10-0, 10-0-0 (die letzten beiden Daten sind unvollständig, keine Auffüllung)
Setzen Sie dann batch_size auf 2.
Dann nehmen wir die erste Charge als 1-2-3, 2-3-4 heraus. Die Größe dieser Charge beträgt (2, 3, 1). Wir geben dieses Zeug in das Modell ein.
Die nächste Charge ist 3-4-5, 4-5-6.
Die dritte Charge ist 5-6-7, 6-7-8.
Die vierte Charge ist 7-8-9, 8-9-10.
Die fünfte Charge ist 9-10-0, 10-0-0. In unseren Daten wurden insgesamt 5 Chargen generiert.
(2) Wenn die einzugebenden Daten zweidimensionale Daten sind
seq_lenGibt an, wie viele Daten für jede Charge eingegeben werden
StapelGibt an, dass die Daten in Stapel unterteilt sind
input_sizeDie Länge des Attributvektors, der die einzelnen Daten darstellt
Zum Beispiel:
data_ = [[1, 10, 11, 15, 9, 100],
[2, 11, 12, 16, 9, 100],
[3, 12, 13, 17, 9, 100],
[4, 13, 14, 18, 9, 100],
[5, 14, 15, 19, 9, 100],
[6, 15, 16, 10, 9, 100],
[7, 15, 16, 10, 9, 100],
[8, 15, 16, 10, 9, 100],
[9, 15, 16, 10, 9, 100],
[10, 15, 16, 10, 9, 100]]
seq_len = 3, batch = 2, input_size = 6,
dann ist unser erster Batch:
tensor([[[ 1., 10., 11., 15., 9., 100.],
[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.]],
[[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.],
[ 4., 13., 14., 18., 9., 100.]]])
Die letzte Charge ist:
tensor([[[ 9., 15., 16., 10., 9., 100.],
[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.]],
[[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]]])
3. Ausgabeformat
Offizielle Dokumentation:
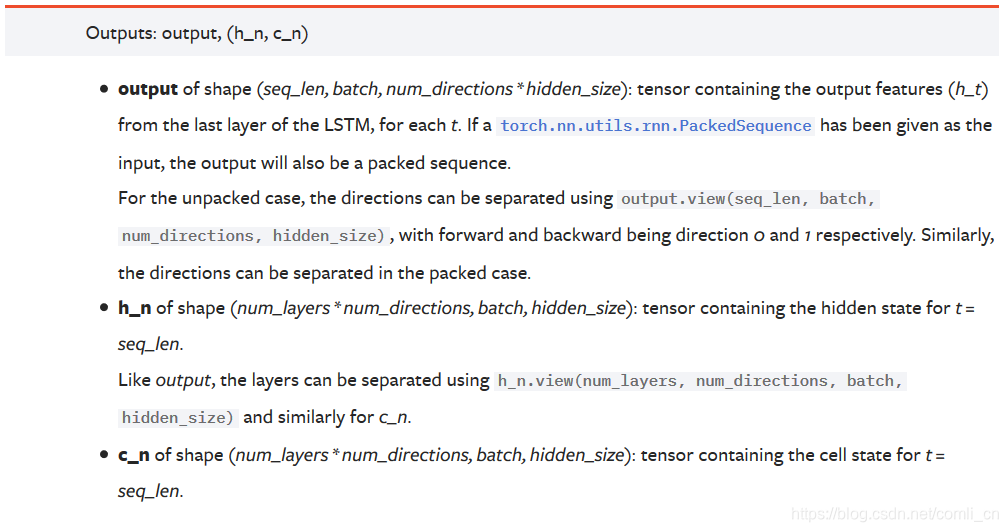 Anmerkungen :
Anmerkungen :
AusgabeDie Form ist (seq_len, batch, num_directions * hidden_size): Dieser Tensor enthält die Ausgabeeigenschaften (h_t) jedes Zyklus der letzten Schicht von LSTM. Wenn es sich um ein bidirektionales LSTM handelt, ist der Ausgang jedes Zeitschritts h = [h vorwärts, h rückwärts] (der Vorwärts- und Rückwärtsgang h desselben Zeitschritts sind verbunden)
h_nJede Schicht wird mit der Ausgabe h des letzten Zeitschritts gespeichert. Wenn es sich um ein bidirektionales LSTM handelt, wird die Ausgabe h des letzten Zeitschritts der Vorwärts- und Rückwärtsrichtung separat gespeichert.
c_nGleich wie h_n, außer dass der Wert von c gespeichert wird
Analyse :
AusgabeIst ein dreidimensionaler Tensor, repräsentiert die erste Dimension die Sequenzlänge, die zweite Dimension repräsentiert einen Stapel von Proben (Stapel), die dritte Dimension ist hidden_size (versteckte Schichtgröße) * num_directions, wobei num_directions davon abhängt, ob es "bidirektional" ist oder nicht Ist 1 oder 2. Daher können wir wissen, dass sich die Größe der dritten Dimension der Ausgabe ändert, je nachdem, ob sie bidirektional oder nicht bidirektional ist. Die dritte Dimension entspricht der Größe der von uns definierten verborgenen Ebene. Wenn bidirektional, entspricht die Größe der dritten Dimension dem Zweifachen Die Größe der ausgeblendeten Ebene.
h_nIst ein dreidimensionaler Tensor, ist die erste Dimension num_layers num_directions, num_layers ist die Anzahl der Schichten des von uns definierten neuronalen Netzwerks, num_directions wurde oben eingeführt, der Wert ist 1 oder 2, was angibt, ob es sich um ein bidirektionales LSTM handelt. Die zweite Dimension repräsentiert die Chargengröße einer Charge. Die dritte Dimension repräsentiert die Größe der verborgenen Ebene. In der ersten Dimension ist h_n schwer zu verstehen. Zuerst definieren wir das aktuelle LSTM als unidirektionales LSTM, dann ist die Größe der ersten Dimension num_layers, was die Ausgabe des letzten Zeitschritts der n-ten Schicht darstellt. Wenn es sich um ein bidirektionales LSTM handelt, beträgt die Größe der ersten Dimension 2 * num_layers. Zu diesem Zeitpunkt stellt die Dimension immer noch die Ausgabe des letzten Zeitschritts jeder Schicht dar, und die Ausgabe des letzten Zeitschritts wird in den Vorwärts- und Rückwärtsoperationen verwendet. Eine dieser Dimensionen.
Zum Beispiel: Wir definieren ein bidirektionales LSTM mit num_layers = 3, die Größe der ersten Dimension von h_n ist gleich 6 (2 3), h_n [0] bedeutet die Ausgabe des letzten Zeitschritts der Vorwärtsausbreitung der ersten Schicht, h_n [1 ] Repräsentiert die Ausgabe des letzten Zeitschritts der Rückwärtsausbreitung der ersten Schicht, h_n [2] repräsentiert die Ausgabe des letzten Zeitschritts der Vorwärtsausbreitung der zweiten Schicht, h_n [3] repräsentiert die Ausgabe des letzten Zeitschritts der Rückwärtsausbreitung der zweiten Schicht , H_n [4] und h_n [5] repräsentieren die Ausgabe des letzten Zeitschritts der Vorwärts- bzw. Rückwärtsausbreitung der dritten Schicht.
c_nDie Struktur ist die gleiche wie die von h_n, daher wird sie hier nicht wiederholt.
4. Verständnis einiger Parameter
seq_lenDie Eingabegröße wird hier verwendet, wenn ein Wort oder Daten beschrieben werden, damit das Wort oder die Daten von der Maschine leichter verstanden werden können
Stapel Die Stapelverarbeitung bezieht sich hier auf die Aktualisierung der Parameter nach jedem Trainingstapel. Wenn die Daten nicht in Stapel unterteilt werden, um die Daten zu aktualisieren, sondern einzeln, ist der Berechnungsbetrag zu groß und die Zeit zu lang. Schließlich wird der Fehler größer sein.
5. Zusammen auflisten
input(seq_len,batch,input_size)
rnn = torch.nn.LSTM(input_size,hidden_size,num_layers)
h0(num_layers*num_directions,batch,hidden_size)
c0(num_layers*num_directions,batch,hidden_size)
output(seq_len,batch,num_direction*hidden_size)
hn(num_layers*num_directions,batch,hidden_size)
cn(num_layers*num_directions,batch,hidden_size)
LSTM in der offiziellen Dokumentation von pytorch . Grundlegendes
zum Eingabeformat Grundlegendes zum
Ausgabeformat
