在自然语言处理领域,Transformer 模型的出现堪称里程碑式突破。自 2017 年由 Google 在《Attention Is All You Need》中提出以来,它凭借全注意力机制架构,彻底改变了序列建模的范式。本文将深入解析其核心原理,并通过 PyTorch 代码实现关键模块,揭示这一 "最强模型" 的技术奥秘。
一、Transformer 的架构革新:告别递归与卷积
传统序列模型如 RNN 受限于时序依赖,无法并行计算;CNN 虽能局部特征提取,却难以建模长距离依赖。Transformer 另辟蹊径,采用编码器 - 解码器(Encoder-Decoder)架构,完全基于注意力机制实现:
并行处理能力:抛弃循环结构,所有序列元素可同时计算注意力权重,训练效率呈指数级提升。
长距离依赖捕捉:自注意力机制直接计算序列中任意位置的关联,彻底解决 RNN 的梯度消失问题。
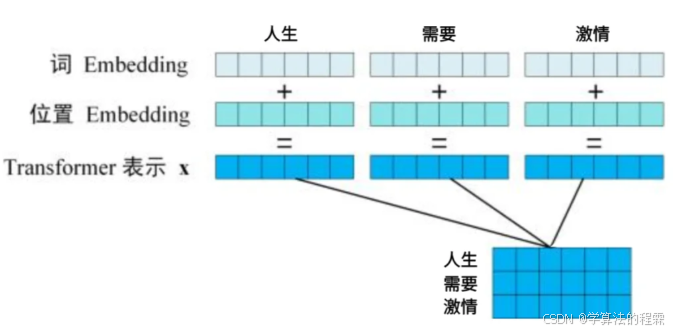
多模态扩展性:通过位置编码(Positional Encoding)赋予序列顺序信息,可无缝适配文本、语音等多类型数据。
戳下面链接,即可跳转到学习视频教程页面
核心组件解析
1. 编码器(Encoder)
结构:由 N 个相同层堆叠,每层包含:
自注意力层(Self-Attention):计算输入序列内部的注意力分布,输出上下文感知的特征表示。
前馈神经网络(FFN):对每个位置的特征进行非线性变换,公式为:
残差连接与层归一化:
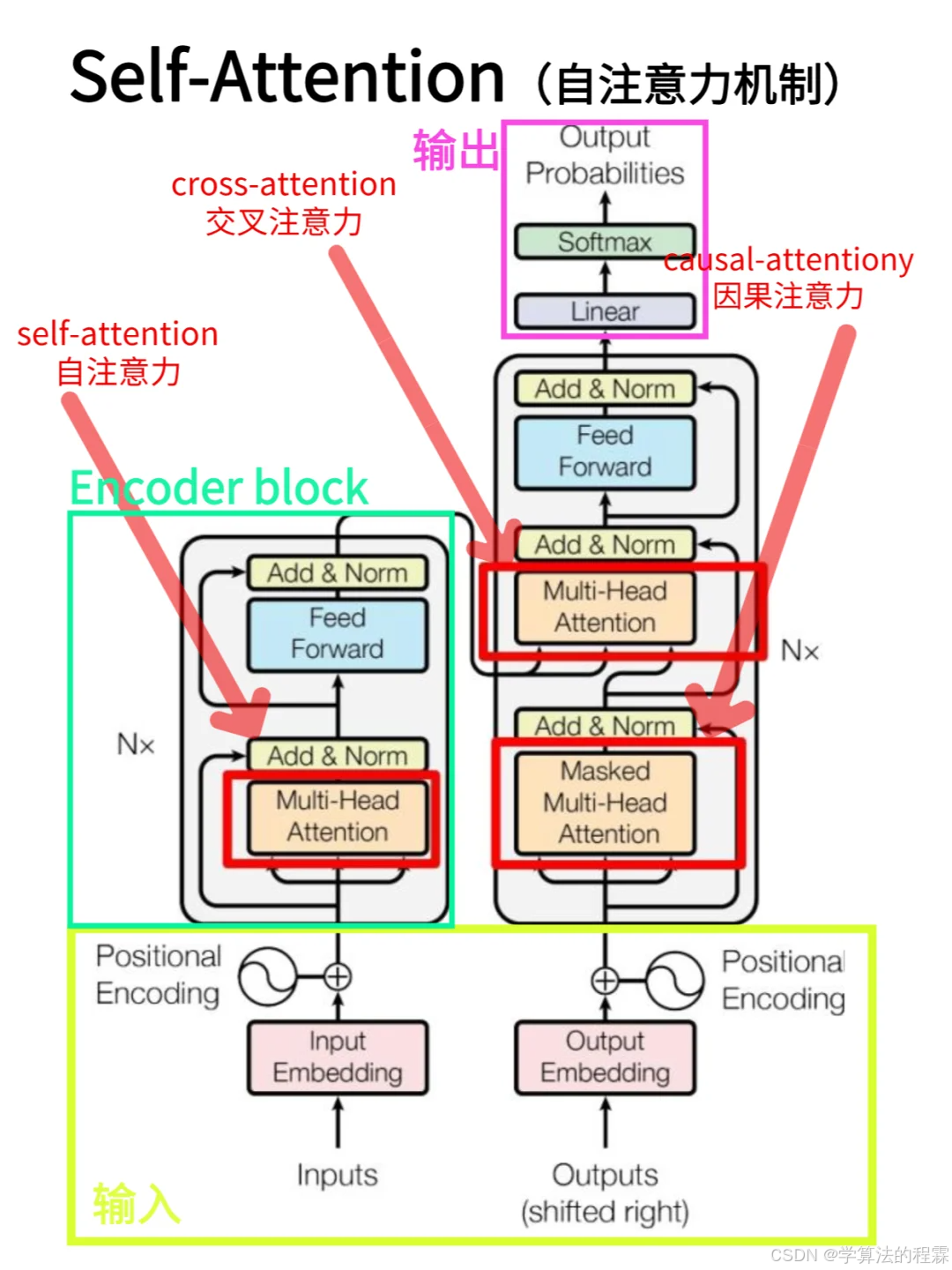
2. 解码器(Decoder)
- 结构:同样由 N 个层堆叠,每层新增编码器 - 解码器注意力层(Encoder-Decoder Attention),用于捕捉输入序列与输出序列的跨模态关联。其余组件与编码器类似,但在自注意力层引入前瞻掩码(Look-Ahead Mask),防止解码时偷窥未来信息。
二、自注意力机制:Transformer 的灵魂
自注意力机制通过 **Query-Key-Value(Q-K-V)** 三元组计算序列内元素的依赖关系,核心步骤如下:
1. 线性变换生成 Q/K/V
对于输入序列 ,通过三个可学习矩阵
生成查询、键、值:
2. 缩放点积注意力计算
注意力分数:, 除以
避免梯度消失。
掩码处理:通过添加极大负数掩码(如)屏蔽无效位置(如填充符或未来 tokens)。
加权求和:
3. 多头注意力(Multi-Head Attention)
将 Q/K/V 拆分为 h 个独立头,在不同子空间并行计算注意力,增强模型的表征能力:
三、PyTorch 代码实现:从模块到完整模型
以下是 Transformer 核心组件的代码实现,包含详细注释便于理解:
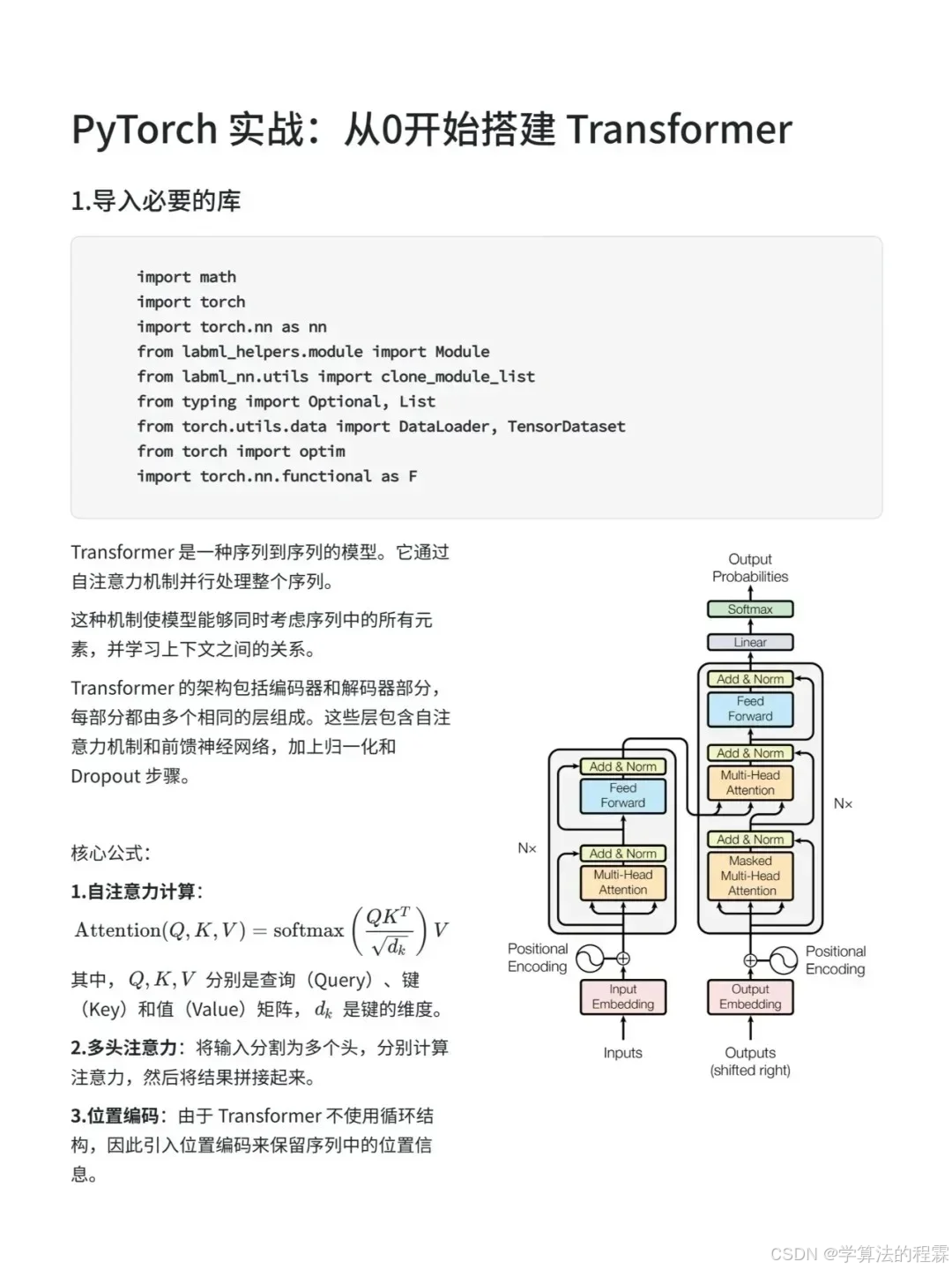
1. 多头注意力模块
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
self.depth = d_model // num_heads # 每个头的维度
# 线性层生成Q/K/V
self.WQ = nn.Linear(d_model, d_model)
self.WK = nn.Linear(d_model, d_model)
self.WV = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model) # 输出线性层
def split_heads(self, x, batch_size):
"""将输入拆分为多个头,形状从 [batch, seq_len, d_model] 变为 [batch, heads, seq_len, depth]"""
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.permute(0, 2, 1, 3) # 调整维度顺序
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 生成Q/K/V并拆分为头
q = self.split_heads(self.WQ(q), batch_size)
k = self.split_heads(self.WK(k), batch_size)
v = self.split_heads(self.WV(v), batch_size)
# 缩放点积注意力计算
attn_output, attn_weights = self.scaled_dot_product_attention(q, k, v, mask)
# 拼接多头结果并映射回d_model维度
attn_output = attn_output.permute(0, 2, 1, 3).contiguous()
concat_output = attn_output.view(batch_size, -1, self.d_model)
output = self.dense(concat_output)
return output, attn_weights
def scaled_dot_product_attention(self, q, k, v, mask=None):
matmul_qk = torch.matmul(q, k.transpose(-2, -1)) # [batch, heads, seq_len_q, seq_len_k]
dk = torch.tensor(k.size(-1), dtype=torch.float32)
scaled_logits = matmul_qk / torch.sqrt(dk) # 缩放点积
if mask is not None:
scaled_logits += (mask * -1e9) # 应用掩码
attn_weights = F.softmax(scaled_logits, dim=-1) # 归一化
output = torch.matmul(attn_weights, v) # 加权求和
return output, attn_weights2. 编码器层与完整 Transformer 模型
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model)
self.layernorm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(rate)
def forward(self, x, mask):
attn_output, _ = self.mha(x, x, x, mask) # 自注意力输入相同的Q/K/V
attn_output = self.dropout(attn_output)
out1 = self.layernorm1(x + attn_output) # 残差连接与层归一化
ffn_output = self.ffn(out1)
ffn_output = self.dropout(ffn_output)
out2 = self.layernorm2(out1 + ffn_output)
return out2
class Transformer(nn.Module):
def __init__(self, num_layers, d_model, num_heads, dff,
input_vocab_size, target_vocab_size, max_pos_encoding=5000):
super().__init__()
self.d_model = d_model
self.num_layers = num_layers
# 位置编码(简化实现,使用正弦余弦函数)
self.pos_encoding = positional_encoding(max_pos_encoding, d_model)
# 嵌入层与编码器/解码器
self.embedding = nn.Embedding(input_vocab_size, d_model)
self.encoder = nn.ModuleList([
EncoderLayer(d_model, num_heads, dff) for _ in range(num_layers)
])
self.final_layer = nn.Linear(d_model, target_vocab_size) # 输出层
def forward(self, inp, mask=None):
seq_len = inp.size(1)
# 嵌入层与位置编码相加
x = self.embedding(inp) * torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32))
x += self.pos_encoding[:, :seq_len, :]
# 多层编码器处理
for i in range(self.num_layers):
x = self.encoder[i](x, mask)
# 最终映射到词汇表
logits = self.final_layer(x)
return logits # [batch_size, seq_len, target_vocab_size]
# 位置编码函数(正弦余弦式)
def positional_encoding(max_len, d_model):
pos = torch.arange(max_len, dtype=torch.float32).unsqueeze(1) # [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe = torch.zeros(1, max_len, d_model)
pe[0, :, 0::2] = torch.sin(pos * div_term)
pe[0, :, 1::2] = torch.cos(pos * div_term)
return pe四、Transformer 的应用场景与技术影响
1. 核心应用领域
自然语言处理:
机器翻译(如 Google NMT)、文本生成(GPT 系列)、语义理解(BERT)。
典型案例:GPT-4 基于 Transformer 解码器实现万亿参数规模的生成能力。
计算机视觉:
ViT(Vision Transformer)将 Transformer 应用于图像分类,通过 Patch Embedding 将图像转为序列。
多模态任务:
图文生成(如 DALL・E)、语音识别(如 Speech Transformer)。
2. 技术演进与挑战
模型缩放定律:随着参数规模扩大(如 GPT-3 的 1750 亿参数),模型在少样本学习能力显著提升,但训练成本呈指数级增长。
轻量化改进:
蒸馏(Distillation):如 DistilBERT 压缩模型体积。
稀疏注意力(Sparse Attention):如 Longformer 仅计算局部窗口注意力,降低 O (n²) 复杂度。
训练效率优化:
混合精度训练、并行训练策略(数据并行 + 模型并行)缩短训练时间。
五、总结:Transformer 开启的智能时代
从最初的机器翻译到如今的多模态大模型,Transformer 凭借注意力机制的革命性创新,重新定义了深度学习的可能性。其核心价值不仅在于技术突破,更在于构建了一个通用的序列建模框架,使得跨领域迁移学习成为可能。未来,随着注意力机制的持续优化(如动态稀疏注意力、因果推理增强)和硬件加速技术的发展,Transformer 有望在自动驾驶、科学发现等更复杂场景中发挥关键作用,推动人工智能向通用化迈进。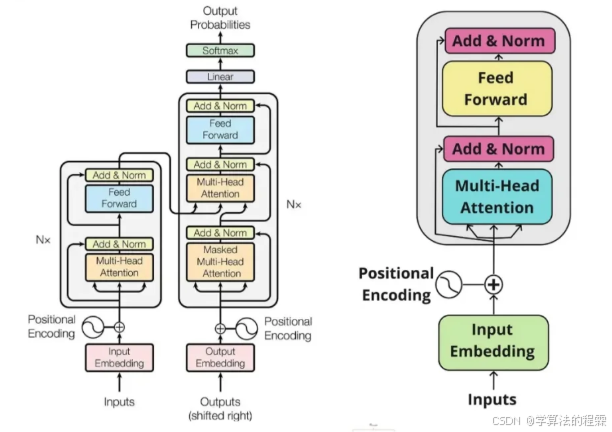
附:术语对照表
| 术语 | 含义描述 |
| Self-Attention | 自注意力机制,捕捉序列内部关联 |
| Multi-Head Attention | 多头注意力,分頭计算增强表征能力 |
| Positional Encoding | 位置编码,赋予模型序列顺序信息 |
| Layer Normalization | 层归一化,稳定网络训练 |
| Scaled Dot-Product | 缩放点积,避免注意力分数爆炸 |
戳下面链接,即可跳转到学习视频教程页面