在人工智能领域,深度学习模型的创新推动着计算机视觉、自然语言处理等技术的跨越式发展。
本文聚焦 RNN、CNN、Transformer、BERT、GPT 五大经典模型,从技术特性、数据处理逻辑、应用场景及实践案例四个维度展开分析,揭示其在智能化时代的核心价值。
一、循环神经网络(RNN):时序数据的记忆大师
诞生时间:20 世纪 90 年代
技术内核:通过循环结构与记忆单元(如隐藏层状态传递)捕捉序列数据的时间依赖关系,允许信息在网络中持久流动。
数据专长:时间序列数据(如文本、语音、股票走势)。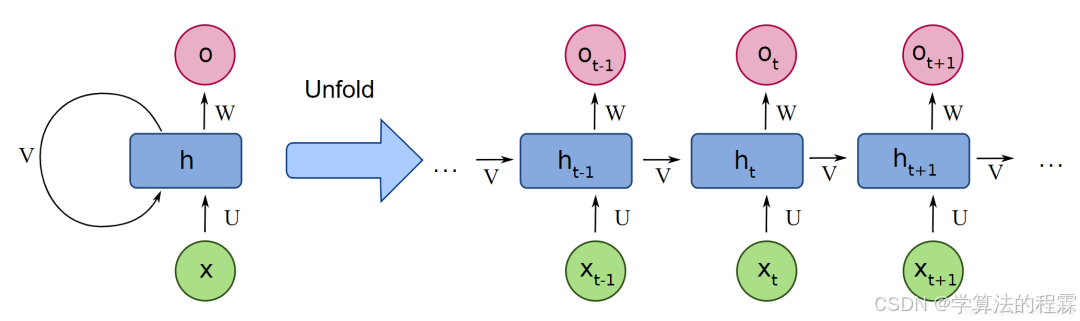
应用场景:
- 自然语言处理:机器翻译、情感分析(如基于 IMDB 影评的文本分类)。
- 语音识别:语音信号的时序特征建模。
- 预测任务:天气趋势、交通流量预测。
经典案例:基于 PyTorch 的 RNN 文本分类实现
# 核心逻辑:通过嵌入层将文本转为向量,利用RNN提取序列特征,全连接层完成分类
class RNN(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim) # 基础RNN层
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
embedded = self.embedding(text) # 词嵌入
output, hidden = self.rnn(embedded) # 输出序列与最后时刻隐藏状态
return self.fc(hidden.squeeze(0)) # 利用最后时刻状态完成分类 局限:长距离依赖问题显著(梯度消失 / 爆炸),衍生出 LSTM、GRU 等改进变体。
【戳下面的连接,即可跳转到小破站学习!】
神经网络算法模型学习教程![]() https://space.bilibili.com/3537111475030707
https://space.bilibili.com/3537111475030707
二、卷积神经网络(CNN):图像世界的特征捕手
发展阶段:20 世纪 90 年代末至 21 世纪初(LeNet 奠定基础,AlexNet 引爆计算机视觉革命)。
技术突破:
- 卷积层:通过滑动窗口(卷积核)提取局部空间特征,权值共享降低参数规模。
- 池化层:通过下采样(如最大池化)减少特征维度,增强平移不变性。
- 数据优势:二维网格数据(图像、视频帧)。
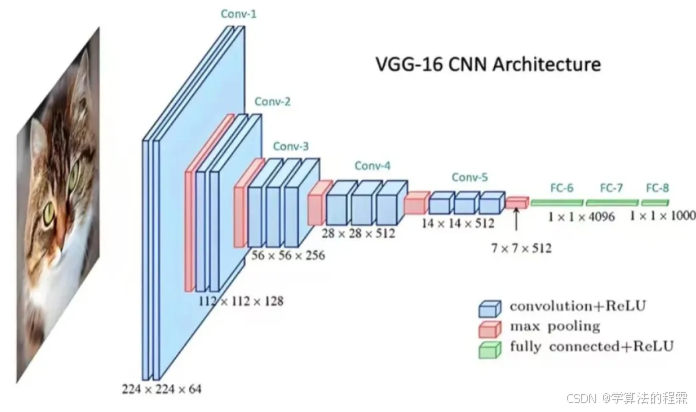
典型应用:
- 图像分类:ResNet 在 ImageNet 竞赛中的优异表现。
- 目标检测:YOLO 系列实现实时物体定位。
- 医学影像分析:CT 扫描中的肿瘤识别。
实践代码:Keras 实现猫狗图像分类
# 模型架构:多层卷积+池化提取特征,全连接层完成二分类
model = Sequential([
Conv2D(32, (3, 3), input_shape=input_shape, activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid') # 二分类输出
]) 延伸价值:跨领域迁移(如 NLP 中的 TextCNN 提取文本局部特征)。
三、Transformer:长序列处理的范式革新
诞生标志:2017 年论文《Attention Is All You Need》颠覆序列建模传统。
核心创新:
- 自注意力机制:通过 Query-Key-Value 计算动态权重,并行处理序列元素,解决 RNN 的时序依赖瓶颈。
- 多头注意力:分头计算不同子空间特征,提升模型表征能力。
-
位置编码:引入正弦 / 余弦信号赋予模型时序感知能力。
数据适配:长文本、跨语言序列(如机器翻译中的多语言对齐)。
应用领域:
- 自然语言处理:机器翻译(如 Google NMT)、文本摘要。
- 多模态任务:图文生成(如 GPT-4 的跨模态理解)。

代码示例:基于 Hugging Face 的 GPT-2 文本生成
# 核心流程:加载预训练模型,输入文本编码后生成续写内容
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-medium")
model = GPT2LMHeadModel.from_pretrained("gpt2-medium")
input_ids = tokenizer.encode("The quick brown fox", return_tensors="pt")
generated_ids = model.generate(input_ids, max_length=50)
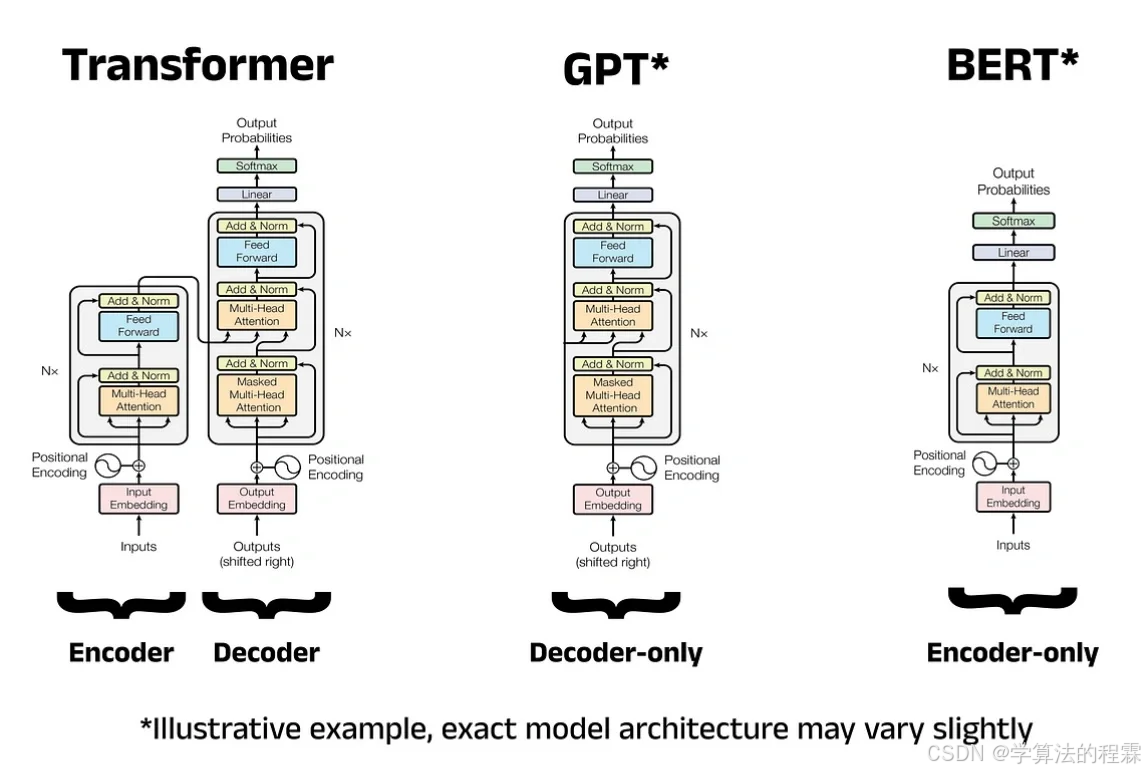
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True)) 技术影响:奠定大模型(如 BERT、GPT)的底层架构,推动 NLP 进入 “无递归” 时代。
四、BERT:双向理解的语言基石
发布时间:2018 年(Google)
技术亮点:
- 双向 Transformer 编码器:通过掩码语言模型(MLM)和下一句预测(NSP)任务,强制模型同时关注上下文信息。
- 预训练 - 微调范式:在海量文本(如 BooksCorpus、English Wikipedia)上预训练后,只需少量数据微调即可适配下游任务。
核心能力:深层语义理解(如句子相似度计算、命名实体识别)。
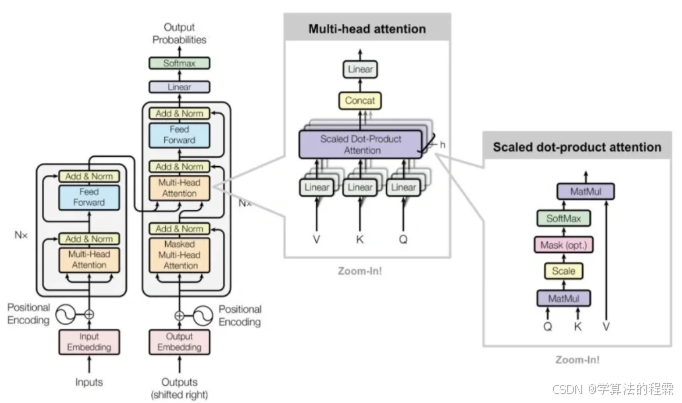
- 应用场景:
- 文本分类:新闻主题分类、垃圾邮件过滤。
- 情感分析:社交媒体评论的正向 / 负向判断。
- 问答系统:SQuAD 数据集上的抽取式问答。
实现示例:基于 BERT 的掩码词预测
# 任务:预测句子中[MASK]位置的词汇
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForMaskedLM.from_pretrained("bert-base-uncased")
sentence = "BERT is a [MASK] NLP model."
input_ids = tokenizer.encode(sentence, return_tensors="pt")
masked_pos = torch.where(input_ids == tokenizer.mask_token_id)[1]
outputs = model(input_ids)
pred_id = torch.argmax(outputs.logits[0, masked_pos]).item()
print(tokenizer.decode(pred_id)) # 输出:powerful 行业地位:被广泛用于构建企业级 NLP 中台,如智能客服、法律文书分析。
五、GPT:生成式 AI 的破局者
发展脉络:
2018 年 GPT-1(1.17 亿参数)开启预训练生成范式。
2020 年 GPT-3(1750 亿参数)实现零样本文本生成。
后续迭代(如 GPT-4)融合多模态能力,推动 AIGC 爆发。
技术特征:
- 单向 Transformer 解码器:仅使用自回归方式生成文本(从左到右逐词预测)。
- 海量数据训练:基于 Common Crawl 等超大规模语料库,学习人类语言分布规律。
核心应用:
- 内容创作:文案生成、小说续写、代码生成(如 GitHub Copilot)。
- 对话系统:ChatGPT 引领的交互式 AI 助手。
- 跨模态生成:文本转图像(如 DALL・E 系列)。
代码演示:GPT-2 生成科技类短文
context = "人工智能的发展正在重塑各个行业,"
input_ids = tokenizer.encode(context, return_tensors='pt')
output = model.generate(input_ids, max_length=100, temperature=0.7) # temperature控制生成随机性
print(tokenizer.decode(output[0], skip_special_tokens=True)) 六、模型对比与发展趋势
| 模型 | 核心结构 | 数据类型 | 典型任务 | 优势场景 |
| RNN | 循环层 + 记忆单元 | 时序序列 | 语音识别、时序预测 | 短序列依赖建模 |
| CNN | 卷积层 + 池化层 | 图像 / 网格数据 | 图像分类、目标检测 | 局部特征提取 |
| Transformer | 自注意力 + 编解码 | 长文本序列 | 机器翻译、文本生成 | 长距离依赖与并行计算 |
| BERT | 双向 Transformer 编码器 | 自然语言文本 | 语义理解、问答系统 | 上下文敏感型任务 |
| GPT | 单向 Transformer 编码器 | 自然语言文本 | 文本生成、对话系统 | 开放式内容创作 |
【戳下面的连接,即可跳转到小破站学习!】
未来趋势:
- 多模态融合:文本 - 图像 - 语音的统一建模(如 GPT-4V、CLIP)。
- 轻量化部署:模型压缩技术(量化、剪枝)推动边缘设备应用。
- 参数规模突破:万亿级参数模型探索更复杂的语义关联。
- 可控生成研究:通过提示工程(Prompt Engineering)精准引导输出方向。
结语
从 RNN 的时序记忆到 GPT 的生成革命,深度学习模型的演进始终围绕 “如何更高效地提取数据特征” 这一核心命题。
开发者可根据任务特性(如图像 vs 文本、理解 vs 生成)选择适配模型,同时关注 Transformer 架构的持续创新 —— 这一 “万能基底” 正不断突破模态边界,引领 AI 从 “专项智能” 迈向 “通用智能”。
未来,模型的性能提升将更多依赖数据质量、训练策略与工程优化的协同创新,为各行业智能化转型提供更强大的动力。
推荐up:coward咿呀咿
