目录

这篇文章共有 9 道题目,如果想看上的同学可以点下面这篇文章的链接:
(下文中的标题都是leedcode对应题目的链接)
39.组合总和

这一题其实就一个难点,就是某一个元素可以无限选择
由于我们可以无限选择,所以为了到达target,就必定会有像 233 和332的情况
但其实细看的话,我们就会发现,只要我们在选择当前元素的时候,我们不往前选择,其实就可以规避这种情况,所以我们就需要在每一次循环的时候,我们都从当前位置开始循环,这样就相当于,如果我是 2345,我这一次选择了2,那么下一次我从当前位置开始选择的话,就是可以选择 2345,有 2 是因为我们可以无限选择 2,如果是 3 的话,那就应该是 345,而不是2345
接下来的就是选择,然后递归下去,每递归一个就加在sum上(sum作为参数传递下去),最后当sum >= target 的时候,我们就直接返回
但是这里面,如果是相等的话,那么我们就需要将当前这种情况放进返回数组 ret 里面
最后就是在主函数返回 ret
代码如下:
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
void dfs(vector<int>& can, int tar, int sum, int pos)
{
if(sum >= tar)
{
if(sum == tar) ret.push_back(path);
return;
}
for(int i = pos; i < can.size(); i++)
{
path.push_back(can[i]);
dfs(can, tar, sum + can[i], i);
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target)
{
dfs(candidates, target, 0, 0);
return ret;
}
};784.字母大小写全排列

这一道题也是很简单的,就是当我们当前位置的元素为数字的时候,我们就直接continue,但是如果是字母的话,就小写一个递归,大写一个递归
至于怎么大小写,我们可以写一个函数专门来干这件事情,也就是,我们在递归调用函数的时候,我们就直接先将当前元素传进去,接着就传进这个小函数里面,如果我们传进去一个大写的话,那就返回一个小写,传进去一个小写的话就返回大写,如下:
char change(char ch)
{
if(ch <= 'z' && ch >= 'a')
ch -= 32;
else ch += 32;
return ch;
}
接着就是一直往下递归了
至于递归出口就是,我们用一个pos一直往下传,代表我们现在在遍历哪个位置,接着,当我们的 pos 位置等于数组大小的时候,我们就直接往全局数组 ret 里面插入当前的组合即可
ps:我们每遍历到一个位置,我们就将该位置的值放入全局的path数组当中,接着我们就是将这个path插入到ret里面
代码如下:
class Solution {
public:
vector<string> ret;
string path;
char change(char ch)
{
if(ch <= 'z' && ch >= 'a')
ch -= 32;
else ch += 32;
return ch;
}
void dfs(string s, int pos)
{
if(pos == s.size())
{
ret.push_back(path);
return;
}
path += s[pos];
dfs(s, pos + 1);
path.pop_back();
if(s[pos] < '0' || s[pos] > '9')
{
path += change(s[pos]);
dfs(s, pos + 1);
path.pop_back();
}
}
vector<string> letterCasePermutation(string s)
{
dfs(s, 0);
return ret;
}
};526.优美的排列

这道题目其实和上面大多数的题目都是差不多的,其实就是固定一个位置的数字,接着就是一个一个往下递归
但是还有一个剪枝的过程,就是当我们遍历到一个位置的时候,我们就看一下,如果这个数字满足
(i % pos == 0 || pos % i == 0)(也就是题目里的条件)
那么我们就允许这个数字进入递归逻辑
另外,递归函数里面,我们就是一个for循环遍历所有数,但是我们每遍历一个数,我们就需要标记一下这个数,表示我们之后的递归逻辑里面不能再出现这个位置的数,那么这个位置可以在全局建立一个check数组,然后改变这个位置的值就可以了
代码如下:
class Solution {
public:
vector<int> check;
int ret;
void dfs(int n, int pos)
{
if(pos == n + 1)
{
ret++;
return;
}
for(int i = 1; i <= n; i++)
{
if(check[i] == 0 && (i % pos == 0 || pos % i == 0))
{
check[i] = 1;
dfs(n, pos + 1);
check[i] = 0;
}
}
}
int countArrangement(int n)
{
check.resize(n+1);
dfs(n, 1);
return ret;
}
};51.N皇后
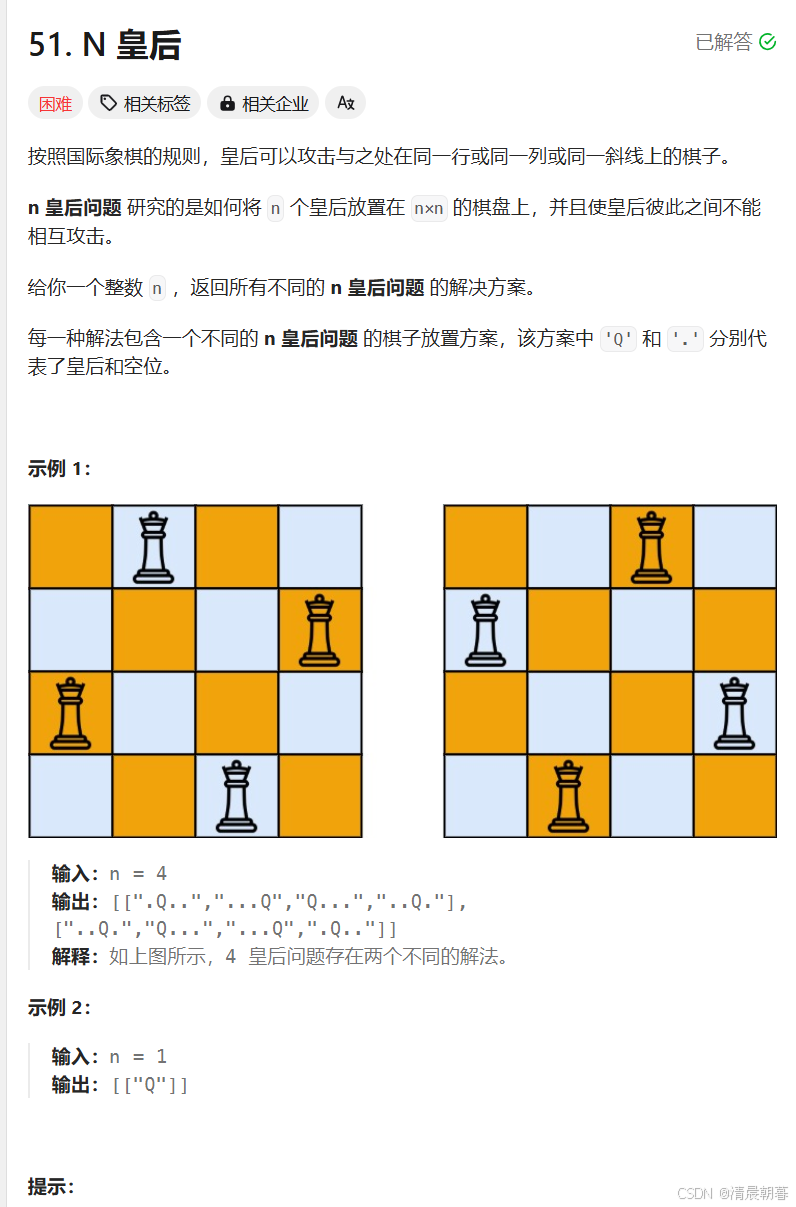
其实这道题目有两种做法,一种是靠暴力,还有一种就是数学
但是都可以过,只不过两种方法的时间复杂度天差地别
先来讲第一种
就是我们一次递归一列的情况,我们每遍历到一个位置的时候,我们就对着当前位置的左上到右下,左下到右上,还有就是从上到下,全部遍历一遍(前提是我们需要在全局建立一个棋盘,每到一个位置我们就将该位置变为‘Q’,接着就进入下一行的递归逻辑)
但是这样子的话,那就是每到一个位置,我们就全方位循环三次,判断有没有皇后在这些路径上,如果都没有的话,我们就可以将这个位置的数字放进去
然后来讲讲递归出口,由于我们是一列一列递归的,所以我们就需要放一个pos作为参数进递归逻辑里面,当我们的pos能到达最后一行的下一行位置的话,就代表我们有可以把皇后放满的情况,那就将那个棋盘放进全局的返回数组 ret 里面
最后在主函数里面,返回这个ret即可
但是最关键的就是我们如何四面八方的遍历看有没有皇后,这个要找点数学规律,这里我就不展示了,直接看代码把,因为我们有更好的办法
代码如下:
class Solution {
public:
vector<vector<string>> ret;
vector<string> path;
int n;
bool check(int i, int j)
{
for(int a = 0; a < n; a++)
if(path[a][j] == 'Q') return false;
int k = i, l = j;
if(i < j) k = 0, l = j - i;
else k = i - j, l = 0;
for(; k < n && l < n; k++, l++)
if(path[k][l] == 'Q') return false;
if(i + j <= n-1) k = i + j, l = 0;
else k = n - 1, l = (i + j) - (n - 1);
for(; k >= 0 && l <= n-1; k--, l++)
if(path[k][l] == 'Q') return false;
return true;
}
void dfs(int pos)
{
if(pos == n)
{
ret.push_back(path);
return;
}
for(int j = 0; j < n; j++)
{
if(check(pos, j))
{
path[pos][j] = 'Q';
dfs(pos + 1);
path[pos][j] = '.';
}
}
}
vector<vector<string>> solveNQueens(int _n)
{
n = _n;
path.resize(n);
for(int i = 0; i < n; i++)
path[i].append(n, '.');
dfs(0);
return ret;
}
};接着就是我们的第二种做法,这里就需要用到一些初中数学知识了,也就是斜率
首先我们可以用数组代替哈希表,也就是,我开一个大小为 n+1 的 bool 数组,这个数组就代表某一列有没有皇后
所以,当我们遍历到一个位置的时候,我们就不需要从头到尾遍历一遍了,我们只需要在这个数组里面看看,我们前面有没有在这一列上放过皇后即可
但是与此同时,我们还需要考虑一下该位置的两个斜对角线的方向
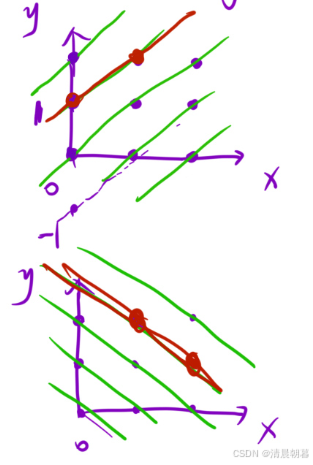
我们来看一下这张图片,我们还可以开两个大小为 2*n 的数组,表示我们在某一条斜线上面有没有皇后,当斜率为 1 的时候,就是 y = x + b,那么也就是 b = y - x,另一个就是 b = y + x
但是我们需要注意的一点就是,当我们 y = 0,并且 x 为最大值的时候,这时的结果就是负数且为最小的情况,所以我们还需要在结果上加上一个 n 以确保结果是一个正数且可以放在数组里面
这时,当我们走到一个位置的时候,如果要判断能否放在这个位置的时候,我们只需要在三个数组里面的当前位置看一看,是否为 false 即可,如果我们能放在这个位置的话,我们就分别在三个数组里面将这个位置的值从 false 改为 true 即可
其他的步骤基本都是差不多的,这里就不过多赘述了
代码如下:
class Solution {
public:
vector<vector<string>> ret;
vector<string> path;
int n;
vector<bool> r, d1, d2;
void dfs(int pos)
{
if(pos == n)
{
ret.push_back(path);
return;
}
for(int i = 0; i < n; i++)
{
if(!r[i] && !d1[pos - i + n] && !d2[pos + i])
{
path[pos][i] = 'Q';
r[i] = true, d1[pos - i + n] = true, d2[pos + i] = true;
dfs(pos + 1);
r[i] = false, d1[pos - i + n] = false, d2[pos + i] = false;
path[pos][i] = '.';
}
}
}
vector<vector<string>> solveNQueens(int _n)
{
n = _n;
path.resize(n);
for(int i = 0; i < n; i++)
path[i].append(n, '.');
r.resize(n), d1.resize(2 * n), d2.resize(2 * n);
dfs(0);
return ret;
}
};36.有效的数独

其实这一题放在回溯的章节里面并不合适,但是我们这里要介绍的是一种思想,因为我们下一道题目要讲的就是困难级别的 ”解数独“,至于这一题本身,其实更像一道哈希
首先要判断数独是否有效,我们只需要判断题目给的数组有没有问题就行了,所以我们就可以开辟三个数组:
bool row[9][10];
bool col[9][10];
bool cell[3][3][10];
因为我们数独的范围就是 1 ~ 9,所以我们开辟的前两个数组就代表,我们在数组中的某个位置有没有某个数,比如 row[3][6],就代表我们数组的第 4 个行里面有没有包含 6 这个数字
最后的 cell 数组,由于我们还需要判断 9 个小九宫格是否也包含了相同数字,所以我们可以开辟一个 3 * 3 的数组,如下:
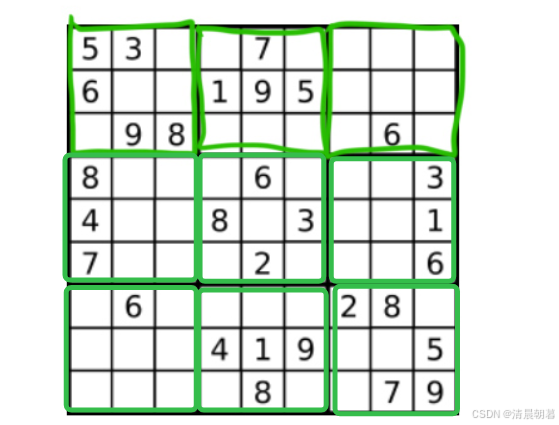
就是像这样的 3*3 的数组,而我们最后面的 10 个位置就是代表在这 3*3 的数组里面有没有1~9中的某个数
而我们要找下标也非常好找,直接 /3 即可
代码如下:
class Solution {
public:
bool row[9][10];
bool col[9][10];
bool cell[3][3][10];
bool isValidSudoku(vector<vector<char>>& board)
{
for(int i = 0; i < 9; i++)
for(int j = 0; j < 9; j++)
{
if(board[i][j] != '.')
{
int num = board[i][j] - '0';
if(row[i][num] || col[j][num] || cell[i / 3][j / 3][num])
return false;
row[i][num] = col[j][num] = cell[i / 3][j / 3][num] = true;
}
}
return true;
}
};37.解数独

大家在做这道题目之前,我们一定要看一下上一题的题解,因为这道题目和上一道是息息相关的
首先还是创建三个数组
bool row[9][10];
bool col[9][10];
bool cell[3][3][10];
而我们的递归逻辑就是,每当我们遍历到一个位置的时候,我们就先去这三个数组里面看一下,有没有包含对应的数,如果有的话我们就直接continue,如果没有我们就将某个数放进去,并将三个数组更新,最后进行下一层的递归逻辑
这一题到这里其实就已经讲完了,因为这和 N 皇后之后的逻辑并没有多大差别,都是暴力枚举所有情况,只不过因为有了剪枝所以排除了很多情况快了很多
代码如下:
class Solution {
public:
bool row[9][10];
bool col[9][10];
bool cell[3][3][10];
vector<vector<char>> ret;
bool dfs(vector<vector<char>>& b)
{
for(int i = 0; i < 9; i++)
for(int j = 0; j < 9; j++)
if(b[i][j] == '.')
{
for(int k = 1; k <= 9; k++)
{
int a = k + '0';
if(!row[i][k] && !col[j][k] && !cell[i / 3][j / 3][k])
{
b[i][j] = a;
row[i][k] = col[j][k] = cell[i / 3][j / 3][k] = true;
bool check = dfs(b);
if(check) return check;
else
{
b[i][j] = '.';
row[i][k] = col[j][k] = cell[i / 3][j / 3][k] = false;
}
}
}
return false;
}
return true;
}
void solveSudoku(vector<vector<char>>& board)
{
for(int i = 0; i < 9; i++)
for(int j = 0; j < 9; j++)
if(board[i][j] != '.')
{
int num = board[i][j] - '0';
row[i][num] = col[j][num] = cell[i / 3][j / 3][num] = true;
}
dfs(board);
}
};79.单词搜索
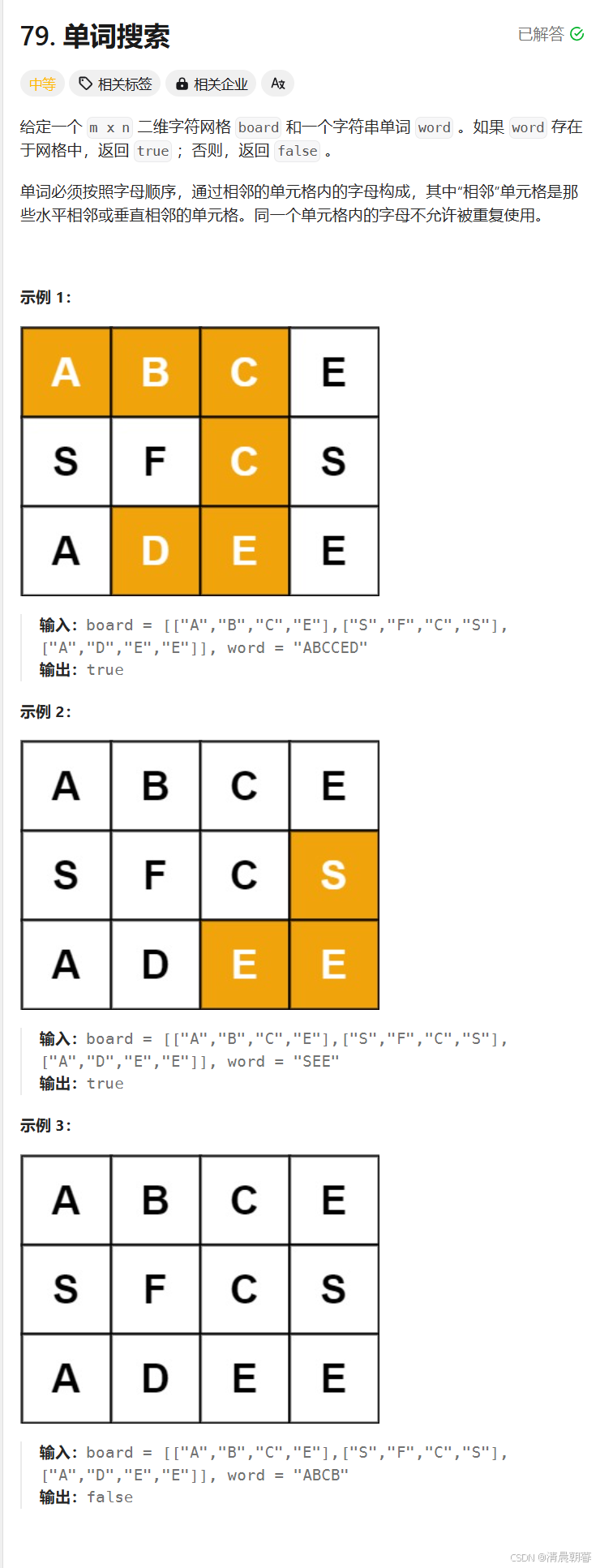
这道题目其实就是上下左右进行递归
首先给了我们一个单词,我们就可以将参数pos放进递归逻辑里面,pos 代表的就是我们现在遍历到了题目要我们找的单词的第几个位置了
而我们在主函数位置的时候,我们就直接进行一个for循环嵌套遍历整个数组,因为只有和开头的位置一样的才可以进入递归的逻辑
接着我们就是在递归中上下左右的找了,为了实现这个效果,我们可以写两个数组:
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
有了这个数组之后,我们就只用写一次for循环,让其循环四次就可以了,具体操作不明白的看代码就明白了,也就是让当前位置移动到上下左右四个位置分别进行递归
接着就是一个一个对比了,如果我们当前位置的值和pos位置的值不相同的话,那么我们就不能进入递归,就需要直接返回,也就是剪枝
最后就是递归出口,我们给dfs函数设置一个返回值,bool类型,只要pos位置到了最后一个的下一个的时候,就证明我们是能找得到的,所以我们就直接返回 true 即可,接着我们在递归的逻辑中也是,在递归之前就那一个 bool 变量接收返回值,接着就是判断返回的是true还是false,如果是true,那就直接返回true,因为这就说明在这个位置是能找得到的,false 的话我们就需要继续遍历下一个位置
代码如下:
class Solution {
public:
bool check[7][7];
string w;
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
bool dfs(vector<vector<char>>& b, int pos, int i, int j)
{
if(pos == w.size()) return true;
int n = b.size(), m = b[0].size();
for(int k = 0; k < 4; k++)
{
int x = i + dx[k], y = j + dy[k];
if(x >= 0 && x < n && y >= 0 && y < m && !check[x][y] && b[x][y] == w[pos])
{
check[x][y] = true;
if(dfs(b, pos + 1, x, y)) return true;
check[x][y] = false;
}
}
return false;
}
bool exist(vector<vector<char>>& board, string word)
{
w = word;
for(int i = 0; i < board.size(); i++)
for(int j = 0; j < board[i].size(); j++)
if(board[i][j] == word[0])
{
check[i][j] = true;
if(dfs(board, 1, i, j)) return true;
check[i][j] = false;
}
return false;
}
};1219.黄金矿工

这道题其实和上题基本一样,都是创建两个数组:
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
接着就是主函数里面一个for循环嵌套,从头到尾暴搜就是了,遇到 0 就跳过,否则就进去递归一下,找出所有情况的最大值即可
另外需要注意的就是,我们需要在递归逻辑中加上一个sum,代表我到了这个位置之后一路走来收集到的金块数量
最后全部创建一个变量 ret,每执行完一次上下左右递归的逻辑,就更新一下ret,这样我们就找出了所有情况中的最大值
代码如下:
class Solution {
public:
int n, m;
bool check[16][16];
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
int ret;
void dfs(vector<vector<int>>& grid, int i, int j, int sum)
{
for(int k = 0; k < 4; k++)
{
int x = i + dx[k], y = j + dy[k];
if(x >= 0 && x < n && y >= 0 && y < m && !check[x][y] && grid[x][y])
{
check[x][y] = true;
dfs(grid, x, y, sum + grid[x][y]);
check[x][y] = false;
}
}
ret = max(ret, sum);
}
int getMaximumGold(vector<vector<int>>& grid)
{
n = grid.size(), m = grid[0].size();
ret = 0;
for(int i = 0; i < n; i++)
{
for(int j = 0; j < m; j++)
{
if(grid[i][j] == 0) continue;
check[i][j] = true;
dfs(grid, i, j, grid[i][j]);
check[i][j] = false;
}
}
return ret;
}
};980.不同路径Ⅲ

这道题目看似是一道困难题,但其实我们在递归的时候会发现,这其实一点都不困难
首先题目要求的是,所有的空格子都需要包含到,所以我们可以提前先把所有空格子的数量统计好,最后我们在更新最后结果的时候,必然是当找到的长度为空格子的数量+2 时(并且最后一个数字必须为 2),才进行更新结果,+2 是因为还有开头和结尾
接着,我们就是从 1 位置开始,这点我们可以在遍历数组统计 0 的个数的时候顺便找到
然后就是递归逻辑了,我们还是上下左右找结果,当我们在找的时候,如果遇到了 -1,那说明遇到障碍了,那就不能进入递归逻辑,其他的都能进入
那么我们就只剩下三种情况了,第一种是,我们当前位置是 2 并且我们的长度是满足空格数量+2 的,那么就直接更新结果,同时continue
第二种就是位置是 2 但是长度不对的时候,就直接 continue 即可
最后的就是 0 的情况了,直接长度 +1 并进入下一次递归即可
到这里,这一题的代码逻辑就全部讲完了,总结一下这道题包括上面的很多道题,其实递归本身就是一种暴搜,只不过我们是在这个的基础上,不断地剪枝,也就是排除了很多情况,所以我们的时间才会快很多
代码如下:
class Solution {
public:
int ret;
bool check[21][21];
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
int zs, n, m;
void dfs(vector<vector<int>>& grid, int i, int j, int ps)
{
for(int k = 0; k < 4; k++)
{
int x = i + dx[k], y = j + dy[k];
if(x >= 0 && x < n && y >= 0 && y < m && !check[x][y] && grid[x][y] != -1)
{
if(grid[x][y] == 2 && ps + 1 == 2 + zs) ret++;
if(grid[x][y] == 2) continue;
check[x][y] = true;
dfs(grid, x, y, ps + 1);
check[x][y] = false;
}
}
}
int uniquePathsIII(vector<vector<int>>& grid)
{
n = grid.size(), m = grid[0].size(), zs = 0;
int begin_i, begin_j;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
{
if(grid[i][j] == 0) zs++;
if(grid[i][j] == 1) begin_i = i, begin_j = j;
}
check[begin_i][begin_j] = true;
dfs(grid, begin_i, begin_j, 1);
return ret;
}
};结语
这篇博客到这里就结束啦!!~( ̄▽ ̄)~*
如果觉得对你有帮助的,希望可以多多关注一下
另外,如果有有同学想看上一篇的话,可以点这个链接: