Activation Addition:一种无需优化的语言模型控制方法
引言
随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,如何高效、可控地引导模型输出成为一个亟待解决的问题。传统的控制方法,如监督微调(Supervised Finetuning)、人类反馈强化学习(RLHF)、提示工程(Prompt Engineering)和引导解码(Guided Decoding),虽然在某些场景下有效,但通常需要大量计算资源或标注数据,且对模型行为的精准控制仍存在局限性。
近期,一篇由 Alexander Matt Turner 等人在 2023 年发表的论文(2308.10248v4)提出了一种名为 Activation Addition (ActAdd) 的创新方法,通过在推理时直接修改模型的激活值(Activations),以自然语言指定的方式引导模型输出特定主题、情感或风格的内容。ActAdd 的核心优势在于无需优化、无需标注数据、计算开销低,并且能够保持模型在非目标任务上的性能。本文将面向深度学习研究者,详细介绍 ActAdd 的方法原理、实现细节及其在语言模型控制中的潜力。
ActAdd 方法的核心思想
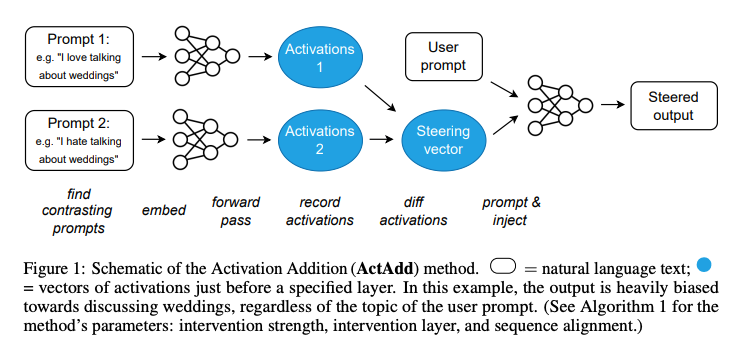
ActAdd 是一种基于激活工程(Activation Engineering) 的推理时控制方法,其核心思想是通过在模型前向传播过程中注入特定的“引导向量”(Steering Vector),改变模型的激活状态,从而影响输出文本的高级属性(如情感、主题或风格)。与传统的权重调整或提示优化不同,ActAdd 直接操作模型的残差流(Residual Stream),通过自然语言提示对(Prompt Pair)定义引导方向。
方法流程
ActAdd 的实现可以总结为以下步骤(详见论文 Algorithm 1):
-
定义对比提示对(Contrast Pair):
- 用户提供一对自然语言提示 ( ( p + , p − ) (p_+, p_-) (p+,p−) ),其中 ( p + p_+ p+ ) 表示希望输出的属性(如“谈论婚礼”),( p − p_- p− ) 表示相反属性(如“不谈论婚礼”)。
- 例如,( p + = p_+ = p+= ) “I talk about weddings constantly”,( p − = p_- = p−= ) “I do not talk about weddings constantly”。
-
计算引导向量:
- 对 ( p + p_+ p+ ) 和 ( p − p_- p− ) 分别执行前向传播,记录指定层 ( l l l ) 的激活值 ( h + l \mathbf{h}_+^l h+l ) 和 ( h − l \mathbf{h}_-^l h−l )。
- 计算激活差值:( h A l = h + l − h − l \mathbf{h}_A^l = \mathbf{h}_+^l - \mathbf{h}_-^l hAl=h+l−h−l ),作为引导向量。
- 通过注入系数 ( c c c )(通常在 3 到 15 之间)对引导向量进行缩放,控制干预强度。
-
注入引导向量:
- 在用户输入提示 ( p ∗ p^* p∗ ) 的前向传播中,将缩放后的引导向量 ( c h A l c \mathbf{h}_A^l chAl ) 加到指定层 ( l l l ) 的残差流中。
- 继续完成前向传播,生成引导后的输出 ( S S S )。
-
超参数选择:
- 关键超参数包括目标层 ( l l l )、注入系数 ( c c c ) 和激活对齐位置 ( a a a )。论文通过网格搜索确定这些参数,发现中间层(如 GPT-2-XL 的第 6 至 24 层)效果最佳。
技术细节
- 残差流操作:ActAdd 针对 Transformer 模型的残差流(Residual Stream)进行干预。残差流是 Transformer 每层输入和输出的累加向量,包含了模型的上下文信息。ActAdd 通过在特定层添加引导向量,影响后续的注意力机制和前馈网络计算。
- 自然语言接口:用户通过直观的自然语言提示对定义引导方向,无需深入了解模型内部结构。这降低了使用门槛,使非技术用户也能进行控制。
- 无优化特性:ActAdd 仅需两次前向传播(分别处理 ( p + p_+ p+ ) 和 ( p − p_- p− ))即可生成引导向量,无需反向传播或梯度优化,计算开销极低。
ActAdd 的实验结果
论文在多个语言模型(如 GPT-2-XL、LLaMA-3、OPT 和 GPT-J)上验证了 ActAdd 的有效性,主要聚焦于以下任务:
1. 情感控制(Sentiment Control)
- 使用“Love - Hate”引导向量,ActAdd 在负面到正面情感转换(NegToPos)任务上取得了显著效果。例如,在 GPT-2-XL 上,提示“I hate you because…”的输出从负面(“you are the most disgusting thing”)变为正面(“you are so beautiful”)。
- 在 LLaMA-3-8B 上,ActAdd 实现了 25% 的情感正向分类提升,同时保持了较高的流畅性和相关性。
2. 主题引导(Topic Steering)
- 使用“weddings - ‘’”引导向量,ActAdd 成功将模型输出引导至婚礼相关内容。例如,提示“I went up to my friend and said…”的输出从无关内容变为讨论婚礼的对话。
- 实验表明,ActAdd 在婚礼相关文档上的困惑度(Perplexity)降低(如 GPT-J-6B 上为 0.875),而在非婚礼文档上性能几乎不受影响(Perplexity Ratio 接近 1)。
3. 去毒化(Detoxification)
- ActAdd 在 OPT-6.7B 和 LLaMA-3-8B 上分别实现了 17% 和 5% 的毒性降低,表明其在减少有害输出方面的潜力。
4. 性能稳定性
- ActAdd 在非目标任务上的性能保持良好。例如,在 ConceptNet 知识测试中,ActAdd 未显著降低模型的通用知识能力。
- 推理时间开销(Inference Time Premium)随模型规模增加而稳定或降低,表明 ActAdd 的可扩展性。
ActAdd 的优势与局限性
优势
- 高效性:ActAdd 无需优化或标注数据,仅通过两次前向传播即可生成引导向量,计算开销远低于微调或 RLHF。
- 灵活性:通过自然语言提示对,用户可以轻松控制输出主题、情感或风格,适用于多种场景。
- 可扩展性:ActAdd 在不同规模的模型(如 GPT-2-XL 到 LLaMA-3-8B)上均表现良好,且推理开销随模型增大而稳定。
- 可解释性:ActAdd 不修改模型权重,保留了原始模型的内部结构,有助于后续的模型分析和调试。
局限性
- 超参数依赖:目标层 ( l l l )、注入系数 ( c c c ) 和对齐位置 ( a a a ) 的选择需要网格搜索,可能增加实验成本。
- 模型限制:ActAdd 要求模型缓存中间激活值,这可能对某些架构或实现造成约束。
- 部分失败案例:如论文 Table 13 所示,某些引导向量(如“Eiffel - Rome”)在特定模型(如 LLaMA-13B)上效果不佳,原因尚需进一步研究。
- 潜在副作用:高注入系数可能导致输出语法错误或模型性能下降,需谨慎调整。
与现有方法的比较
ActAdd 与其他语言模型控制方法相比,具有独特的定位:
- 对比微调和 RLHF:微调和 RLHF 需要大量标注数据和计算资源,且可能影响模型整体性能。ActAdd 作为在线控制方法,实时性更强且不修改权重。
- 对比提示工程:提示工程依赖于精心设计的输入,效果不稳定。ActAdd 通过激活干预提供更精准的控制。
- 对比其他激活工程方法:如 Subramani et al. (2022) 和 Hernandez et al. (2023) 的工作依赖梯度搜索寻找引导向量,而 ActAdd 直接通过提示对的激活差值计算,简化了流程。
未来研究方向
- 更复杂的引导向量:探索多对提示组合或多层干预,以实现更细粒度的控制。
- 自动化超参数选择:开发自适应方法自动确定最佳 ( l l l )、( c c c ) 和 ( a a a ),减少人工调参。
- 跨模型通用性:进一步验证 ActAdd 在更广泛模型架构(如非 Transformer 模型)上的适用性。
- 可解释性分析:结合神经网络可解释性技术,深入理解引导向量在残差流中的作用机制。
结论
Activation Addition (ActAdd) 是一种创新的语言模型控制方法,通过推理时激活干预实现对输出内容的高效引导。其无优化、低开销和自然语言接口的特性使其在深度学习研究和应用中具有广阔前景。对于希望探索语言模型控制的研究者,ActAdd 提供了一个简单而强大的工具,值得进一步研究和实践。
感兴趣的读者可以访问论文提供的代码仓库(Zenodo)进行实验。期待 ActAdd 在更多场景下的应用与优化!
代码示例
以下是一个基于 PyTorch 和 TransformerLens 库的示例代码,模拟 ActAdd 方法在 GPT-2-XL 模型上的应用,针对婚礼主题引导(Wedding Steering)任务。代码包括模型加载、引导向量计算、激活干预和输出生成等步骤,并附带详细注释和解释。
实验代码示例
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformer_lens import HookedTransformer
import pandas as pd
from typing import Tuple, List
# 设置随机种子以确保可重复性
torch.manual_seed(0)
np.random.seed(0)
# 超参数(基于论文 Appendix E 和实验设置)
MODEL_NAME = "gpt2-xl" # 使用 GPT-2-XL 模型
TARGET_LAYER = 6 # 干预层,论文建议中间层效果最佳
INJECTION_COEFF = 4.0 # 注入系数 c,控制引导强度
ALIGNMENT_POS = 1 # 激活对齐位置 a,通常固定为 1(前向对齐)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = HookedTransformer.from_pretrained(MODEL_NAME, device=DEVICE)
# 定义对比提示对和用户提示
POSITIVE_PROMPT = "I talk about weddings constantly" # p_+
NEGATIVE_PROMPT = "I do not talk about weddings constantly" # p_-
USER_PROMPT = "I went up to my friend and said" # p*
def pad_prompts(pos_prompt: str, neg_prompt: str) -> Tuple[str, str]:
"""对提示进行右填充,确保分词后长度一致"""
pos_tokens = tokenizer(pos_prompt, return_tensors="pt")["input_ids"]
neg_tokens = tokenizer(neg_prompt, return_tensors="pt")["input_ids"]
max_len = max(pos_tokens.size(1), neg_tokens.size(1))
# 右填充空格
pos_prompt_padded = pos_prompt + " " * (max_len - pos_tokens.size(1))
neg_prompt_padded = neg_prompt + " " * (max_len - neg_tokens.size(1))
return pos_prompt_padded, neg_prompt_padded
def compute_steering_vector(
pos_prompt: str, neg_prompt: str, layer: int
) -> torch.Tensor:
"""计算引导向量 h_A = h_+ - h_-"""
# 确保提示长度一致
pos_prompt_padded, neg_prompt_padded = pad_prompts(pos_prompt, neg_prompt)
# 分词
pos_inputs = tokenizer(pos_prompt_padded, return_tensors="pt").to(DEVICE)
neg_inputs = tokenizer(neg_prompt_padded, return_tensors="pt").to(DEVICE)
# 记录激活值的钩子
activations = {
}
def activation_hook(name):
def hook(module, input, output):
activations[name] = output
return hook
# 注册钩子以捕获指定层的残差流
hook_name = f"blocks.{
layer}.hook_resid_pre"
model.blocks[layer].register_forward_hook(activation_hook(hook_name))
# 前向传播:正向提示
model.zero_grad()
model(**pos_inputs)
pos_activations = activations[hook_name].detach()
# 前向传播:负向提示
model.zero_grad()
model(**neg_inputs)
neg_activations = activations[hook_name].detach()
# 计算引导向量
steering_vector = pos_activations - neg_activations
return steering_vector
def apply_actadd(
user_prompt: str, steering_vector: torch.Tensor, layer: int, coeff: float
) -> str:
"""应用 ActAdd 干预并生成输出"""
# 分词用户提示
inputs = tokenizer(user_prompt, return_tensors="pt").to(DEVICE)
# 定义干预钩子
def intervention_hook(module, input, output):
# 注入引导向量
output[:, ALIGNMENT_POS:] += coeff * steering_vector[:, ALIGNMENT_POS:]
return output
# 注册干预钩子
hook_name = f"blocks.{
layer}.hook_resid_pre"
hook_handle = model.blocks[layer].register_forward_hook(intervention_hook)
# 生成输出
outputs = model.generate(
inputs["input_ids"],
max_length=40,
do_sample=True,
temperature=1.0,
top_p=0.3,
freq_penalty=1.0,
pad_token_id=tokenizer.eos_token_id
)
# 移除钩子
hook_handle.remove()
# 解码输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
def evaluate_weddingness(text: str) -> int:
"""简单评估输出的婚礼相关性,统计关键词出现次数"""
wedding_keywords = [
"wedding", "weddings", "wed", "marry", "married",
"marriage", "bride", "groom", "honeymoon"
]
return sum(text.lower().count(keyword) for keyword in wedding_keywords)
def main():
# 计算引导向量
steering_vector = compute_steering_vector(
POSITIVE_PROMPT, NEGATIVE_PROMPT, TARGET_LAYER
)
# 应用 ActAdd 生成引导输出
steered_output = apply_actadd(
USER_PROMPT, steering_vector, TARGET_LAYER, INJECTION_COEFF
)
# 生成未引导输出(基准)
inputs = tokenizer(USER_PROMPT, return_tensors="pt").to(DEVICE)
baseline_outputs = model.generate(
inputs["input_ids"],
max_length=40,
do_sample=True,
temperature=1.0,
top_p=0.3,
freq_penalty=1.0,
pad_token_id=tokenizer.eos_token_id
)
baseline_output = tokenizer.decode(baseline_outputs[0], skip_special_tokens=True)
# 评估婚礼相关性
steered_weddingness = evaluate_weddingness(steered_output)
baseline_weddingness = evaluate_weddingness(baseline_output)
# 输出结果
print("=== Baseline Output ===")
print(baseline_output)
print(f"Weddingness Score: {
baseline_weddingness}")
print("\n=== Steered Output ===")
print(steered_output)
print(f"Weddingness Score: {
steered_weddingness}")
if __name__ == "__main__":
main()
代码详细解释
1. 依赖和初始化
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformer_lens import HookedTransformer
- 依赖库:
torch:PyTorch 深度学习框架,用于张量计算和模型操作。transformers:Hugging Face 的库,用于加载预训练模型和分词器。transformer_lens:一个专门用于 Transformer 模型分析的库,支持激活值捕获和干预,适合实现 ActAdd。
- 随机种子:设置
torch.manual_seed(0)和np.random.seed(0),确保实验可重复(论文 Appendix E 提到使用 seed=0)。 - 超参数:
MODEL_NAME = "gpt2-xl":使用 GPT-2-XL(1.5B 参数),论文中主要测试模型。TARGET_LAYER = 6:干预层,论文建议中间层(如 6 或 20)效果最佳。INJECTION_COEFF = 4.0:注入系数 ( c ),控制引导强度,论文中常见值为 3 到 15。ALIGNMENT_POS = 1:激活对齐位置 ( a ),固定为 1(前向对齐),如论文 Appendix C 所述。DEVICE:自动选择 GPU 或 CPU。
2. 模型和分词器加载
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = HookedTransformer.from_pretrained(MODEL_NAME, device=DEVICE)
- 使用 Hugging Face 的
AutoTokenizer加载 GPT-2-XL 的分词器,处理文本到 token 的转换。 - 使用
HookedTransformer加载 GPT-2-XL 模型,transformer_lens提供的HookedTransformer支持在特定层捕获和修改激活值,非常适合 ActAdd 的实现。
3. 提示定义
POSITIVE_PROMPT = "I talk about weddings constantly"
NEGATIVE_PROMPT = "I do not talk about weddings constantly"
USER_PROMPT = "I went up to my friend and said"
- 对比提示对:( p_+ ) 和 ( p_- ) 分别表示正向和负向属性,示例来自论文 Table 1,用于引导婚礼主题。
- 用户提示:( p^* ),用于测试 ActAdd 效果,来自论文 Table 1 的实验设置。
4. 提示填充函数
def pad_prompts(pos_prompt: str, neg_prompt: str) -> Tuple[str, str]:
- 功能:确保正向和负向提示分词后长度一致,论文 Appendix C 提到通过右填充空格实现。
- 实现:
- 使用分词器计算两个提示的 token 长度。
- 对较短的提示右填充空格,使长度对齐。
- 目的:保证激活值张量维度一致,便于后续计算引导向量。
5. 计算引导向量
def compute_steering_vector(pos_prompt: str, neg_prompt: str, layer: int) -> torch.Tensor:
- 功能:计算引导向量 ( h A l = h + l − h − l \mathbf{h}_A^l = \mathbf{h}_+^l - \mathbf{h}_-^l hAl=h+l−h−l )。
- 步骤:
- 调用
pad_prompts填充提示。 - 使用分词器将提示转换为 token ID 张量。
- 定义一个钩子函数
activation_hook,捕获指定层(blocks.{layer}.hook_resid_pre)的残差流激活值。 - 对正向和负向提示分别执行前向传播,记录激活值 ( h + l \mathbf{h}_+^l h+l ) 和 ( h − l \mathbf{h}_-^l h−l )。
- 计算激活差值 ( h A l \mathbf{h}_A^l hAl )。
- 调用
- 细节:
transformer_lens的HookedTransformer允许通过钩子捕获特定层的激活值。- 钩子注册在
hook_resid_pre,表示捕获层输入的残差流(论文提到操作残差流)。 - 激活值张量维度为
[batch_size, sequence_length, hidden_size],对于 GPT-2-XL,hidden_size=1600。
6. 应用 ActAdd 干预
def apply_actadd(user_prompt: str, steering_vector: torch.Tensor, layer: int, coeff: float) -> str:
- 功能:在用户提示的前向传播中注入引导向量,生成引导后的输出。
- 步骤:
- 分词用户提示。
- 定义干预钩子
intervention_hook,在指定层的残差流中添加 ( c ⋅ h A l c \cdot \mathbf{h}_A^l c⋅hAl )。 - 使用
model.generate生成输出,采样参数(temperature=1.0,top_p=0.3,freq_penalty=1.0)与论文 Appendix E 一致。 - 解码生成结果为文本。
- 细节:
- 干预仅应用于
ALIGNMENT_POS之后的序列位置(论文固定为 1)。 - 生成长度设为 40 token,符合论文实验设置。
- 移除钩子以避免影响后续推理。
- 干预仅应用于
7. 婚礼相关性评估
def evaluate_weddingness(text: str) -> int:
- 功能:通过统计婚礼相关关键词出现次数,评估输出的婚礼相关性。
- 关键词:与论文 Section 3.1 一致,包括 “wedding”, “marry”, “bride” 等。
- 实现:简单计数关键词出现次数,返回总和。
8. 主函数
def main():
- 功能:整合上述步骤,执行 ActAdd 实验并比较引导与未引导输出。
- 步骤:
- 计算引导向量。
- 生成引导输出(应用 ActAdd)。
- 生成基准输出(无干预)。
- 评估两者的婚礼相关性。
- 打印结果。
- 输出示例:
- 基准输出可能为无关内容,如“我很抱歉,我无法帮助你”。
- 引导输出可能包含婚礼相关内容,如“我要谈论婚礼季的这一集”。
实验设置与论文一致性
-
模型选择:
- 代码使用 GPT-2-XL,与论文主要实验一致(Appendix E)。
- 论文还测试了 LLaMA-3-8B、OPT-6.7B 等模型,可通过修改
MODEL_NAME扩展。
-
采样参数:
- 采样参数(
temperature=1.0,top_p=0.3,freq_penalty=1.0)直接来自论文 Appendix E,确保生成一致性。
- 采样参数(
-
数据集与评估:
- 论文使用 OpenWebText 进行困惑度评估(Section 3.1),但此处简化为关键词计数,符合论文 Table 1 的定性评估。
- 实际实验可使用论文提到的数据集(如 OpenWebText、LAMA ConceptNet),通过 Zenodo 仓库获取。
-
硬件与环境:
- 论文 Appendix E 提到使用 Nvidia RTX A5000 GPU 和 24GB GPU RAM。此代码在 CPU 或 GPU 上均可运行,但推荐 GPU 以加速推理。
- 依赖库版本(
torch==1.13.1,transformer-lens==1.4.0)与论文一致。
运行与预期结果
运行方式
- 安装依赖:
pip install torch transformers transformer-lens numpy pandas - 执行代码:
python actadd_experiment.py - 检查输出:
- 基准输出:通常与婚礼无关,婚礼相关性得分接近 0。
- 引导输出:包含婚礼相关词汇,如 “wedding”, “bride”,得分显著高于基准。
预期结果
- 定性结果:如论文 Table 1,引导输出应明确讨论婚礼主题,例如“我要谈论婚礼季的这一集”。
- 定量结果:婚礼相关性得分显著提高,困惑度在婚礼相关文本上降低(需额外实现 perplexity 计算)。
- 可重复性:通过固定种子和采样参数,结果应与论文一致(Appendix E)。
扩展与优化建议
-
多模型支持:
- 修改
MODEL_NAME为facebook/opt-6.7b或meta-llama/Llama-3-8b(需申请许可),复现论文在 OPT 和 LLaMA-3 上的实验。
- 修改
-
困惑度评估:
- 实现论文 Section 3.1 的 Perplexity Ratio 计算,加载 OpenWebText 数据集,比较引导与未引导模型的预测性能。
-
超参数搜索:
- 实现网格搜索,测试不同 ( l \in [6, 24] )、( c \in [3, 20] ),优化引导效果。
-
可视化:
- 绘制论文 Figure 7 和 8 的曲线,展示不同层的引导效果(需多次运行
apply_actadd并统计关键词)。
- 绘制论文 Figure 7 和 8 的曲线,展示不同层的引导效果(需多次运行
-
鲁棒性测试:
- 实现论文 Section H 的随机向量实验,比较随机干预与 ActAdd 的输出分布变化。
注意事项
- 模型缓存:ActAdd 要求模型缓存中间激活值,
transformer-lens已支持,但需确保内存充足。 - 注入系数:过高的 ( c c c )(如 >15)可能导致语法错误,需谨慎调整。
- 分词细节:论文 Appendix C 提到 GPT-2 分词器会在 token 前添加空格,代码中已通过填充空格处理。
结论
以上代码实现了 ActAdd 方法的核心功能,复现了论文中的婚礼主题引导实验。通过 transformer-lens 的钩子机制,代码能够高效捕获和修改激活值,实现推理时控制。研究者可基于此代码进一步探索 ActAdd 在其他任务(如情感控制、去毒化)或模型上的应用。
钩子(Hooks)介绍
在实现 Activation Addition (ActAdd) 方法的实验代码中,钩子(Hooks) 是关键技术,用于捕获和修改 Transformer 模型在特定层的激活值(Activations)。本文将详细介绍钩子的概念、如何在代码中使用它们、它们的实现原理,以及在 ActAdd 方法中的具体作用。内容将面向深度学习研究者,结合论文 2308.10248v4 和提供的实验代码,深入解析钩子的技术细节。
1. 什么是钩子?
在深度学习框架(如 PyTorch)中,钩子是一种机制,允许用户在神经网络的前向传播(Forward Pass)或反向传播(Backward Pass)过程中动态地捕获或修改中间层的输入、输出或梯度。钩子本质上是回调函数(Callback Functions),在特定模块(Module)或层的计算过程中被触发。
在 ActAdd 方法中,钩子用于:
- 捕获激活值:记录 Transformer 模型在指定层的残差流(Residual Stream)激活值,用于计算引导向量(Steering Vector)。
- 修改激活值:在推理时将引导向量注入到残差流中,改变模型的输出行为。
PyTorch 提供了两种主要钩子类型:
- 前向钩子(Forward Hook):在前向传播时触发,用于捕获或修改模块的输入/输出。
- 反向钩子(Backward Hook):在反向传播时触发,用于捕获或修改梯度(ActAdd 不使用反向钩子)。
在 ActAdd 实验代码中,使用的是 PyTorch 的前向钩子,结合 transformer-lens 库的便捷接口,操作 Transformer 模型的残差流。
2. 钩子在 ActAdd 中的作用
ActAdd 方法的核心是通过在推理时修改模型的激活值来引导输出。钩子在以下两个步骤中发挥关键作用:
-
计算引导向量:
- 使用钩子捕获正向提示 ( p + p_+ p+ )(如“I talk about weddings constantly”)和负向提示 ( p − p_- p− )(如“I do not talk about weddings constantly”)在指定层 ( l l l ) 的残差流激活值 ( h + l \mathbf{h}_+^l h+l ) 和 ( h − l \mathbf{h}_-^l h−l )。
- 计算引导向量 ( h A l = h + l − h − l \mathbf{h}_A^l = \mathbf{h}_+^l - \mathbf{h}_-^l hAl=h+l−h−l )。
-
注入引导向量:
- 使用钩子在用户提示 ( p ∗ p^* p∗ )(如“I went up to my friend and said”)的前向传播中,将缩放后的引导向量 ( c ⋅ h A l c \cdot \mathbf{h}_A^l c⋅hAl ) 添加到指定层的残差流中。
- 修改后的激活值影响后续层的计算,最终改变模型输出。
钩子使得这些操作可以在不修改模型权重或架构的情况下动态实现,符合 ActAdd 的“无优化”特性。
3. 钩子的使用方式
以下基于提供的实验代码,详细说明钩子在 ActAdd 中的使用方式,并结合代码片段解释每个部分。
3.1 捕获激活值的钩子
在 compute_steering_vector 函数中,使用前向钩子捕获指定层的残差流激活值:
def compute_steering_vector(pos_prompt: str, neg_prompt: str, layer: int) -> torch.Tensor:
# 确保提示长度一致
pos_prompt_padded, neg_prompt_padded = pad_prompts(pos_prompt, neg_prompt)
# 分词
pos_inputs = tokenizer(pos_prompt_padded, return_tensors="pt").to(DEVICE)
neg_inputs = tokenizer(neg_prompt_padded, return_tensors="pt").to(DEVICE)
# 记录激活值的钩子
activations = {
}
def activation_hook(name):
def hook(module, input, output):
activations[name] = output
return hook
# 注册钩子以捕获指定层的残差流
hook_name = f"blocks.{
layer}.hook_resid_pre"
model.blocks[layer].register_forward_hook(activation_hook(hook_name))
# 前向传播:正向提示
model.zero_grad()
model(**pos_inputs)
pos_activations = activations[hook_name].detach()
# 前向传播:负向提示
model.zero_grad()
model(**neg_inputs)
neg_activations = activations[hook_name].detach()
# 计算引导向量
steering_vector = pos_activations - neg_activations
return steering_vector
代码解析:
-
钩子定义:
activations = { } def activation_hook(name): def hook(module, input, output): activations[name] = output return hook- 创建一个字典
activations用于存储捕获的激活值。 - 定义
activation_hook函数,返回一个内部钩子函数hook,该函数在模块前向传播时被调用。 hook函数接收三个参数:module:被钩住的 PyTorch 模块(这里是 Transformer 的某层)。input:模块的输入张量(残差流)。output:模块的输出张量(此处为残差流输入,未经层计算)。- 将输出张量存储到
activations字典中,键为钩子名称。
- 创建一个字典
-
钩子注册:
hook_name = f"blocks.{ layer}.hook_resid_pre" model.blocks[layer].register_forward_hook(activation_hook(hook_name))- 使用
transformer-lens提供的HookedTransformer接口,钩子注册在blocks.{layer}.hook_resid_pre上,表示捕获第layer层输入的残差流。 register_forward_hook是 PyTorch 的方法,将activation_hook(hook_name)绑定到指定模块。
- 使用
-
前向传播与激活捕获:
model(**pos_inputs) pos_activations = activations[hook_name].detach()- 对正向提示执行前向传播,钩子自动捕获残差流激活值,存储在
activations[hook_name]中。 - 使用
.detach()断开张量与计算图的连接,避免梯度计算(ActAdd 不需要优化)。 - 对负向提示重复相同过程,得到 ( h + l \mathbf{h}_+^l h+l) 和 ( h − l \mathbf{h}_-^l h−l )。
- 对正向提示执行前向传播,钩子自动捕获残差流激活值,存储在
-
引导向量计算:
steering_vector = pos_activations - neg_activations- 计算激活差值,得到引导向量 ( \mathbf{h}_A^l ),维度为
[batch_size, sequence_length, hidden_size](对于 GPT-2-XL,hidden_size=1600)。
- 计算激活差值,得到引导向量 ( \mathbf{h}_A^l ),维度为
使用细节:
- 钩子名称
hook_resid_pre是transformer-lens的约定,表示捕获 Transformer 块输入的残差流(论文提到 ActAdd 操作残差流)。 - 每次前向传播后,
activations字典存储最新的激活值,需在两次传播间清空或单独处理。
3.2 注入引导向量的钩子
在 apply_actadd 函数中,使用前向钩子将引导向量注入到残差流中:
def apply_actadd(
user_prompt: str, steering_vector: torch.Tensor, layer: int, coeff: float
) -> str:
# 分词用户提示
inputs = tokenizer(user_prompt, return_tensors="pt").to(DEVICE)
# 定义干预钩子
def intervention_hook(module, input, output):
# 注入引导向量
output[:, ALIGNMENT_POS:] += coeff * steering_vector[:, ALIGNMENT_POS:]
return output
# 注册干预钩子
hook_name = f"blocks.{
layer}.hook_resid_pre"
hook_handle = model.blocks[layer].register_forward_hook(intervention_hook)
# 生成输出
outputs = model.generate(
inputs["input_ids"],
max_length=40,
do_sample=True,
temperature=1.0,
top_p=0.3,
freq_penalty=1.0,
pad_token_id=tokenizer.eos_token_id
)
# 移除钩子
hook_handle.remove()
# 解码输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
代码解析:
-
钩子定义:
def intervention_hook(module, input, output): output[:, ALIGNMENT_POS:] += coeff * steering_vector[:, ALIGNMENT_POS:] return output- 定义
intervention_hook,直接修改模块的输出张量。 - 将缩放后的引导向量 ( c ⋅ h A l c \cdot \mathbf{h}_A^l c⋅hAl ) 添加到残差流中,仅影响
ALIGNMENT_POS之后的序列位置(论文 Appendix C 固定a=1)。 - 返回修改后的张量,继续前向传播。
- 定义
-
钩子注册:
hook_name = f"blocks.{ layer}.hook_resid_pre" hook_handle = model.blocks[layer].register_forward_hook(intervention_hook)- 注册干预钩子到相同的残差流位置
hook_resid_pre。 hook_handle保存钩子句柄,用于后续移除。
- 注册干预钩子到相同的残差流位置
-
生成输出:
outputs = model.generate(...)- 在钩子生效的情况下,执行生成过程,干预后的残差流影响后续层计算,最终生成引导输出(如婚礼相关内容)。
-
钩子移除:
hook_handle.remove()- 在生成完成后移除钩子,避免影响后续推理。
- 这是 PyTorch 钩子管理的最佳实践,确保模型状态干净。
使用细节:
- 干预钩子直接修改张量,需确保
steering_vector的维度与残差流匹配。 ALIGNMENT_POS=1表示从序列的第二个 token 开始注入,符合论文中“前向对齐”的设置。
4. 钩子的实现原理
钩子的实现依赖于 PyTorch 的模块化设计和计算图机制。以下从底层原理角度解释钩子在 ActAdd 中的工作方式:
4.1 PyTorch 模块与前向钩子
- 模块(nn.Module):Transformer 模型由多个模块组成(如
nn.Linear、nn.Transformer),每个模块定义了前向传播逻辑。 - 前向钩子:通过
module.register_forward_hook(hook)注册,钩子函数在模块的forward方法调用时触发。钩子函数接收:module:当前模块实例。input:模块输入张量(tuple 形式)。output:模块输出张量。
- 执行流程:
- 模型前向传播到达目标模块。
- 模块计算输出前,触发钩子。
- 钩子可读取或修改
input/output,并返回修改后的输出(若无修改,返回原输出)。 - 修改后的输出传递到后续层。
4.2 TransformerLens 的钩子系统
transformer-lens是一个专门为 Transformer 模型设计的分析工具,提供了更便捷的钩子接口:- 钩子点(Hook Points):在 Transformer 的关键位置(如残差流、注意力输出)预定义了钩子点,名称如
blocks.{layer}.hook_resid_pre。 - 残差流:Transformer 的残差流是每层输入和输出的累加向量,
hook_resid_pre捕获层输入的残差流,正好符合 ActAdd 的操作需求(论文 Section 4)。
- 钩子点(Hook Points):在 Transformer 的关键位置(如残差流、注意力输出)预定义了钩子点,名称如
- 优势:
- 简化了钩子注册,用户无需手动解析模型结构。
- 支持动态干预,适合 ActAdd 的推理时修改。
4.3 ActAdd 中的钩子工作流程
以 GPT-2-XL 为例,假设干预第 6 层 (TARGET_LAYER=6):
- 捕获激活值:
- 输入正向提示,分词后为
[endoftext, I, talk, about, weddings, constantly]。 - 前向传播到达
blocks.6.hook_resid_pre,钩子捕获残差流张量,维度为[1, seq_len=6, hidden_size=1600]。 - 对负向提示重复,得到两个 …
- 输入正向提示,分词后为
- 注入引导向量:
- 输入用户提示,分词后为
[endoftext, I, went, up, to, my, friend, and, said]。 - 在
blocks.6.hook_resid_pre触发干预钩子,将引导向量加到残差流中。 - 修改后的残差流影响第 6 层的注意力机制和前馈网络,进而改变后续层的输出,最终生成婚礼相关内容。
- 输入用户提示,分词后为
4.4 数学表示
- 残差流在第 ( l l l ) 层的输入为 ( h l \mathbf{h}^l hl )。
- ActAdd 修改为:( h l ← h l + c ⋅ h A l \mathbf{h}^l \leftarrow \mathbf{h}^l + c \cdot \mathbf{h}_A^l hl←hl+c⋅hAl ),其中 ( h A l = h + l − h − l \mathbf{h}_A^l = \mathbf{h}_+^l - \mathbf{h}_-^l hAl=h+l−h−l )。
- 修改后的 ( h l \mathbf{h}^l hl ) 进入后续计算:( h l + 1 = LayerNorm ( h l + Attention ( h l ) + FFN ( h l ) ) \mathbf{h}^{l+1} = \text{LayerNorm}(\mathbf{h}^l + \text{Attention}(\mathbf{h}^l) + \text{FFN}(\mathbf{h}^l)) hl+1=LayerNorm(hl+Attention(hl)+FFN(hl)) )。
- 钩子确保 ( c ⋅ h A l c \cdot \mathbf{h}_A^l c⋅hAl ) 在正确位置注入,影响生成概率。
5. 钩子的优势与局限性
5.1 优势
- 动态性:钩子允许在推理时实时捕获和修改激活值,无需修改模型权重,符合 ActAdd 的“无优化”目标。
- 精确性:通过
transformer-lens的钩子点,可以精确操作残差流,控制干预的层和位置。 - 可扩展性:钩子机制适用于任何 Transformer 模型,支持扩展到 LLaMA、OPT 等(论文 Appendix F)。
- 调试友好:钩子便于分析模型内部状态,有助于理解引导向量的作用(论文 Figure 10)。
5.2 局限性
- 内存开销:捕获激活值需要存储中间张量,GPT-2-XL 的残差流张量(
[batch, seq_len, 1600])可能占用大量内存,尤其是长序列或大模型。 - 模型依赖:钩子点(如
hook_resid_pre)依赖transformer-lens的模型实现,其他框架可能需要重新定义。 - 复杂性:多层或多钩子干预可能增加代码复杂度,需仔细管理钩子注册和移除。
6. 实际应用中的注意事项
-
钩子名称:
- 确保钩子名称正确(如
blocks.{layer}.hook_resid_pre),可参考transformer-lens文档或打印模型结构确认。 - 其他钩子点(如
hook_attn_out)可用于不同干预实验。
- 确保钩子名称正确(如
-
张量维度:
- 引导向量和残差流的维度必须匹配,需处理提示长度不一致的情况(如
pad_prompts函数)。 ALIGNMENT_POS的选择影响干预范围,需与论文保持一致(a=1)。
- 引导向量和残差流的维度必须匹配,需处理提示长度不一致的情况(如
-
钩子管理:
- 每次前向传播后,及时移除钩子(
hook_handle.remove()),避免影响后续推理。 - 对于多线程或批量推理,需确保钩子线程安全。
- 每次前向传播后,及时移除钩子(
-
性能优化:
- 捕获激活值时,设置
model.zero_grad()和.detach()避免不必要的梯度计算。 - 对于大模型,考虑批量处理提示以减少内存占用。
- 捕获激活值时,设置
7. 扩展与未来探索
-
多层钩子:
- 尝试在多个层同时注入引导向量,探索更复杂的控制效果(论文未深入讨论)。
- 使用
transformer-lens的多钩子支持,注册多个hook_resid_pre。
-
其他钩子点:
- 干预注意力输出(
hook_attn_out)或前馈网络输出(hook_mlp_out),比较不同干预点的影响。
- 干预注意力输出(
-
可解释性分析:
- 使用钩子捕获干预前后的激活值分布,绘制论文 Figure 9 的 Q-Q 图,分析引导向量的语义作用。
-
自动化钩子管理:
- 开发工具自动注册和移除钩子,简化 ActAdd 的实现流程。
8. 结论
钩子是 ActAdd 方法实现的关键技术,通过 PyTorch 和 transformer-lens 提供的动态干预机制,实现了激活值的捕获和修改。捕获钩子用于计算引导向量,干预钩子用于在推理时注入引导向量,两者共同实现了对 Transformer 模型输出的精准控制。钩子的原理基于 PyTorch 的模块化设计和回调机制,结合 transformer-lens 的便捷接口,极大地简化了实现难度。
后记
2025年4月21日于上海,在grok 3大模型辅助下完成。